- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
abdou06,
We have done some testing on our side, and it appears node49, the one you are using is having an issue. We did some testing on node46 and it was working fine. Please give that a shot and let me know if it works. I also have the developers looking at node49, to see what is going on.
Please let me know if you have any questions on this.
Thanks
Chris
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tried multiple nodes and it didn't work can you share the command used to run node46
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @abdou06
Chris and I tested using the following cells in a Jupyter Notebook. Please try to create an new Jupyter Notebook with the following cells and check the Job output/error files.
%%writefile test-pandas.py
import pandas as pd
print("Success!")
!pbsnodes | grep compnode | sort | uniq -c
%%writefile submit_job.sh
cd $PBS_O_WORKDIR
python3 test-pandas.py
print("Submitting a job to an edge compute node with an Intel Core CPU...")
#Submit job to the queue
job_id_core = !qsub submit_job.sh -l nodes=1:idc046
!qstat -l
Regards,
Jesus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
ok it work now,thank you
but i have a new problem if you can help me(note the: code run normarly in my juputer notebook)
this is the output of job
2021-10-27 10:35:04.939802: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/intel/openvino_2020.3.356/data_processing/dl_streamer/lib:/opt/intel/openvino_2020.3.356/data_processing/gstreamer/lib:/opt/intel/openvino_2020.3.356/opencv/lib:/opt/intel/openvino_2020.3.356/deployment_tools/ngraph/lib:/opt/intel/openvino_2020.3.356/deployment_tools/inference_engine/external/hddl/lib:/opt/intel/openvino_2020.3.356/deployment_tools/inference_engine/external/gna/lib:/opt/intel/openvino_2020.3.356/deployment_tools/inference_engine/external/mkltiny_lnx/lib:/opt/intel/openvino_2020.3.356/deployment_tools/inference_engine/external/tbb/lib:/opt/intel/openvino_2020.3.356/deployment_tools/inference_engine/lib/intel64:
2021-10-27 10:35:04.939839: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
Traceback (most recent call last):
File "ddsm-fe-densenet169.py", line 35, in <module>
import tensorflow as tf
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/__init__.py", line 41, in <module>
from tensorflow.python.tools import module_util as _module_util
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/__init__.py", line 46, in <module>
from tensorflow.python import data
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/data/__init__.py", line 25, in <module>
from tensorflow.python.data import experimental
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/data/experimental/__init__.py", line 130, in <module>
from tensorflow.python.data.experimental.ops.parsing_ops import parse_example_dataset
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/data/experimental/ops/parsing_ops.py", line 26, in <module>
from tensorflow.python.ops import parsing_ops
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/ops/parsing_ops.py", line 27, in <module>
from tensorflow.python.ops import parsing_config
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/ops/parsing_config.py", line 31, in <module>
from tensorflow.python.ops import sparse_ops
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/ops/sparse_ops.py", line 41, in <module>
from tensorflow.python.ops import special_math_ops
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/ops/special_math_ops.py", line 30, in <module>
import opt_einsum
ModuleNotFoundError: No module named 'opt_einsum'
kill: usage: kill [-s sigspec | -n signum | -sigspec] pid | jobspec ... or kill -l [sigspec]
and this is my code
#!/usr/bin/env python
# coding: utf-8
# In[2]:
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('../pfe'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# In[3]:
import numpy as np
import pandas as pd
import cv2
from PIL import Image
import scipy
import tensorflow as tf
from tensorflow.keras.applications import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.losses import *
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.callbacks import *
from tensorflow.keras.preprocessing.image import *
from tensorflow.keras.utils import *
# import pydot
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import *
from sklearn.model_selection import *
import tensorflow.keras.backend as K
from tqdm import tqdm, tqdm_notebook
from colorama import Fore
import json
import matplotlib.pyplot as plt
import seaborn as sns
from glob import glob
from skimage.io import *
get_ipython().run_line_magic('config', 'Completer.use_jedi = False')
import time
from sklearn.decomposition import PCA
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import lightgbm as lgb
from xgboost import XGBClassifier
from sklearn.ensemble import AdaBoostClassifier,RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
print("All modules have been imported")
# In[4]:
images=[]
labels=[]
feature_dictionary = {
'label': tf.io.FixedLenFeature([], tf.int64),
'label_normal': tf.io.FixedLenFeature([], tf.int64),
'image': tf.io.FixedLenFeature([], tf.string)
}
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.YlOrRd):
plt.figure(figsize = (6,6))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=90)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.
