- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
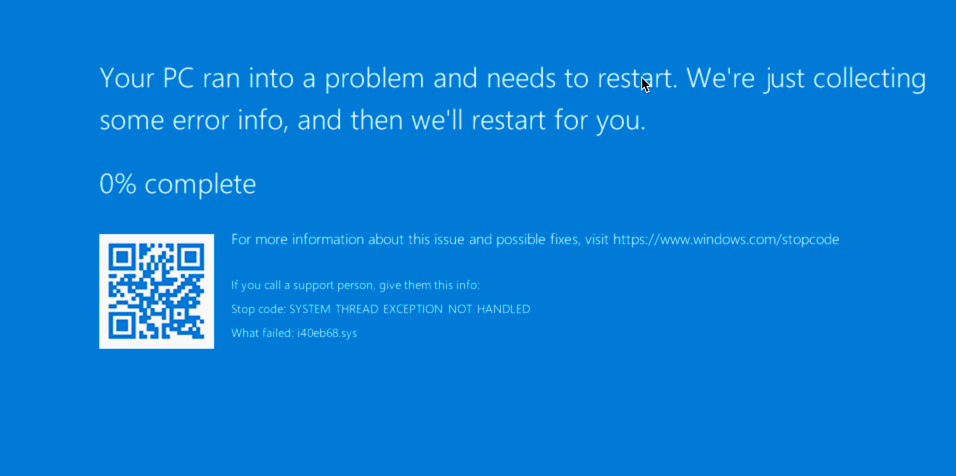
Periodic Bluescreens After Creating New SET Team Switch with Intel X722-DA2 NICs. Microsoft diagnosed the bugcheck as a problem with i40eb68.sys. I am running the latest driver release from Intel (23.5.2). iWARP Provider was also installed with the 23.5.2 installer (key use case for us) and all default NIC settings left as-is except that we enabled Jumbo Frames. The BSOD was happening on four identically configured cluster nodes. We tried disabling Jumbo Frames, but the BSODs continued even with the default NIC settings configured by the 23.5.2 installer.
We have tested an alternative NIC from Chelsio Networking with the exact same SET Team switching setup on the same servers, without these issues (which should rule out anything related to switching / server models / etc.).
I reverted Intel Driver from that which is installed with Version: 23.5.2 to the Microsoft Server 2019 natively included driver (1.8.103.2). With this change, BSOD *no longer occurred*. However, with this driver (1.8.103.2) we would see heavy hardware resets (1000+ per hour).
One of the hosts is using an X722-DA2 for iSCSI traffic (no SET Team Switch configured). We have not seen any issues with this configuration on either driver version.
It seems that when Intel X722 is added to a Microsoft SET Team switch, there are problems at the driver level (as diagnosed by Microsoft under a Support Case). Under older driver (1.8.103.2) this seems to manifest as near constant hardware resets. Under latest driver complete package installed by 23.5.2, this manifests as everything working seemingly perfectly (Production Traffic, Throughput Tests, Verified iWarp/RDMA working, etc.) *EXCEPT* Windows Server 2019 has a BSOD approximately every 60-120 minutes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
MikeL_Intel,
Unfortunately, these NICs are still in production servers so taking photos of NIC markings will not be able to be accomplished until at least May 18th. I am enclosing photos of the boxes, which contain significant information about the cards (Serial / Version / Date / Batch Numbers / etc.) in the cases related to this issue (04181222 and 04182853).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have a total of 5 cards. 4 of the cards were placed in this setup with SET teaming. All four then exhibited this BSOD behavior. The fifth is only used for iSCSI in one host and doesn’t seem to have an issue. As such, all of this points to driver issues (per Microsoft as well).
Will running the SSU cause any disruption to my production workloads?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello THigl,
SSU should not cause any disruption since it will just gather information about the system.
If you have questions, please let us know.
Best regards,
Michael L.
Intel Customer Support
Under Contract to Intel Corporation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For whatever reason, my original login will not allow me to get past the "Welcome to Support" page (no matter what I click, I end up back on that page despite being logged in). I've entered a new case for that, but am sharing to explain why this is a new account.
