- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Does anyone have any tips for efficiently parallelizing std::partition using TBB? Has this been done already?
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So I have an idea for how to parallelize it:
parallel partition:
- if the array is small enough partition it and return
- else, treat the array as 2 interleaved arrays (arrays would keep track of stride)
- start a partition task for each (go to step 1)
- shuffle the elements between the two resulting partition/middle pointers as needed (hopefully not too many)
- return the merged partition/middle pointer
It seems to me like this should parallelize nicely, any thoughts before I try it?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sounds interesting, but to avoid false sharing you should at least take care not to break up cache lines. I'm not sure that recursive merging is the best approach, but you can always try it. Also, I think that there is actually only a limited opportunity to parallelise partitioning, because of a memory bottleneck, and so it might waste capacity that could be spent on actual computation. But have a good time experimenting, and let us know!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The alternative to recursive merging would be to partition in parallel along a number of interleaved lanes all right, but to limit their number, and to take several or all lanes together when merging. Again, the memory bottleneck is your enemy, so you might even want to avoid creating parallel slack as you would normally do and instead keep some cores available for computational work, especially without hyperthreading. My bet would be that performance becomes saturated with only a few lanes in use, few enough that you can merge in one sequential step.
Maybe you should also do a bit of studying how this pattern could interfere with a set-associative cache, which might accidentally put all elements of a lane in one set: perhaps it would be better to use a low prime number of lanes. Then again, it should not matter with LRU eviction, because each sequential partitioning algorithm only has two advancing fronts. Does anybody have an idea about possible interference with memory banks, though, and the appropriate strategy there?
Other viewpoints, criticism?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the helpful tips! Between the time I posted this and now I've become less convinced that the std::partition is the true bottleneck in my algorithm. I am currently trying to get some better profiling information before I proceed further. I think I will have some vtune profiling questions soon but I will post them to another thread.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
So the discussion is getting diverted to somewhere else and aborted? How disappointing...
If the operation does not have to be done in-place, it could also be implemented as a parallel_scan() (recording destination as a positive integer for true elements and a negative integer for false elements), and a parallel scatter operation. In between, the number of true elements T is determined so that the destination of a false element i will be T-d. The scatter will be very efficient because each subset progresses strictly monotonically to adjacent locations, and a parallel_for() will do the job very well. A further optimisation could be to scatter the true elements already during the parallel scan, and, if stability is not a requirement, also the false elements (in reverse order).
(Added) An intermediate array for the indexes of the false elements in a stable partition could be avoided by doing a second scan, I suppose.
(Added) Of course multiple passes, especially with a second scan, create more memory traffic, so that should be considered carefully.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
About the Stack Overflow comments:
std::partition_copy requires two different output regions, either allocated in advance or suffering at least O(n) amortised reallocation cost, e.g., with a back_insert_iterator into a vector.
I don't see how parallel_for()/parallel_for_each() would work? Oh, that's what the tbb::concurrent_vector or tbb::combinable is for... Well, that seems costly (tbb::concurrent_vector the most), and output will definitely not be stable.
tbb::parallel_reduce() also requires copying to intermediate storage. Isn't that Body instead of "task body"?
atomic<size_t> synchronisation is definitely not scalable.
Other problematic statements were already addressed there, I think.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry about the duplicate post on Stack Overflow, I usually post there but I was curious to compare this forum. The quality of the replies seem great, I do plan to use this in the future. The one note I posted there that I will re-post here for comment if you are inclined:
The "interleaved partition" idea was an attempt to get around the logarithmic complexity of the merge. Ignoring worst cases, two interleaved slices of an array should typically have similar value distributions. If so, the two resulting interleaved partition/middle pointers (I'll call them middle_low and middle_high) should end up near each other in the array. The end sections of the arrays (begin->middle_low, middle_high->end) will be correctly partitioned and won't need any merging. Only the elements in the middle range (middle_low->middle_high) would need some swapping, I think (middle_high-middle_low)/2 in the worst case?
Anyway, thanks so much for your insight! Sadly I haven't had time to try implementing anything because I'm no longer convinced that std::partition is the actual bottleneck in my algorithm. I'm currently working on profiling using oprof, vtune and valgrind/cachegrind but I'm still a bit stumped about what is going on. I plan on making a new thread with new questions today.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After a bit of a profiling diversion I now believe I do in fact need to somehow multi-thread std::partition. I'm going to try __gnu_parallel::partition first, but if that doesn't scale well...I have a cache friendly modification to my interleaved partitioning idea that I would like feedback on:
Treat the array as N interleaved arrays, where the interleaved arrays are divided precisely along cache boundaries. For example, if N=4 (a,b,c,d) and "|" represents a cache boundary it would look like this:
aaaa|bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aaaa|bbbb|cc
I would need to implement a special iterator that knew when to step and when to jump, so that so that the 4 interleaved "views" could be iterated as if they were contiguous arrays. Then, using those special iterators, run the serial std::partition algorithm on each in parallel. This would yield N partition/middle iterators, for example in caps here:
aaaa|bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aAaa|bbbb|ccCc|ddDd|aaaa|Bbbb|cccc|dddd|aaaa|bbbb|cccc|dddd|aaaa|bbbb|cc
If the data is not too pathological the partition/middle iterators should end up relatively near each other in the original array. Take those iterators and swap/merge the items between them* so the original array is partitioned. In my example that range looks large but I think it would typically be small compared to the size of the original array, again ignoring the pathological cases.