cm = np.round(cm,2)
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
# In[5]:
def _parse_function(example, feature_dictionary=feature_dictionary):
parsed_example = tf.io.parse_example(example, feature_dictionary)
return parsed_example
def read_data(filename):
full_dataset = tf.data.TFRecordDataset(filename,num_parallel_reads=tf.data.experimental.AUTOTUNE)
full_dataset = full_dataset.cache()
print("Size of Training Dataset: ", len(list(full_dataset)))
feature_dictionary = {
'label': tf.io.FixedLenFeature([], tf.int64),
'label_normal': tf.io.FixedLenFeature([], tf.int64),
'image': tf.io.FixedLenFeature([], tf.string)
}
full_dataset = full_dataset.map(_parse_function, num_parallel_calls=tf.data.experimental.AUTOTUNE)
print(full_dataset)
for image_features in full_dataset:
image = image_features['image'].numpy()
image = tf.io.decode_raw(image_features['image'], tf.uint8)
image = tf.reshape(image, [299, 299])
image=image.numpy()
image=cv2.resize(image,(100,100))
image=cv2.merge([image,image,image])
image
images.append(image)
labels.append(image_features['label_normal'].numpy())
# In[6]:
filenames=['../pfe/ddsm-mammography/training10_0/training10_0.tfrecords',
'../pfe/ddsm-mammography/training10_1/training10_1.tfrecords',
'../pfe/ddsm-mammography/training10_2/training10_2.tfrecords',
'../pfe/ddsm-mammography/training10_3/training10_3.tfrecords',
'../pfe/ddsm-mammography/training10_4/training10_4.tfrecords'
]
for file in filenames:
read_data(file)
print(len(images))
print(len(labels))
# In[7]:
X=np.array(images)
y=np.array(labels)
x_train, x_test1, y_train, y_test1 = train_test_split(X, y, test_size=0.3, random_state=42,
shuffle=True,stratify=y)
x_val, x_test, y_val, y_test = train_test_split(x_test1, y_test1, test_size=0.3, random_state=42,
shuffle=True,stratify=y_test1)
del X
del y
# In[8]:
#Defining our ANN Model
ann_model=Sequential()
ann_model.add(Dense(16, input_dim=128, kernel_initializer = 'uniform', activation = 'relu'))
ann_model.add(BatchNormalization())
#ann_model.add(Dropout( 0.2))
ann_model.add(Dense(32, kernel_initializer = 'uniform', activation = 'relu' ))
ann_model.add(BatchNormalization())
#ann_model.add(Dropout( 0.2))
ann_model.add(Dense(64, kernel_initializer = 'uniform', activation = 'relu' ))
ann_model.add(BatchNormalization())
#ann_model.add(Dropout( 0.2))
ann_model.add(Dense(32, kernel_initializer = 'uniform', activation = 'relu' ))
ann_model.add(BatchNormalization())
#ann_model.add(Dropout( 0.2))
ann_model.add(Dense(16, kernel_initializer = 'uniform', activation = 'relu' ))
ann_model.add(BatchNormalization())
#ann_model.add(Dropout( 0.2))
ann_model.add(Dense(1,activation='sigmoid'))
ann_model.summary()
# In[9]:
from sklearn.pipeline import make_pipeline
from sklearn.pipeline import Pipeline
names = [
"K Nearest Neighbour Classifier",
'SVM',
"Random Forest Classifier",
"AdaBoost Classifier",
"XGB Classifier",
]
classifiers = [
KNeighborsClassifier(),
SVC(),
RandomForestClassifier(),
AdaBoostClassifier(),
XGBClassifier(),
]
zipped_clf = zip(names,classifiers)
# In[10]:
def classifier_summary(pipeline, X_train, y_train, X_val, y_val,X_test,y_test):
sentiment_fit = pipeline.fit(X_train, y_train)
y_pred_train= sentiment_fit.predict(X_train)
y_pred_val = sentiment_fit.predict(X_val)
y_pred_test = sentiment_fit.predict(X_test)
train_accuracy = np.round(accuracy_score(y_train, y_pred_train),4)*100
train_precision = np.round(precision_score(y_train, y_pred_train, average='weighted'),4)
train_recall = np.round(recall_score(y_train, y_pred_train, average='weighted'),4)
train_F1 = np.round(f1_score(y_train, y_pred_train, average='weighted'),4)
train_kappa = np.round(cohen_kappa_score(y_train, y_pred_train),4)
val_accuracy = np.round(accuracy_score(y_val, y_pred_val),4)*100
val_precision = np.round(precision_score(y_val, y_pred_val, average='weighted'),4)
val_recall = np.round(recall_score(y_val, y_pred_val, average='weighted'),4)
val_F1 = np.round(f1_score(y_val, y_pred_val, average='weighted'),4)
val_kappa = np.round(cohen_kappa_score(y_val, y_pred_val),4)
test_accuracy = np.round(accuracy_score(y_test, y_pred_test),4)*100
test_precision = np.round(precision_score(y_test, y_pred_test, average='weighted'),2)
