- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
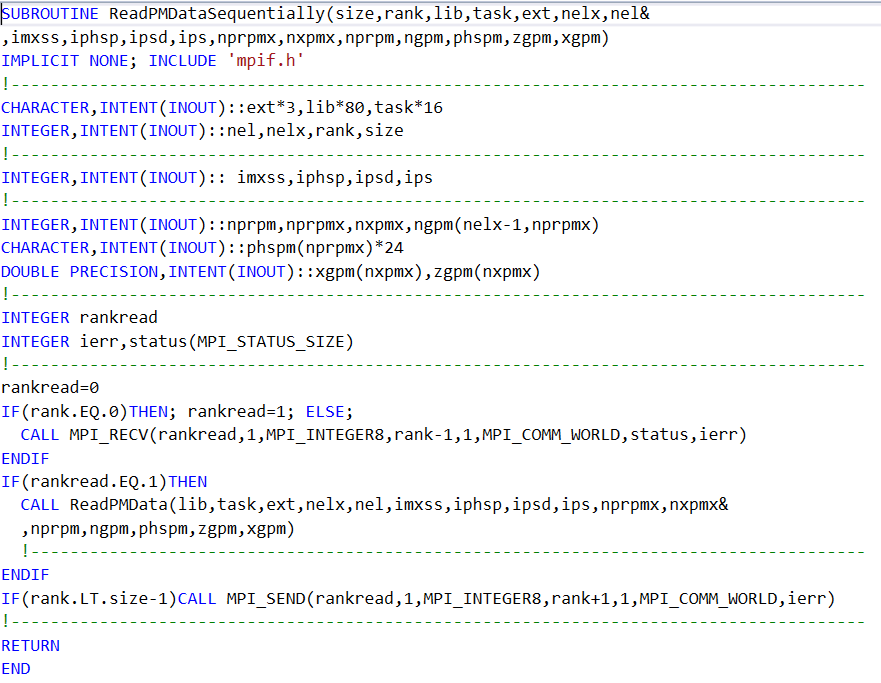
I have been using MPI succesfully without splitting the group of threads into subgroups. Reading and writing of files have been handled by
a subroutine that allows serial access to the hard disk by the threads (see attached subroutine).
However, as I have an excess of threads for my application, I therefore want to use subgroups by use of MPI_GROUP_SPLIT. in order
to get an additional speed increase. Can my treatment in the attached subroutine be generalized in some way in order to handle disk access?
Best regards
Anders S
- Tags:
- Cluster Computing
- General Support
- Intel® Cluster Ready
- Message Passing Interface (MPI)
- Parallel Computing
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Can you please provide details on how you are reading and writing into files. And how many subgroups are you expecting.
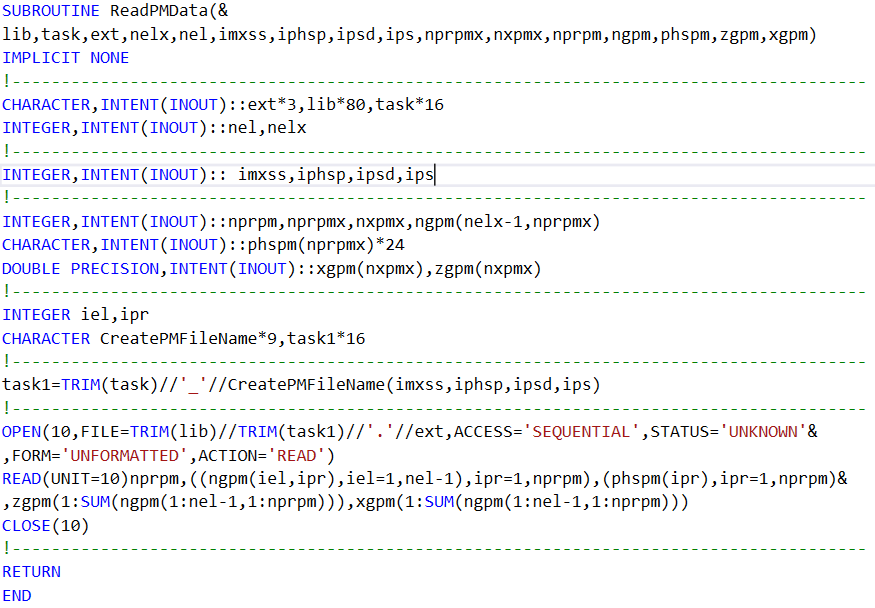
And also can you provide the definitions of the subroutines ReadPMDataSequentially and ReadPMData so we can understand how to write a generalized code.
If possible please provide the source code so that we can test from our side.
Thanks
Prasanth
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I would suggest using an OpenMP Task to perform the I/O in a read ahead manner. This should be relatively straightforward assuming that for any given file all reads have the same values in nelx, nprpmx, and nxpmx. IOW while each rank is processing their current data, each rank's additional OpenMP Task is reading their next buffer (including waiting for MPI_SEND/MPIRECV synchronization. The call from the doWork MPI rank to ReadPMDataSequentially simply (if necessarily waits for I/O to complete, then) copies the buffered data and indicates to the OpenMP Task (or re-enqueues the task) to begin reading the next slice of the file.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for your answers!