Does this seem like a good idea? Worth the effort to test it? Does TBB or C++11 have any features that would help figure out the cache size so I could implement those interleaved iterators?
*I could use std::partition on that small range but I think there is a simpler way to merge, I just haven't thought it through yet...
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As I wrote before, it's an interesting idea, provided you don't break up cache lines, and this is how you would handle that. These cache lines are actually pretty minute compared to the size of an array whose partition/split operation you would like to parallelise (above a specific cutoff point), so why not just use a plausible upper bound like 128 bytes instead of fretting about the actual value? You could probably even take several kB and also avoid worrying about alignment.
I'm far less certain about some other things I wrote above (related to memory), but you should keep them in mind, and maybe somebody else has something to say there.
For the end phase, you already have midpoints for each lane, so you can easily determine the final midpoint and start swapping around that without using std::partition. You should probably evaluate another cutoff point before deciding whether to do that in parallel.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm surprised by Arch Robison's suggestion on Stack Overflow. I wouldn't hesitate (much) to challenge such a solution with something based on scan+scatter, perhaps even attacking the problem in parallel from both ends. But only if stability is needed (note that it is not even mentioned), otherwise the solution with lanes seems preferable.
(Added) Something to play with, perhaps:
[cpp]
#include <stdlib.h> // EXIT_SUCCESS
#include <iostream> // std::cout
#include <vector>
#include <assert.h>
#include <tbb/tbb.h>
template <class Predicate, class RAI>
struct Body {
// parallel_scan Body
template <class Range>
void operator()( const Range& r, tbb::pre_scan_tag ) {
for (auto i : r) if (m_Predicate(i)) ++m_true; else ++m_false;
}
template <class Range>
void operator()( const Range& r, tbb::final_scan_tag ) {
for (auto i : r) if (m_Predicate(i)) m_RAI[m_true++] = i; else ++m_false;
}
Body( Body& left, tbb::split ) : m_Predicate(left.m_Predicate), m_true(0), m_false(0), m_RAI(left.m_RAI) {}
void reverse_join( Body& left ) { m_true += left.m_true; m_false += left.m_false; }
void assign( Body& b ) { m_true = b.m_true; m_false = b.m_false; }
// other (note that member variables are used directly in code, could be optimised)
const Predicate m_Predicate;
size_t m_true;
size_t m_false; // not currently used to construct a scatter table, just to check that all elements were accounted for
RAI m_RAI;
Body(const Predicate& a_Predicate, const RAI& a_RAI) : m_Predicate(a_Predicate), m_true(0), m_false(0), m_RAI(a_RAI) {}
};
template <class Container, class Predicate>
typename Container::iterator
parallel_stable_partition(const Container& c1, Container& c2, const Predicate& pred) {
typename Container::iterator mid;
tbb::parallel_invoke(
[&] {
typedef tbb::blocked_range<typename Container::const_iterator> Range;
Body<Predicate, typename Container::iterator> body(pred, c2.begin());
Range range(c1.begin(), c1.end());
tbb::parallel_scan(range, body);
mid = c2.begin() + body.m_true;
assert(body.m_true + body.m_false == c1.size());
},
[&] {
typedef tbb::blocked_range<typename Container::const_reverse_iterator> Range;
Body<std::unary_negate<Predicate>, typename Container::reverse_iterator> body(std::not1(pred), c2.rbegin());
Range range(c1.rbegin(), c1.rend());
tbb::parallel_scan(range, body);
assert(body.m_true + body.m_false == c1.size());
});
return mid;
}
// We'll use int as the element type, with 8 bits for sorting and 8 bits to check stability.
struct PartitionPredicate : std::unary_function<int, bool> {
bool operator() (int arg) const { return (arg >> 8) % 2; }
};
struct SortPredicate : std::binary_function<int, int, bool> {
bool operator() (int arg1, int arg2) const { return (arg1 >> 8) < (arg2 >> 8); }
};
int main(int argc, char *argv[]) {
std::vector<int> v1(200*1000*1000);
std::vector<int> v2(v1.size());
for (size_t i = 0; i < v1.size(); ++i) v1 = i % (256*256);
PartitionPredicate partitionPredicate;
auto mid = parallel_stable_partition(v1, v2, partitionPredicate);
for (auto it = v2.begin(); it != mid; ++it) assert(partitionPredicate(*it));
for (auto it = mid; it != v2.end(); ++it) assert(!partitionPredicate(*it));
std::stable_sort(v1.begin(), v1.end(), SortPredicate());
std::stable_sort(v2.begin(), v2.end(), SortPredicate());
assert(v1 == v2);
return EXIT_SUCCESS;
}
[/cpp]
(Added) Perhaps each side could, every so often, set an atomic variable to indicate where it is, check the other side's, and cancel if all elements were copied. Also note that this bidirectional approach only works with thread-safe predicates and copying: no move possible, but there's also only one copy per element.
