- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi everyone,
I am looking for a solution to accelerate the performances of my program with a lot of matrix multiplications. So I hace replaced the CLAPACK libraries with the MKL. Unfortunately, the performances results was not the expected ones.
After investigation, I faced to a block triangular matrix which gives bad performances principaly when i try to multiply it with its transpose.
In order to simplify the problem I did my tests with an identity matrix of 5000 elements ( I found the same comportment )
|
NAME |
Matrix [Size,Size] |
LAPACK (second) |
MKL_GNU_THREAD (second) |
|
Multiplication of an identity matrix by itself |
5000 |
0.076536 |
1.090167 |
|
Multiplication of dense matrix by its transpose |
5000*5000 |
93.71569 |
1.113872 |
- We can see that the CLAPACK multiplication of an identity matrix is faster ( x14) than the MKL.
- We can note an acceleration multipliy by 84 between the MKL and CLAPACK dense matrix multiplication.
Moreover, the difference of the time consumption during the muliplication of a dense*denseT and an identity matrix is very slim.
So I tried to found in LAPACK DGEMM where is the optimization for the multiplication of a parse matrix, and I found a condition on null values.
/* Form C := alpha*A*B + beta*C. */
i__1 = *n;
for (j = 1; j <= i__1; ++j) {
if (*beta == 0.) {
i__2 = *m;
for (i__ = 1; i__ <= i__2; ++i__) {
c__[i__ + j * c_dim1] = 0.;
/* L50: */
}
} else if (*beta != 1.) {
i__2 = *m;
for (i__ = 1; i__ <= i__2; ++i__) {
c__[i__ + j * c_dim1] = *beta * c__[i__ + j * c_dim1];
/* L60: */
}
}
i__2 = *k;
for (l = 1; l <= i__2; ++l) {
if (b[l + j * b_dim1] != 0.) {
temp = *alpha * b[l + j * b_dim1];
i__3 = *m;
for (i__ = 1; i__ <= i__3; ++i__) {
c__[i__ + j * c_dim1] += temp * a[i__ + l *
a_dim1];
/* L70: */
}
}
When I removed this condition I got this kind of results :
|
NAME |
Matrix [Size,Size] |
LAPACK (second) |
MKL_GNU_THREAD (second) |
|
Multiplication of an identity matrix by itself |
5000 |
93.210873 |
1.090167 |
|
Multiplication of dense matrix by its transpose |
5000*5000 |
93.71569 |
1.113872 |
- Here we note that the multiplication of a dense and an identity is very clause in term of performances, and now the MKL shows the best performances.
- The MKL multiplication seems to be faster than CLAPACK but only with the same number of non-null elements.
I have two ideas on this results :
1. The 0 optimization is not activated by default in the MKL
2. The MKL cannot see the 0 (double) values inside my sparse matrices .
May you tell me why the MKL shows performance issues ? Do you have any tips in order to bypass the multiplication on null elements with dgemm ?
Thank you for your help
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sebastien,
It looks like your matrix is very regular. If it is the case, then general sparse formats are of little help as they ignore the regularity of the structure (almost).
My suggestion would be:
1) If you have a truly diagonal matrix that you want to multiply with another dense matrix, then you need smth often called dgemm. I believe it is not present on MKL but it may appear in oneMKL in the future. I think I see a similar request for the BLAS team.
2) If you have the second matrix of yours, a block diagonal with varying block size, and you want to invert it (did I get it right?), then I would say that again, hand-written and optimized routine should be the best. There is sparse BSR format but it assumes a fixed block size and will incur a significant overhead. For inverting small dense blocks you can consider using the batched LAPACK functionality (I cannot find the link to doc link right away, maybe someone else would help).
Just FYI, there are routines for sparse matrix inversion in MKL, but they are designed to work with general sparse matrices and will not help much for small matrices with a fine regular structure like yours.
Best,
Kirill
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi!
I can not comment on the performance of dense matrix multiplication routines, but I have a question: how sparse are your matrices?
