- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
I wish to get your kindly help on this basic question.
I find a nested loop in a paper as following: ("Model-Driven SIMD Code Generation for a Multi-Resolution Tensor Kernel")
for(int i = 0; i < LEN2; i++) {
for(int k = 0; k < LEN2; k++) {
for(int j = 0; j < LEN2; j++) {
cc
}
}
}
I modifed it as:
for(int i = 0; i < LEN2; i++) {
for(int k = 0; k < LEN2; k++) {
t = bb
for(int j = 0; j < LEN2; j++) {
cc
}
}
}
I use ICC to test these two pieces of code, I check execution time and the numbers of scalar and vector operations.
- The CPU is Intel(R) Xeon(R) CPU E5-2670 0 @ 2.60GHz
- The ICC version is icc (ICC) 12.1.5 20120612.
- OS: GNU/Linux
The output is:
Loop Time(Sec) Checksum
tensor_kernel 2.25 0.210001
PAPI_FP_OPS 8
PAPI_VEC_SP 26369718676
tensor_kernel 20.55 0.210001
PAPI_FP_OPS 9
PAPI_VEC_SP 26264735280
The execution time are quiet different: one is 2.x sec, the other is around 20 sec.
On the other hand, the PAPI result shows that the instruction numbers of scalar and vector instruction operations are similar. To comfirm the result from PAPI, I checked the .s code, and didn't find obviors difference. I dont understand what causes this execution time difference?
Code is as attached, it use the framework of TSVC. (By default the papi version will also be built, you could remove them from list.)
Thank you very much for reading this question.
Best Regards,
Susan
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you would give t local scope e.g.
for(int k = 0; k < LEN2; k++) {
float t = bb
...
the compiler would be freer to optimize. However, it still looks intended to prevent optimization of loop nesting (at least if you set -O3 -ansi-alias) so as to get unity stride inner loop. Then possibly you might also get automatic unroll and jam, so that perhaps only every other iteration on k writes back, if the optimized loop nesting didn't already accomplish that.
If you would compare the opt-report results, you might get a text indication about what optimization is suppressed by giving t scope outside the nested loops.
It would be better to write the loops with optimized nesting yourself before inserting a temporary which might block optimization.
I don't know whether papi allows you to distinguish between "simulated gather" where the compiler vectorized with scalar loads and stride 1 parallel data access; it would seem not.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tim,
Thank you very much for the reply.
I am still confused and need your further help. Since the assembly code of them have almost the same instruction sequence, I dont understand why the execution time is different. (BTW, I didnt see the multiple choice in .s code according to runtime condition.) PAPI use counters to get these numbers at runtime, these number look reasonable to me since there are same instruction sequence in .s file.
I tried the modification you mensioned, the performance get no abvious improvement.
Thank you again!
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TimP (Intel) wrote:
If you would give t local scope e.g.
for(int k = 0; k < LEN2; k++) {
float t = bb; ...
I would go even further, when I use this kind of nesting, I often do:
for(int k = 0; k < LEN2; k++) {
const float t = bb
to give compiler hint, that it should optimize it, since modification later is not possible.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much for further suggestion. I tried const, register, neither of them helps.
Seems from .s and the counter result I can tell no obvious difference, but exact execution time differ a lot, it is a little bit confusing...
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergey,
Thank you very much for your detailed reply. In the code I used __attribute__((aligned(x))) for allocating global arrays..
I have another question about alignment: I feel like icc could generate conditional code to do loop peeling for unaligned part, is that true?
BTW,Initializing variables for this case doesn't help obviously on performance.
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, in most cases where a loop is vectorizable but alignment is not assured, the compiler peels some iterations so as to begin the vectorized alignment at an aligned point in an array for which alignment is recognized as useful.
Peeling for alignment is not so important when dealing with 128-bit parallel instructions on core I7-2 or newer, as those CPUs have excellent support for unaligned 128-bit parallel access. So it is possible to see AVX-128 code which doesn't peel for alignment even though it supports mis-aligned data. That option is chosen more frequently by gcc than by icc.
The matrix operation case which you pose at the beginning of this thread raises additional issues with alignment. In order for __atttribute__((aligned())) to support inner vector loops without peeling for alignment, not only do the loops need to be nested appropriately, but the corresponding extents of the arrays must be multiples of 16 bytes (32 for AVX-256...)...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tim,
Thank you very much for the information.
"but the corresponding extents of the arrays must be multiples of 16 bytes (32 for AVX-256...)" I used 32 byte aligned allocation, the array size is multiple of 32 bytes. Did I miss anything or misunderstand your point?
Since the instruction related counter shows similar result, I will try to check the counter for L1/L2 by using PAPI later. Beside SIMD, I wish to check whether memory hierache is the reason.
Best Regards,
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergey,
Thank you very much.