(Added) Other variants can be easily derived, e.g., by doing away with the parallel_invoke() and writing the false elements from right to left to the result vector (obviously abandoning stability), or to intermediate storage and then in parallel to the result (keeping stability), etc.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for all the tips!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No thanks needed, as long as you do provide a summary of your findings!
BTW, my surprise about Arch's contribution on Stack Overflow may have been partially caused by a lingering memory of an earlier posting on this forum, where he already proposed the use of parallel_scan() to implement a pack operation (calling it an APL-style "compress" operation), and a partition/split can be viewed as two complementary packs, as my code above illustrates quite directly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As an aside, I tried out __gnu_parallel::partition today. My test array had1,000,000,000 pointers, this was the partition function:
auto partitionFunc = [partitionValue] (const values* v) {return (*v)[0] + (*v)[1] < partitionValue;};
I attached an image of my timing results, not so great...
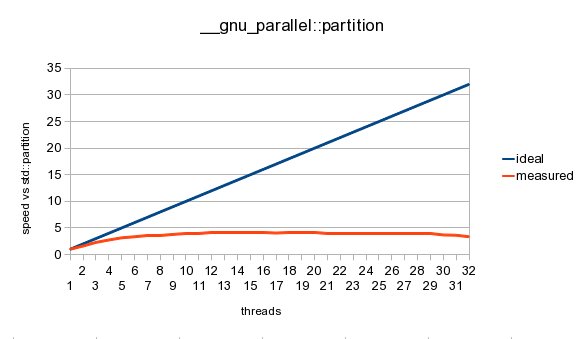{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry for the loooong delay, I had to put this on hold for a while for other work but I was able to pick it up again recently and I have a working prototype.
I'm happy to report that the cost of the interleaved merge is negligible, when I skip that step (partition the interleaved chunks but don't merge them) I get only minimal speedup. On the other hand, I'm not sure if I am managing the tasks as optimally as possible or if I am introducing some other overhead I'm unaware of. I'm getting promising timing results but I am hitting some scaling limits. On a 16 core machine I can about 12x speedup over std::partition but that is only with an array of 2,000,000,000 pointers, pointing to larger structs. That problem is 200x larger than my largest realistic case, if I reduce the problem size to 1,000,000 pointers I can get 4x speedup on 16 cores at best. I'm wondering if I have to accept this limit or if there is more I can do to optimize things?
Another interesting observation I made was that it seems to run fastest with a block size of ~4kb, rather than the 128b that I originally tried. I'm guessing this has something to do with L1 cache rather than cache-lines? Do false-sharing issues apply to L1 cache as well as individual cache lines? 4kb doesn't seem to correspond to any particular cache size so maybe it is something else.
I have implemented this using the tbb::task class. I read the "Catalog of Recommended task Patterns" page and I'm currently using the "Blocking Style With k Children" pattern but I'm not sure if one of the other patterns might be more optimal. There are some hints on that page but I'm not sure how to interpret their meaning. What is meant by "state" in the various recommendations, eg "This style is useful when the continuation needs to inherit much of the state of the parent and the child does not need the state."
(EDIT: I removed the code because I'm working on a much cleaner version now using tbb::parallel_reduce and a custom range class...)
Adam
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
BTW, this algorithm only works for memory-contiguous arrays of data eg std::vector or c style arrays, that is why the algorithms take in raw pointers rather than iterators. Other data structures won't work because the interleaved block concept wouldn't make sense.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry, maybe I've given a bad example, but your code requires more high-level exposition, because there's always competition for attention and this seems like it will take more than a few minutes to analyse. So this is just from a very first impression.
I'm suspicious that you've based the solution directly on tasks, so you should probably explain that. Couldn't you use parallel_invoke(), instead? If so, please do, if not, why not?
False sharing at the level of the cache occurs within pages, not across pages, whatever their size, because of nested alignment constraints. Does this occur for SMP as well as NUMA, or only the latter? Note that translation lookaside buffer (TLB) thrashing may be an issue in some algorithms, so you might want to investigate along those lines (no pun intended).
I may have another look at this later on.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I originally implemented it with structured_task_group but I was curious to see if any of the variations in the "Catalog of Recommended task Patterns" could improve performance. I will switch it back to a high level implementation for sake of simplicity if I can't get significant improvements. Is there a significant difference between structured_task_group and parallel_invoke? Thanks for your time.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think I'm slowly getting my head around the "Catalog of Recommended task Patterns", this is my first exposure to continuation passing style. In my code I'm guessing the recommended pattern would be "Recycling Parent as a Child"? And I would need to set up a second task class type for the merge to be used as the continuation task? I will try it out Monday...if it doesn't help I'll go back to parallel_invoke.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Actually...I think I might be able to use parallel_reduce and let tbb handle the recursion...if my interleaved_iterator::range class could be substituted for tbb:blocked_range...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page