- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm currently trying to skip Pardiso reordering as I have already manually reordered the matrix previously.
As far as I can understand from the table description I should be able to skip the reordering by setting
iparm(5)=1
and
perm(i)=i for i=1,n
As is also suggested in the following topic:
https://software.intel.com/en-us/forums/intel-math-kernel-library/topic/295265
However when I do this and perform a factorization it still spends the majority of its time doing reordering!
=== PARDISO is running in In-Core mode, because iparam(60)=0 ===
Percentage of computed non-zeros for LL^T factorization
0
1
2
3
4
5
6
8
9
10
11
12
13
14
15
16
17
18
19
20
22
23
24
25
26
27
28
29
30
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
58
59
62
64
65
68
70
73
74
75
76
79
82
83
84
85
87
92
95
98
100
=== PARDISO: solving a symmetric positive definite system ===
1-based array indexing is turned ON
PARDISO double precision computation is turned ON
METIS algorithm at reorder step is turned ON
Single-level factorization algorithm is turned ON
Summary: ( starting phase is reordering, ending phase is factorization )
================
Times:
======
Time spent in calculations of symmetric matrix portrait (fulladj): 0.002223 s
Time spent in reordering of the initial matrix (reorder) : 0.750173 s
Time spent in symbolic factorization (symbfct) : 0.023511 s
Time spent in data preparations for factorization (parlist) : 0.002437 s
Time spent in copying matrix to internal data structure (A to LU): 0.000000 s
Time spent in factorization step (numfct) : 0.076703 s
Time spent in allocation of internal data structures (malloc) : 0.009243 s
Time spent in additional calculations : 0.023699 s
Total time spent : 0.887989 s
Statistics:
===========
Parallel Direct Factorization is running on 6 OpenMP
< Linear system Ax = b >
number of equations: 42332
number of non-zeros in A: 294080
number of non-zeros in A (): 0.016411
number of right-hand sides: 1
< Factors L and U >
number of columns for each panel: 64
number of independent subgraphs: 0
< Preprocessing with state of the art partitioning metis>
number of supernodes: 30842
size of largest supernode: 361
number of non-zeros in L: 3099767
number of non-zeros in U: 1
number of non-zeros in L+U: 3099768
gflop for the numerical factorization: 0.636571
gflop/s for the numerical factorization: 8.299116
Does anyone know what is going on?
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tue,
Have you ever tried to use parallel METIS algorithm at reorder step by setting iparm[1]=3 if you are not using CNR mode, seems you are using default setting for reordering.
Best regards,
Fiona
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fiona Z. (Intel) wrote:
Hi Tue,
Have you ever tried to use parallel METIS algorithm at reorder step by setting iparm[1]=3 if you are not using CNR mode, seems you are using default setting for reordering.
Best regards,
Fiona
I have tried to use the parallel version of METIS, but it still takes quite a while, and I would like to skip the reordering entirely which I thought would happen when I set iparm(5)=1 and perm(i)=i for all i.
But I guess I have to do something more before reordering is disabled?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I would like to check with language you are using, C or fortran? In C program, the iparm for controlling the permutation usage should be iparm[4], but in fortran its iparm[5]. Please check with the value of iparm[4], iparm[30] & iparm[35] to judge the solution for perm.
Another point is, I would like to check the indexing of rows & cols. If you are using one-base which iparm[34]=0, please set perm as: perm[i-1]=i (i=1,2,3,..., N); For zero-indexing which iparm[34]=1, please set as: perm=i (i=0,1,2,...,N-1). If the reordering time is still very long, could you please send us a simply case to reproduce your problem. Thanks.
Best regards,
Fiona
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fiona Z. (Intel) wrote:
I would like to check with language you are using, C or fortran?
I'm using Fortran, so I believe it should be parm[5] I should set to 1 as done above.
Fiona Z. (Intel) wrote:
Another point is, I would like to check the indexing of rows & cols. If you are using one-base which iparm[34]=0, please set perm as: perm[i-1]=i (i=1,2,3,..., N); For zero-indexing which iparm[34]=1, please set as: perm=i (i=0,1,2,...,N-1).
I'm not sure I understand what you mean here, I'm using Fortran which start indexing at 1, and you want me to set perm[i-1]=i (i=1,2,3,..., N)??
Surely it must be the other way around, since perm[i-1]=i (i=1,2,3,...,N) would require indexing to start at zero right?
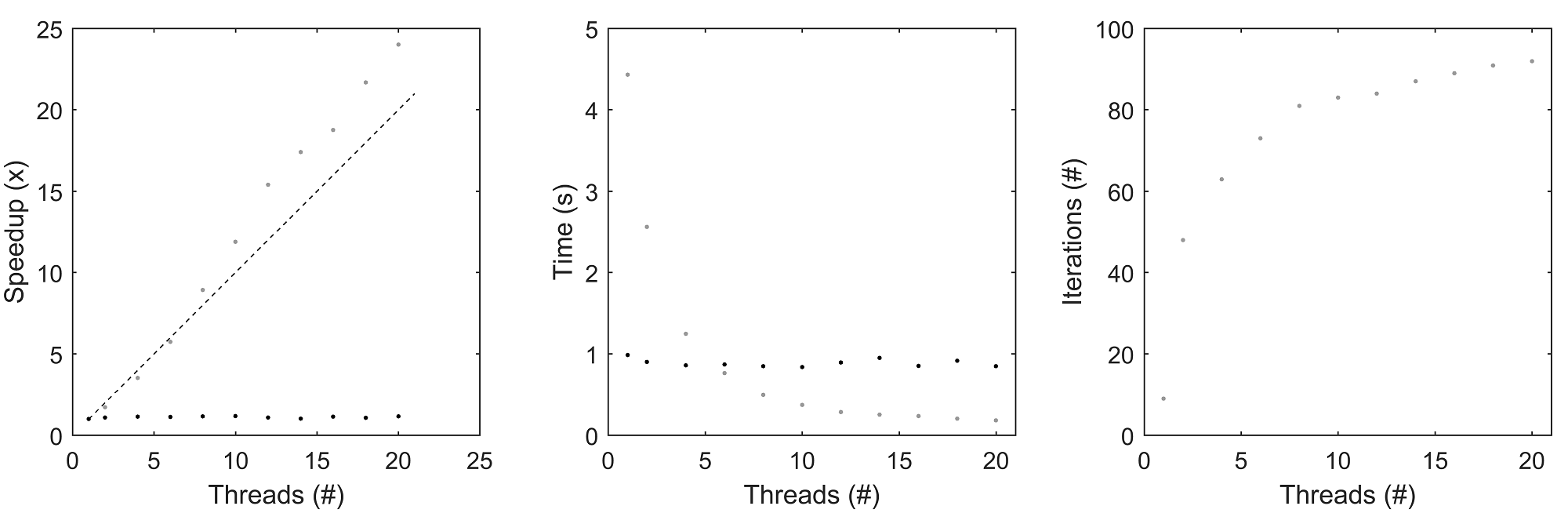
In any case I'm still seeing the same results from Pardiso, which are causing the solvertime to be quite long and very badly scaling, as noted by the attached figure, in which I compare my sparse iterative solver with Pardiso. (Pardiso is the black dots, the iterative solver is gray)
{kind=link}
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page