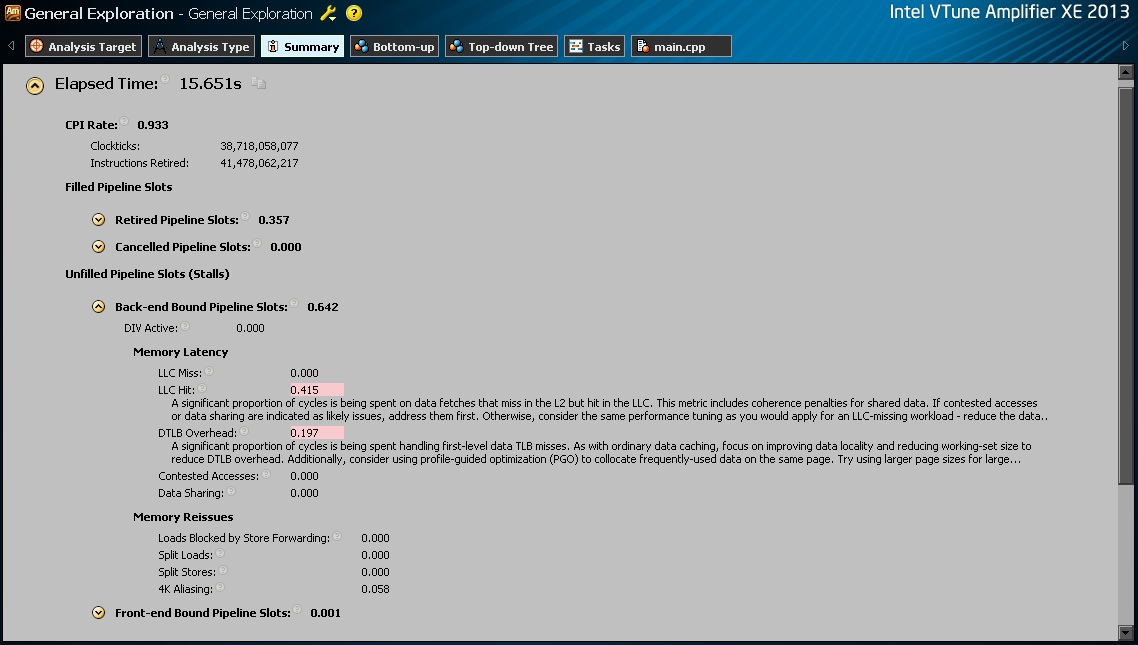
I got following result related to L1 and L2 cache: (L1 data miss: PAPI_L1_DCM; L1 instr miss: PAPI_L1_ICM; L2 data miss: PAPI_L2_DCM)
Loop Time(Sec) Checksum
tensor_kernel_1 2.22 0.210001
PAPI_FP_OPS 8
PAPI_VEC_SP 26351151240
PAPI_L1_DCM 953799685
PAPI_L1_ICM 788
PAPI_L2_DCM 120717240
tensor_kernel_2 19.44 0.210001
PAPI_FP_OPS 8
PAPI_VEC_SP 26288592672
PAPI_L1_DCM 13229545630
PAPI_L1_ICM 3169
PAPI_L2_DCM 7702311276
Seems that the L1 data miss got a great increase of 13.8x and it might be the reason. But I dont know why this happened, does it mean that whenever it execute t=bb[][], it will cause a L1 miss? I will try to modify this statement and have a look.
Susan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We've tried to explain how you've defeated compiler optimizations for data locality. It's interesting how your statistics show the effects of backward nested loops.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you all very much for your help and reply.
About the increase of L1/L2 miss, I still wish to get your opinion on following things:
In the code, LEN2=256
So for the innermost loop (cache line size 64B): LEN2*4B are W/R for cc array (one row); LEN2*64B are W/R for aa aray (totally Len2 cache line are read); totally: 256 * 4 + 256 * 64=17KB. Data L1 is 32KB, but I dont understand why this also cause L1/L2 miss increase obviously. I changed the LEN2 to 128, the L1 miss is still around get a increase of 15x, also exist L2 miss increase. If I did anything incorrect, please pardon me and do me a favor to correct me.
BTW, a personal feeling: for normal (not expert) programmer like me, I might think that it is good to have t=bb
I have an additional question, I know icc can recoganize typical routine of matrix multiply; can icc recogonize a typical 4x4 (or 8x8 for AVX) float point matrix transpose and use pack/unpack/shuffle to deal with that?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
When you force the compiler to follow the bad organization of loop nesting you quoted at the top of this thread, each element of aa[] comes from a different cache line, so you may expect to read the entire array each time through the inner loop. Your papi statistics appear to verify this.
The compiiler apparently vectorized the loop using "simulated gather," where the elements read separately each from a different cache line are packed into a vector register. Thus you execute roughly the same number of vector floating point operations as in the stride 1 vectorized case, but you replace the parallel reads from aa[] by scalar reads. You say you looked at the asm code; you would see the replacement of parallel data moves by groups of insertp instructions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergay, thank you very much for the useful and detailed info, i will try to implement one.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for reply, Tim.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content


{kind=link}
{kind=link}
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page