test_recall = np.round(recall_score(y_test, y_pred_test, average='weighted'),2)
test_F1 = np.round(f1_score(y_test, y_pred_test, average='weighted'),2)
test_kappa = np.round(cohen_kappa_score(y_test, y_pred_test),2)
print()
print('------------------------ Train Set Metrics------------------------')
print()
print("Accuracy core : {}%".format(train_accuracy))
cm=confusion_matrix(y_train,y_pred_train)
cm_plot=plot_confusion_matrix(cm,classes=['0','1'])
print('------------------------ Validation Set Metrics------------------------')
print()
print("Accuracy score : {}%".format(val_accuracy))
cm=confusion_matrix(y_val,y_pred_val)
cm_plot=plot_confusion_matrix(cm,classes=['0','1'])
print('------------------------ Test Set Metrics------------------------')
print()
print("Accuracy score : {}%".format(test_accuracy))
print("F1_score : {}".format(test_F1))
print("Kappa Score : {} ".format(test_kappa))
print("Recall score: {}".format(test_recall))
print("Precision score : {}".format(test_precision))
cm=confusion_matrix(y_test,y_pred_test)
cm_plot=plot_confusion_matrix(cm,classes=['0','1'])
print("-"*80)
print()
# In[11]:
def classifier_comparator(X_train,y_train,X_val,y_val,X_test,y_test,classifier=zipped_clf):
result = []
for n,c in classifier:
checker_pipeline = Pipeline([('Classifier', c)])
print("------------------------------Fitting {} on input_data-------------------------------- ".format(n))
#print(c)
classifier_summary(checker_pipeline,X_train, y_train, X_val, y_val,X_test,y_test)
# In[12]:
base_model= DenseNet169(input_shape=(100,100,3), weights='imagenet', include_top=False)
x = base_model.output
#x = Dropout(0.5)(x)
x = Flatten()(x)
x = BatchNormalization()(x)
# x = Dense(16,kernel_initializer='he_uniform')(x)
# x = BatchNormalization()(x)
# x = Activation('relu')(x)
# x = Dropout(0.5)(x)
predictions = Dense(128, activation='softmax')(x)
model_feat = Model(inputs=base_model.input,outputs=predictions)
train_features = model_feat.predict(x_train)
val_features=model_feat.predict(x_val)
test_features=model_feat.predict(x_test)
# In[13]:
classifier_comparator(train_features,y_train,val_features,y_val,test_features,y_test,classifier=zipped_clf)
# In[15]:
train_y=y_train
val_y=y_val
test_y=y_test
ann_model.compile(optimizer='adam',loss='binary_crossentropy', metrics=['accuracy'])
history = ann_model.fit(train_features, train_y,validation_data=(val_features,val_y), epochs=10,class_weight={0:0.4,1:0.7})
loss_value , accuracy = ann_model.evaluate(train_features, train_y)
print('Train_accuracy is:' + str(accuracy))
loss_value , accuracy = ann_model.evaluate(val_features, val_y)
print('Validation_accuracy is := ' + str(accuracy))
loss_value , accuracy = ann_model.evaluate(test_features, test_y)
print('test_accuracy is : = ' + str(accuracy))
print("Performance Report:")
y_pred1=(ann_model.predict(test_features) > 0.5).astype("int32")
target=["0","1"]
from sklearn import metrics
print('Accuracy score is :', np.round(metrics.accuracy_score(test_y, y_pred1),4))
print('Precision score is :', np.round(metrics.precision_score(test_y, y_pred1, average='weighted'),4))
print('Recall score is :', np.round(metrics.recall_score(test_y,y_pred1, average='weighted'),4))
print('F1 Score is :', np.round(metrics.f1_score(test_y, y_pred1, average='weighted'),4))
print('ROC AUC Score is :', np.round(metrics.roc_auc_score(test_y, y_pred1,multi_class='ovo', average='weighted'),4))
print('Cohen Kappa Score:', np.round(metrics.cohen_kappa_score(test_y, y_pred1),4))
print('\t\tClassification Report:\n', metrics.classification_report(test_y, y_pred1,target_names=target))
# In[ ]:
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi @abdou06
Looks like an error when trying to import Tensorflow (Line 35). Could you try to import tensorflow with the steps in my previous response? Also what kernel and node are you using to submit your code?
You can find the kernel version on the top right corner in your Jupyter notebook. It will say something like Python (OpenVINO 2021.4.1).
%%writefile test-pandas.py
import tensorflow as tf
print("Success!")
Regards,
Jesus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
abdou06,
Are you using CUDA? Are you trying to run your code on GPU?