When the matrices are sparse enough, it might be beneficial to use the sparse matrix multiplication routines and use sparse matrix formats to store the matrices. Whether it makes sense or not, depends on the application, of course (e.g., what are the preceding/subsequent operations with the matrix data).
Best,
Kirill
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Firstly I want to thank you for your reply.
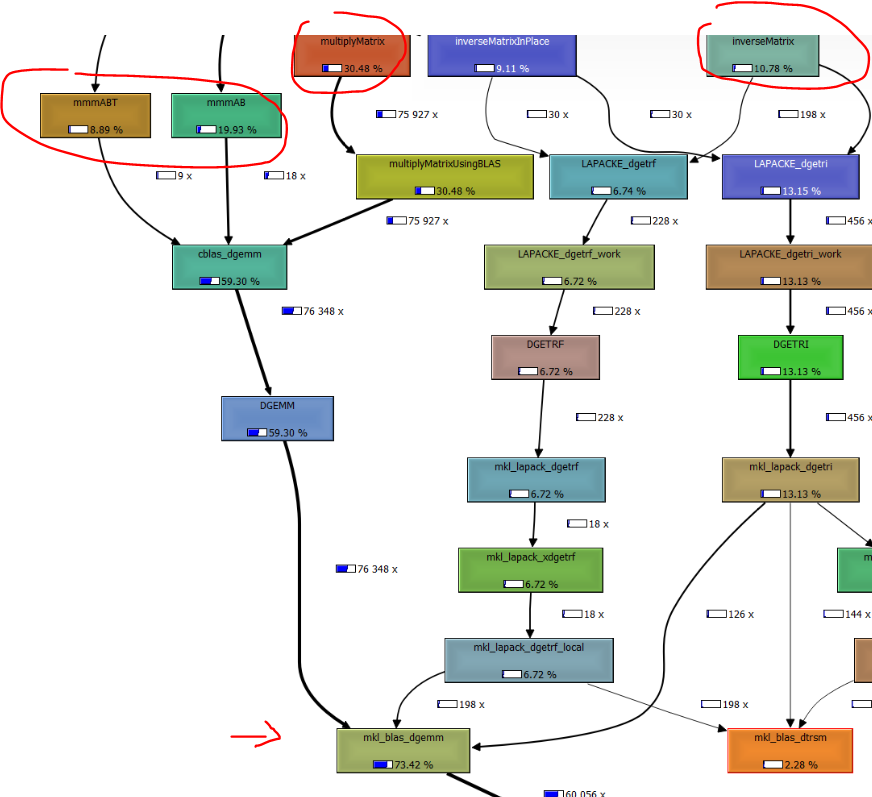
Yes I choose this kind of solution in order to optimize the multiplication of my matrix (see attachment Matrix*.jpg)
I have compressed my matrix into the CSR format and it did the job. But like you wrote, it depends on the application, because the next step is to inverse the result and there are no routines to inverse CSR matrices. And the inversion use the same multiplication routine. (see attachment inversion.jpg)
Can you advise me about a sparse matrix format which can be better in both multiplication and inversion ?
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sebastien,
It looks like your matrix is very regular. If it is the case, then general sparse formats are of little help as they ignore the regularity of the structure (almost).
My suggestion would be:
1) If you have a truly diagonal matrix that you want to multiply with another dense matrix, then you need smth often called dgemm. I believe it is not present on MKL but it may appear in oneMKL in the future. I think I see a similar request for the BLAS team.
2) If you have the second matrix of yours, a block diagonal with varying block size, and you want to invert it (did I get it right?), then I would say that again, hand-written and optimized routine should be the best. There is sparse BSR format but it assumes a fixed block size and will incur a significant overhead. For inverting small dense blocks you can consider using the batched LAPACK functionality (I cannot find the link to doc link right away, maybe someone else would help).
Just FYI, there are routines for sparse matrix inversion in MKL, but they are designed to work with general sparse matrices and will not help much for small matrices with a fine regular structure like yours.
Best,
Kirill
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for the confirmation. Intel will no longer monitor this thread. Further discussions on this thread will be considered community only.
Regards,
Rahul
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page