- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Experts in OpenMP and Intel C 14.x ,
Until version 13.x of Intel C I had the following code :
static int fobj_offset(int m, double *a, double *fun)
{
int n = npivot;
double *p = ppivot;
int i;
double cen[3*n];
double x=0.0,y=0.0,z=0.0;
double err=0.0;
Tool_Point_Offset[0] = a[0];
Tool_Point_Offset[1] = a[1];
Tool_Point_Offset[2] = a[2];
#pragma omp parallel for reduction(+ : x,y,z) num_threads (2)
for (i=0; i<n; i++)
{
ComputeToolPoint(&p[8*i+0], &p[8*i+3], &cen[3*i]);
x += cen[3*i + 0];
y += cen[3*i + 1];
z += cen[3*i + 2];
}
x = x/n;
y = y/n;
z = z/n;
--------------------------------
Every thing was fime. Tool_Point_Offset[] is a static (local) double array with 4 elements, only 3 are used. The values of Tool_Point_Offset are invariant for the whole for duration. The values of Tool_Point_Offset[] are used inside ComputeToolPoint(), but are not modified.
Starting with version 14.0.2.176 of the compiler I had to change into :
static int fobj_offset(int m, double *a, double *fun)
{
int n = npivot;
double *p = ppivot;
int i;
double cen[3*n];
double x=0.0,y=0.0,z=0.0;
double err=0.0;
#pragma omp parallel for reduction(+ : x,y,z) num_threads (2)
for (i=0; i<n; i++)
{
Tool_Point_Offset[0] = a[0];
Tool_Point_Offset[1] = a[1];
Tool_Point_Offset[2] = a[2];
ComputeToolPoint(&p[8*i+0], &p[8*i+3], &cen[3*i]);
x += cen[3*i + 0];
y += cen[3*i + 1];
z += cen[3*i + 2];
}
x = x/n;
y = y/n;
z = z/n;
-------
I do not understand why this is needed. I started thinking that Tool_Point_Offset was modified inside ComputeToolPoint(), not only used its values, by mistake. So I printed before and after the loop, but no, it is invariant.
The new arranged code is working fine again, but for me there is not need to move the Tool_Point_Offset initialization into the loop.
Please any clarification for me ? Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Armando,
Thanks for uploading the test case. I can reproduce the issue on any OS, but only with the IA-32 compiler; the x64 compiler works correctly on all platforms.
The defect is due loop distribution of the OpenMP parallel 'for' at line 407:
#pragma omp parallel for reduction(+ : x,y,z) num_threads (2)
for (i=0; i<n; i++)
{
ComputeToolPoint(&p[8*i+0], &p[8*i+3], &cen[3*i]);
x += cen[3*i + 0];
y += cen[3*i + 1];
z += cen[3*i + 2];
}
Besides the workaround you already noted (moving the initialisation of Tool_Point_Offset[] inside the parallel region), there are these:
1) Compile at -O1 (loop distribution only occurs at -O2 or higher)
2) Compile with an undocumented, unsupported internal switch which disables loop distribution: -mP2OPT_hlo_distribution=0
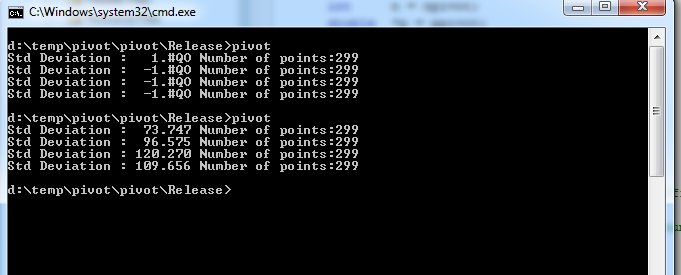
C:\ISN_Forums\U509232>icl /Qopenmp /Qstd=c99 -O3 pivot.C -mP2OPT_hlo_distribution=0
Intel(R) C++ Compiler XE for applications running on IA-32, Version 14.0.2.176 Build 20140130
Copyright (C) 1985-2014 Intel Corporation. All rights reserved.
