- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm using IPP 7.0 on win7 x64 bit. I found a problem about IppiConvValid_32f_C1R.
That's I get different results on two computers by this function.
So I want to see the detailed explanation about DPD200259470 on https://software.intel.com/en-us/articles/intel-ipp-70-library-bug-fixes/
to check whether the bug is the same as me.
Thank u.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, my mistake, both support AVX - therefore the same code version works for both. IPP code has different optimized code for different CPUs. The optimal one is dispatched automatically for dynamic libraries, for static libraries you should call ippInit() function before any other call to IPP functions. It is not clear from your code example which kind of linking you use - but I don't see ippInit() call. Almost all IPP functions have internally different code branches for different combinations of source and destination buffers alignment. Therefore my next supposition is that as you have not made any special efforts on the source/destination buffers alignment - on different machines you face with differently aligned buffers, and therefore - with different code branches in IPP functions. Use ippMalloc() to have the same and the best alignment (32-byte in your particular case) for memory buffers. Also there are single and multi-threaded versions of IPP libraries - for larger sizes you can face with the same output difference because of the different number of threads (and therefore different internal data decomposition) - one of your CPUs supports 4 hw threads while another one - 8.
regards, Igor
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Teng,
Here it is:
"The code ( attached main.c, wrapper.asm ) shows the problem with ippiConvValid_32f_C1R routines with 64 bit code linked.
accordingly specification,
all registeres XMM6:XMM15 Nonvolatile Must be preserved as needed by callee.
but they don't preserved and are mofigying during the ippiConvValid call.
the expected and actuals outputs were provided into main.c file
=== The register value is broken ==="
regards, Igor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
thanks for your quickly reply.
I'm not sure the relationship between my problem and DPD200259470.
The attched file is my code and testdata.
The ConvValid_0.raw is the input file and the two ConvValid_1_*.raw are the result of my computer and another server computer.
There are differences between two result files.
The test environment as follows:
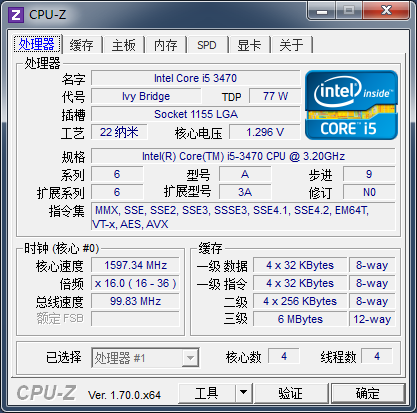
my Computer:
Intel(R) Core(TM) i5-3470 CPU @3.2GHz
memory:8G
win7 x64 bit professional
Server Computer:
Intel(R) Core(TM) i7-3820 CPU @3.6GHz
memory:16G
win7 x64 bit professional
please check it , thank u.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Teng,
why do you think that the difference in 1-2 least significant bits is a bug? You have different CPUs - one supports SSE4 only while the other one supports AVX - therefore the different versions of optimized code are working. 32f code can't be compared bit-to-bit - it should be compared with some reasonable epsilon that depends on the number of arithmetic operation per one output point (that is huge for cross-corr). The different order of calculations will always lead to the different results for floating point functions/calculations.
regards, Igor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok, my mistake, both support AVX - therefore the same code version works for both. IPP code has different optimized code for different CPUs. The optimal one is dispatched automatically for dynamic libraries, for static libraries you should call ippInit() function before any other call to IPP functions. It is not clear from your code example which kind of linking you use - but I don't see ippInit() call. Almost all IPP functions have internally different code branches for different combinations of source and destination buffers alignment. Therefore my next supposition is that as you have not made any special efforts on the source/destination buffers alignment - on different machines you face with differently aligned buffers, and therefore - with different code branches in IPP functions. Use ippMalloc() to have the same and the best alignment (32-byte in your particular case) for memory buffers. Also there are single and multi-threaded versions of IPP libraries - for larger sizes you can face with the same output difference because of the different number of threads (and therefore different internal data decomposition) - one of your CPUs supports 4 hw threads while another one - 8.
regards, Igor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have got it, thank u.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Astakhov,
I have another issue to consult with u.
Does the ipp functions such as ippiConvValid_32f_C1R or ippiFilter_ optimized by multithread?
Or the function only optimized by C code and Instruction Set for exmaple SSE AVX?
Thank u.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page