Here is the SSU run against one of the four host nodes. Please note that, as shared earlier, the current state is running on the older driver set (1.8.103.2) while the ultimate goal here is to make sure the latest drivers (23.5.2+) do not cause BSODs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
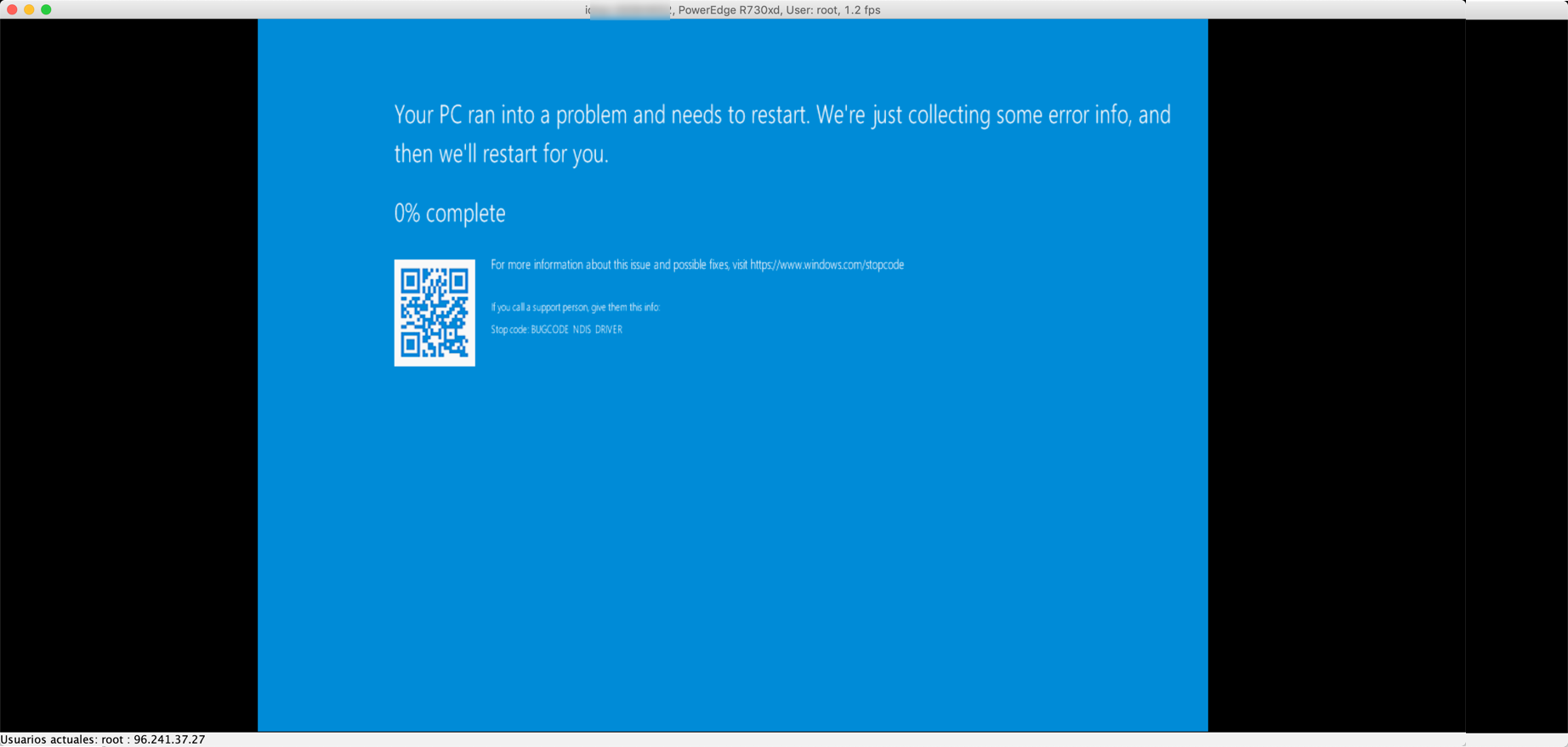
Hello. I have a similar problem with Intel(R) Ethernet Connection X722 for 10Gbe backplane on Lenovo ThinkSystem SN550. Did you find any solution for this problem ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have submitted several large groups of Crash Dumps, Event Logs, and SSUs to support. The last update was that they're working on the issue trying to reproduce and fix it. While I've followed up regularly, the communication has been okay at best.
In the meantime, Intel released OS Independent drivers v24 and NVM firmware v7 on their Download page. After applying driver v24, the BSOD episodes went down from about once every 2-4 hours to once every 9-10 days. I applied the NVMv7 firmware on two hosts just last evening (June 19th), so don't have any sense if the firmware will make much of a difference.
Meanwhile, I've kept two hosts back on the old drivers (which, unfortunately, don't support RDMA) included in Windows Server 2019. Not a single BSOD and its been over 45 days.
In short, the problem seems to have gotten much, much better in v24. However, seeing a BSOD every 9-10 days is still unacceptable. Hopefully, we'll see further progress out of Intel Support.
Please, if you're encountering this issue, submit a Support Ticket to Intel. I suggest collecting an SSU output (https://downloadcenter.intel.com/download/25293/Intel-System-Support-Utility-for-Windows-) and sending your Windows Crash Mini Dump.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok. Thank you for responce.
Bad news for me :) I have a large number of new servers with this NIC and will plan to use them with RDMA.
I'll follow you suggest and will submit Support request to Intel.
ty again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Absolutely! If you'd like to keep in touch about the issue and/or any progress that Intel makes with us, feel free to drop me an email (thigley [@] ette.biz).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By way of an update, this past weekend, we upgraded all hosts to v24 and NVM7 firmware. However, once we placed significant traffic onto the cards, the BSODs returned. At this point, we've disabled the cards entirely pending a fix.
We've tried following-up with Support, but all communication from Intel ceased as of June 13, 2019.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We've provided further information back and forth with Intel for a few more months, no real luck yet in resolving this issue for us. We've reverted to using old, non-RDMA Intel NICs for Storage Spaces Direct in the meantime.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am having the same issue with a new Lenovo SR550 server, that has dual X722 interfaces on the mainboard.
The latest drivers make no difference to stability. Under stress testing (Copying large VHDx over LAN) in a repeating loop, the system will predictably crash in 1-2 hours.
One thing I tried that is different to the original poster is that my tests were done with No Adapter Teaming configurations enabled.
This means the fault lies with either the X722 design, supporting chipset, firmware or drivers. Either way, the issue is 100% Intel's problem and they need to get on this and produce a solution.
I have also found the solution to be to disable the onboard NIC's and install a PCIE Broadcom NIC.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page