C:\ISN_Forums\U509232>pivot.exe
Std Deviation : 73.747 Number of points:299
Std Deviation : 96.575 Number of points:299
Std Deviation : 120.270 Number of points:299
Std Deviation : 109.656 Number of points:299
C:\ISN_Forums\U509232>
Reported to compiler engineering, tracking ID DPD200255521 I'll keep this thread updated with news.
Patrick
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Armando,
>>>Starting with version 14.0.2.176 of the compiler I had to change
So what was the error symptom without the change? Was it a compilation failure? A link-time failure? A runtime error?
I suspect a runtime error -- if that is true, please add more detail (incorrect outputs, no outputs, executable crash).
Thank you,
Patrick
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Patrick,
It was a run-time error with incorrect output. I will try to create a simple test case and see if the compiler repeats these behavior.
I checked that the local static remains invariant during the whole loop execution. So I think that there is no need to assign the same values for every instance of the loop. The problem only happens if it is parallelized and only with version 14.x of the compiler.
Thanks for your attention.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Armando,
Thanks, that would be great if you could attach a small test case.
If array Tool_Point_Offset[] is declared outside of any parallel region, then any usage within parallel regions should refer to the same shared instance. It seems as if the compiler needs a reference within the static extent of the OpenMP parallel region to get the right answer, ie, it is not working correctly if the array is only accessed in the dynamic extent (in function ComputeToolPoint()).
Further, having to put the (identical) initialization of the array in a parallel region will hurt performance and probably create false positives for Inspector XE.
Patrick
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Patrick,
I could create a shorter version, unfortunately there are 453 lines of code. I had to include data for simulation of input from a stereo-camera and some supporting functions. C source code of the test case is attached.
Is it a Windows project. Follows the compiler and linker switches :
/c /O3 /Ob2 /Oi /Ot /Oy /Qip /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_MBCS" /MT /Zp1 /GS- /fp:fast /Fo"Release/" /Fd"Release/vc90.pdb" /W3 /nologo /Zi /TC /Qopenmp /QxSSE3 /Qstd=c99 /Qrestrict
If you remove the OpenMP parallelization of the for loop , there is no problem. If you copy the redundant initialization of Tool_Point_Offset into the for loop, the problem vanished. If you use a previous version of Intel Composer the problem is also gone.
Thanks you.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Armando,
Thanks for uploading the test case. I can reproduce the issue on any OS, but only with the IA-32 compiler; the x64 compiler works correctly on all platforms.
The defect is due loop distribution of the OpenMP parallel 'for' at line 407:
#pragma omp parallel for reduction(+ : x,y,z) num_threads (2)
for (i=0; i<n; i++)
{
ComputeToolPoint(&p[8*i+0], &p[8*i+3], &cen[3*i]);
x += cen[3*i + 0];
y += cen[3*i + 1];
z += cen[3*i + 2];
}
Besides the workaround you already noted (moving the initialisation of Tool_Point_Offset[] inside the parallel region), there are these:
1) Compile at -O1 (loop distribution only occurs at -O2 or higher)
2) Compile with an undocumented, unsupported internal switch which disables loop distribution: -mP2OPT_hlo_distribution=0
C:\ISN_Forums\U509232>icl /Qopenmp /Qstd=c99 -O3 pivot.C -mP2OPT_hlo_distribution=0
Intel(R) C++ Compiler XE for applications running on IA-32, Version 14.0.2.176 Build 20140130
Copyright (C) 1985-2014 Intel Corporation. All rights reserved.
C:\ISN_Forums\U509232>pivot.exe
Std Deviation : 73.747 Number of points:299
Std Deviation : 96.575 Number of points:299
Std Deviation : 120.270 Number of points:299
Std Deviation : 109.656 Number of points:299
C:\ISN_Forums\U509232>
Reported to compiler engineering, tracking ID DPD200255521 I'll keep this thread updated with news.
Patrick
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Patrick,
Thank you for your fast answer and clarification. I will evaluate which workaround has lower impact on the code.
Armando
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Patrick,
Do you know if this issue is solved in last update (3) ?
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No, the issue is not fixed in 14.0.3. It is still under investigation by the developers. I will let you know when a compiler with the fix is available.
Patrick
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page