Thanks,
Raad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
if you read my code tell me what I need to run it in node step by step please
note: there is no errors in code it run in jupyter notebook fine
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Abdou06,
I will take a look at your code.
Regards,
Raad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

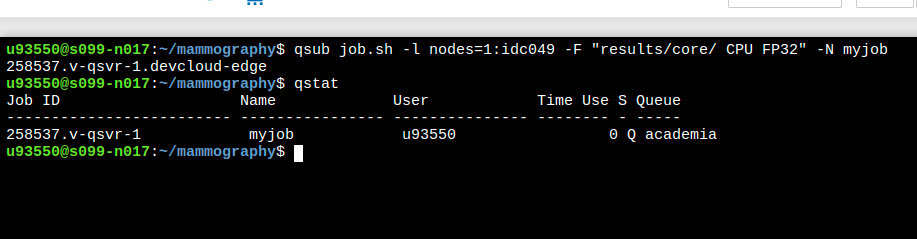{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I use OpenVINO 2021.4.1 in my jupyter notebook and it work fine
the problem is in job
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Abdou06,
In order to troubleshoot your code I will need all the files, for example:
filenames=['../pfe/ddsm-mammography/training10_0/training10_0.tfrecords',
'../pfe/ddsm-mammography/training10_1/training10_1.tfrecords',
'../pfe/ddsm-mammography/training10_2/training10_2.tfrecords',
'../pfe/ddsm-mammography/training10_3/training10_3.tfrecords',
'../pfe/ddsm-mammography/training10_4/training10_4.tfrecords'
]
I understand that your code works fine in Jupyter notebook but it fails when you submit it to a node.
Thanks,
Raad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
so what i should do exactly
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Abdou06,
Please change the first line in your code from:
#!/usr/bin/env python
To
#!/usr/bin/env python3
And give it a try.
Regards,
Raad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
this the output code
so how to define the data path for the job or save the problem
2021-10-29 13:13:45.008777: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/opt/intel/openvino_2021.4.689/python/python3/cv2/../../../opencv/bin:/opt/intel/openvino/data_processing/dl_streamer/lib:/opt/intel/openvino/data_processing/gstreamer/lib:/opt/intel/openvino/opencv/lib:/opt/intel/openvino/deployment_tools/ngraph/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/tbb/lib::/opt/intel/openvino/deployment_tools/inference_engine/external/hddl/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/omp/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/gna/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/mkltiny_lnx/lib:/opt/intel/openvino/deployment_tools/inference_engine/lib/intel64
2021-10-29 13:13:45.008860: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2021-10-29 13:14:01.895176: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: :/opt/intel/openvino_2021.4.689/python/python3/cv2/../../../opencv/bin:/opt/intel/openvino/data_processing/dl_streamer/lib:/opt/intel/openvino/data_processing/gstreamer/lib:/opt/intel/openvino/opencv/lib:/opt/intel/openvino/deployment_tools/ngraph/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/tbb/lib::/opt/intel/openvino/deployment_tools/inference_engine/external/hddl/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/omp/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/gna/lib:/opt/intel/openvino/deployment_tools/inference_engine/external/mkltiny_lnx/lib:/opt/intel/openvino/deployment_tools/inference_engine/lib/intel64
2021-10-29 13:14:01.895241: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2021-10-29 13:14:01.895291: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (s001-n001): /proc/driver/nvidia/version does not exist
2021-10-29 13:14:01.895929: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-10-29 13:14:02.020596: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Traceback (most recent call last):
File "ddsm-fe-densenet169.py", line 149, in <module>
read_data(file)
File "ddsm-fe-densenet169.py", line 116, in read_data
print("Size of Training Dataset: ", len(list(full_dataset)))
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/data/ops/iterator_ops.py", line 761, in __next__
return self._next_internal()
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/data/ops/iterator_ops.py", line 747, in _next_internal
output_shapes=self._flat_output_shapes)
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/ops/gen_dataset_ops.py", line 2728, in iterator_get_next
_ops.raise_from_not_ok_status(e, name)
File "/home/u93550/.local/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 6941, in raise_from_not_ok_status
six.raise_from(core._status_to_exception(e.code, message), None)
File "<string>", line 3, in raise_from
tensorflow.python.framework.errors_impl.NotFoundError: ../pfe/ddsm-mammography/training10_0/training10_0.tfrecords; No such file or directory [Op:IteratorGetNext]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi abdou06,
I would need your entire project directory to reproduce the issue. Could you compress and send me the content of your project directory including ipynb file, python code and input images/data.
Please let me know if you would like to share this privately and I will send you a private message.
Regards,
Jesus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes , I can give me your email
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just sent you an email, please check your inbox.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi abdou06,
I haven't seen a response to my email and this discussion is marked as closed. Did you resolve your issue?
Regards,
Jesus
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page