- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
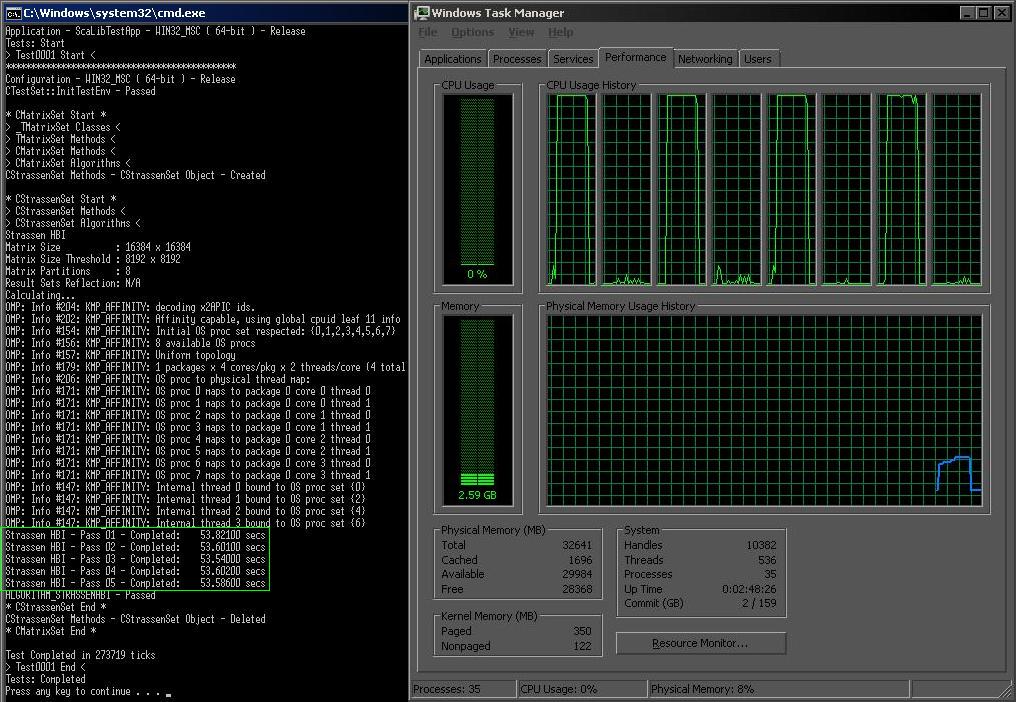
HPC and Magic of OpenMP thread Affinity Management: Compare performance of matrix multiply when Thread Affinity is Not Used and Used...
Two screenshots are attached for your review.
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergey, I believe this might be better addressed in one of our compiler forums, as this appears to be specific to OpenMP. Which language are you using in your code, and I can transfer this thread to the correct forum.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I see that you thoroughly optimized your Dell Workstation by disabling fancy UI.
Regarding that your test I suppose that keeping core affinity pinned to specific threads helped to increase performance. I suppose that main reason for that could be related to retaining fresh data in each core cache to which specific HW thread is pinned.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Despite decades of research and bazillions of hours of development work on run-time scheduling, I have never seen an OS that actually handles thread scheduling "properly" on multiprocessor systems.
In this case it looks like your hardware supports HyperThreading, and your results with affinity set show stable performance with the four threads bound to the even-numbered logical processors.
When affinity is not set, the combination of language runtime and OS place (for most of the run) one thread on core 0, two on core 1, one on core 2, and none on core 3. The contention for resources on the overloaded core leads to runtime increases of about 32% to about 43%. This is better than it might have been, and may be due to migrating threads on and off of the overloaded core -- the bulk utilization charts don't tell us whether the threads are staying in one place or are bouncing around among the logical processors in use.
This phenomenon is certainly not unique to Windows -- I see it all the time on Linux systems. You don't need HyperThreading to see the same sorts of troubles -- in one recent tutorial example, I showed that running STREAM with 16 OpenMP threads (on a 16-core node) without process binding resulted in an average CPU utilization of about 13.5 cores and a performance hit of 30%-40%.
I don't know if the IA32_TSC_AUX register is set up properly on recent Windows systems, but on Linux systems this MSR is configured to provide both the socket (placed in bits 23:12) and the logical processor number (placed in bits 11:0). The contents of this MSR are returned in the %ecx register when the RDTSCP instruction is executed. This is a very nice way to determine which core a process is running on without doing anything that might cause the OS to move the process (such as making a system call).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>>and none on core 3.>>>
@John
Could the reason for such a scheduler policy be related to keeping core 3 available for the "housekeeping" tasks like execution of ISR/DPC routines and running higher priority system threads?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is very hard to tell why the Linux scheduler makes the decisions that it makes. One of the primary benefits of HyperThreading is that it allows OS processes to run concurrently with user processes -- only sharing issue slots and cache space instead of completely halting the user process while the OS service runs.
In any case there can be no "right answer" to thread scheduling in general -- some multithreaded jobs want to be "gang scheduled" and spread across all available cores, while other multithreaded jobs create extra worker threads for load balancing and don't suffer if these threads are not assigned to a core at all times, and still other multithreaded jobs may benefit from the very tight coupling available from running two threads on a single physical core.
If you know anything about the characteristics of your job (and the environment in which it runs), using the KMP_AFFINITY environment variable (and other features) can significantly improve system throughput and avoid irritating "performance mistakes".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I try to use affinity settings in order to have thread "fresh" data as long as possible, but I am aware that otherHT thread may invalidate part of the cache lines which are not frequently used.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page