I forgot to mention that I am unfortunately stuck to use MPI as some subroutines supplied by a third party prohibits use of OpenMP.
Please find attached the subroutines ReadPMData.f90 and ReadPMDataSequentially.
The files read and written are fairly small (nelx<=20, nprpmx<=2 and nxpmx<=1000).
The maximum number of subgroups is 20.
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I finally sent the files as an attachment to idz.admin@intel.com!
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think you need to describe your application and how it manages file data.
As presented in #5 and #6, each rank OPENs a filename constructed with a dummy argument from ReadPMDataSequentially named task. As to if this has the same value for all ranks (for each iteration of all ranks) is unknown. Do all ranks read the same file for each iteration of all ranks .OR. does each rank use a different value of task for each iteration of all ranks?
Note, should all ranks use the same value for each iteration of all ranks, then you have effectively have a file with a single record. Do you coordinate the reads of this file with the writes of data in some other procedure of your application.
It is difficult to give meaningful advice when the entire relationships are unknown.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Each thread reads its own file. The files contain diffusion profile data, which is used as input to a diffusion calculation for a time step. The integrated diffusion profiles are then store in the same files and the procedure is repeated for the next time step. The reason why there is a need to store the profiles is that there are diffusion in several volumes, for which the diffusion fields are coupled via diffusion exchange via a matrix in which the volumes are embedded in.
I hope this was somewhat clarifying!
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Presumably, if each rank is the only rank that both reads and writes its private file then:
1) OPEN once, then use REWIND after each READ (such that subsequent read starts at beginning of file), do same for WRITE
2) Use MPI_BARRIER or MPI_BCAST either before or after READ and/or write depending on your needs
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Thanks for your answer!
First I must correct myself:
As I said initially I have split the group of threads into a number of subgroups. All threads in a specific subgroup need to get the same
data via e.g. a file read. After integration the new content of the file is only written once as it is the same for all threads in the subgroup.
Have I understood you right then that as long as a file is open reading or writing is a memory, not a hard disk, operation?
If there are several subgroups, isn't there still a risk for hard disk access collision?
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi JIm again,
If I define an array of structures containing the same information as the files, it should be possible to avoid hard disk communication, shouldn't it?
There is no need to save these files between computations.
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>Have I understood you right then that as long as a file is open reading or writing is a memory, not a hard disk, operation?
This would depend upon multiple factors. 1) how large is the data, 2) how large is/are the I/O buffers within the Fortran program, 3) how large and the buffering natures of the O/S system 4) and/or how large and the buffering natures of the NAS system, 5) ...
In many simulation systems it is not unusual to process state Tn -> state Tn+1 without disturbing Tn. Then do the same with Tn+1 -> Tn+2
Conceptually this requires two memory states:
A -> B -> A -> B ....
From your description to date, it appears you are performing:
A -> B -> write B to file -> read A from same file -> A -> B -> write B to file -> read A from same file ->...
The usual method to do this is to use pointers (or an extra dimension to select data set).
After each integration step, swap pointers (or with an extra dimension flip the selectors to select obverse data sets).
(in either method you may periodically checkpoint the progress)
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anders,
You can try MPI I/O functions which are a performant alternative to serial I/O.
The MPI I/O calls can be used for reading and writing to files after splitting the COMM into subgroups.
Each subgroup can read and write to a separate file.
Also when you have said that you have excess threads did you mean ranks?
Thanks
Prasanth
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Prasanth,
Thanks for your answer!
I have 36 threads and need 18 to speed up the calculation. More threads do not contribute to speed. By dividing the 36 threads into two subgroups I can perform two interdependant calculations in parallel instead of in series, which will double the speed.
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anders,
Have you tried with the MPI I/O calls for your file I/O for each subgroup?
Let us know if you face any issues while doing so.
Thanks
Prasanth
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Prasanth,
I had a look at MPI IO and got aware that it is a rather complicated IO system. Can you recommend any tutorial with some application examples for Fortran? Can I find any code example for MPI IO applied on a derived variable?
I have realized that for the actual IO problem, I can leave disk storage and instead define and use a derived variable for the contents of the files. By using ALLOCATE I can tailormake one dimension of the derived variable after the number of subgroups. This will also speed up the program somewhat, especially if the number of threads reaches one hundred.
Hi Jim,
Your description of my file read/write is correct. I have not used pointers so far but will have a look at it, as it seems to give increased flexibility.
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>I have not used pointers so far but will have a look at it,
If you are adverse to using pointers, you can use an array with two elements. Then swap the index numbers
type(yourType_t) :: data(2)
...
buffA = 1
buffB = 2
... ! initialize data(buffA)
do i=1,nTimes
call doWork(data(buffA), data(buffB))
buffA = buffB
buffB = 3 - buffA
end do
...
subroutine doWork(A, B)
type(yourType_t) :: A, B ! A is input buffer, B is output buffer
...
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anders,
I am providing a GitHub link that contains code examples using MPI I/O.
https://github.com/pmodels/mpich/tree/master/test/mpi/f77/io
Here you can see how to read and write to a file using MPI.
Thanks
Prasanth
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Prasanth,
Thanks a lot for your hint where to find source code!
Best regards
Anders S
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Anders,
Could you please let us know if your query is resolved.
Reach out to us if you need any help.
Thanks
Prasanth
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page