- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I developed a h264 decoder by referring sample_decode module from media SDK samples 2016. I am running this decoder on a windows7 machine having Intel HD Graphics 4400 card. My requirement is to receive h264 stream frame by frame over network, decode it and then pass the raw frames (in NV12 or RGB32 format) in a buffer to another module for rendering. So after decoding through HW, I do memcpy raw frame bytes from output surface of decoder (which is a little costly operation I understand).
Now what I am observing is that using SYSTEM_MEMORY option in decoder is giving comparatively better decoding performance than using D3D9_MEMORY. In fact I modify the original sample_decode code also and add the memcpy of raw frames for MODE_PERFORMANCE case. Then the performance of this sample_decode was same as in my custom decoder, i.e. D3D9 memory was slower.
So my question is:
1. Is it obvious that system memory is faster than d3d9 memory considering my memcpy requirement, or I am doing something wrong?
2. Is it possible to share the output surface of decoder directly with other module for rendering? Through this I want to avoid this costly memcpy option.
3. Is there any option of copy from Decoder's output surface to any other IDirect3D9Surface which is more faster than memcpy?
Thanks,
Ramashankar
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
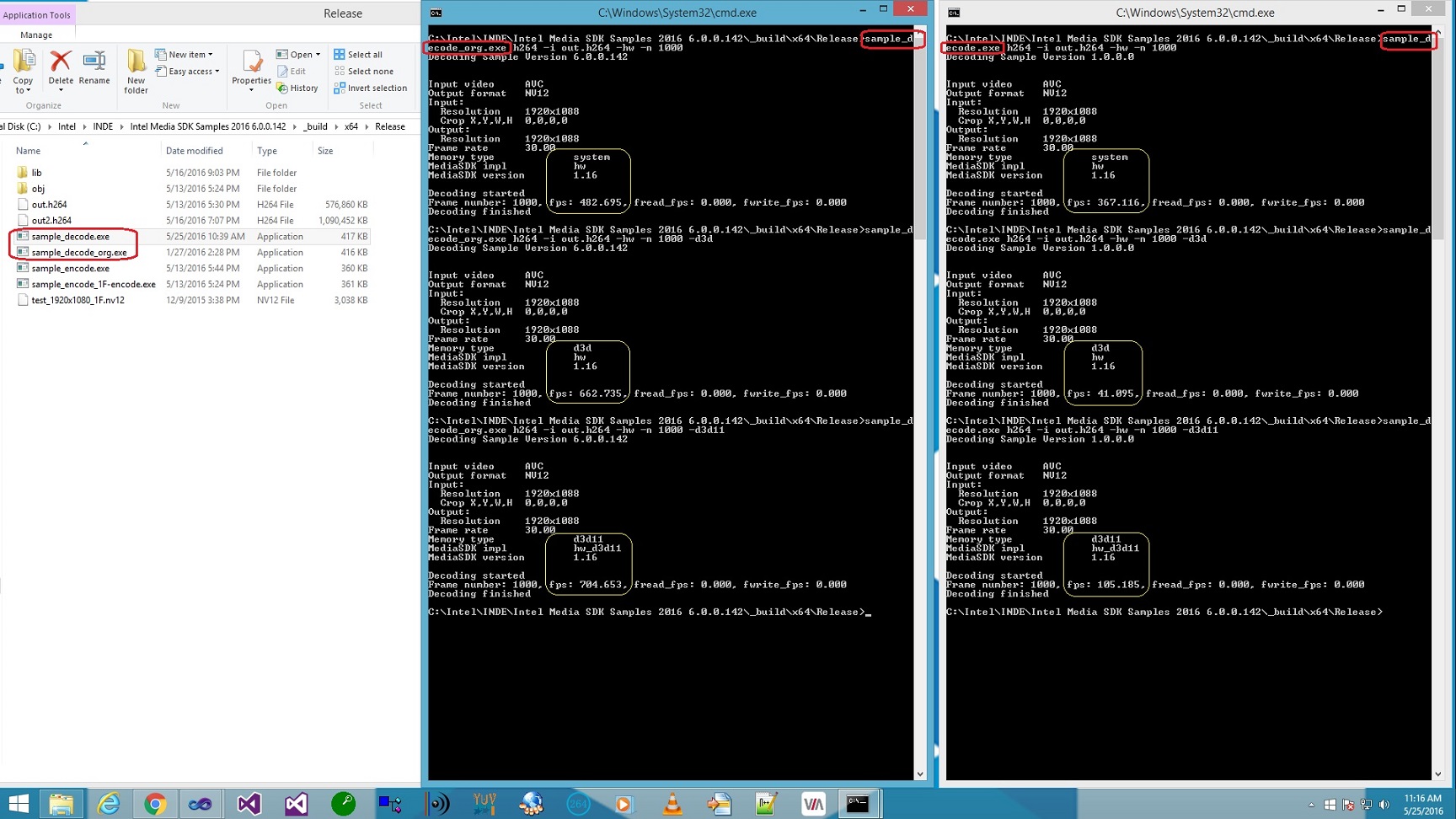
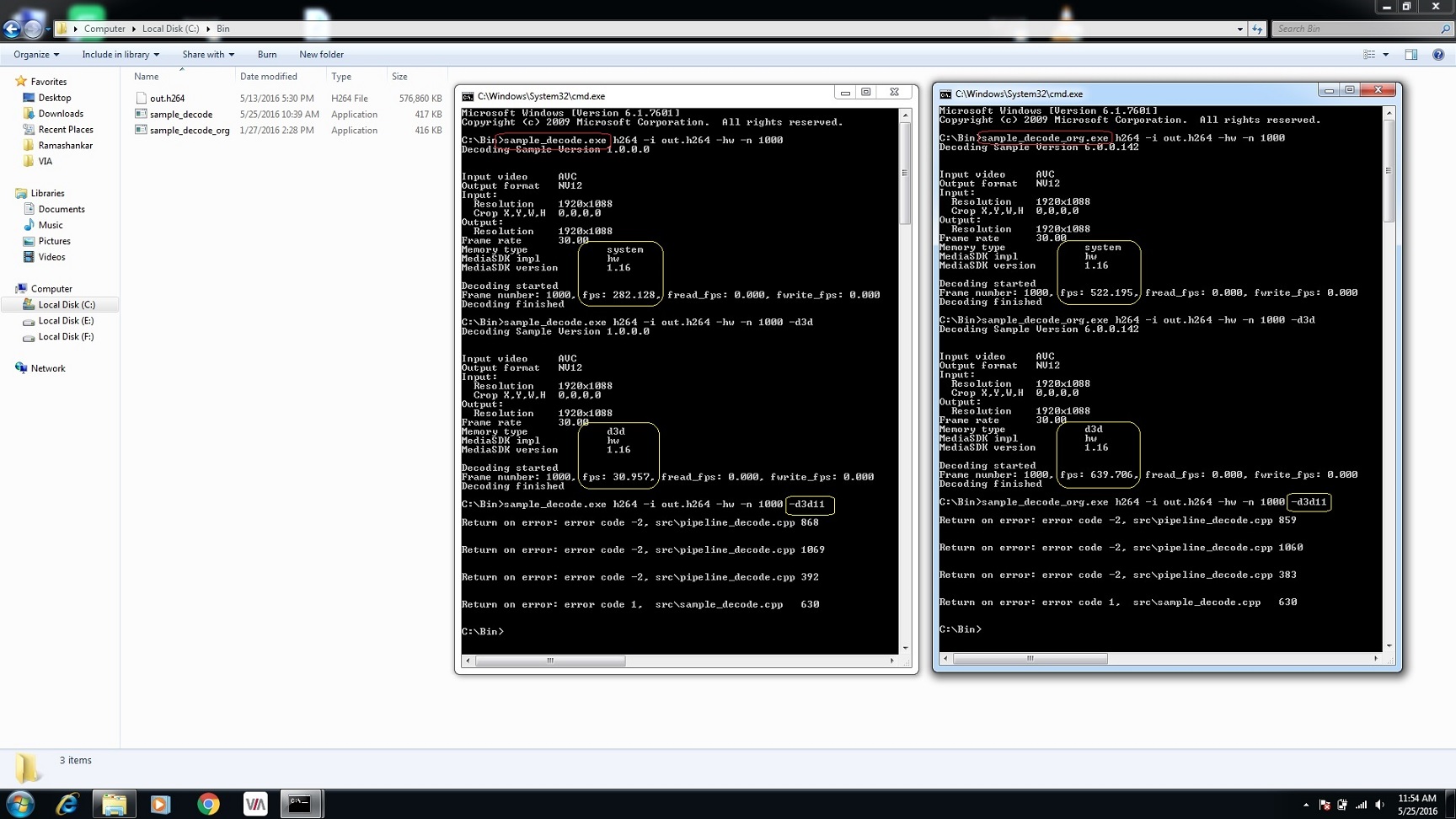
In continuation to my above queries, I am sharing the modified sample_decode code which I used to check the decoding performance on a Windows7 and a Windows8 machine both, for copying raw frame bytes from output surface. I am also attaching the result snapshot in which:
- 'sample_decode.exe' is the modified exe which is generated form attached code. It does the memcpy of raw frame bytes.
- 'sample_decode_org.exe' is original exe supplied by Intel in their sample at path [Intel Media SDK Samples 2016 6.0.0.142\_bin\x64]. It doesn't perform any memcpy or file write in MODE_PERFORMANCE mode.
So when no memcpy, decoder performance is awesome with D3d9 memory, but it slows down if i do memcpy for frams.
So please suggest what could be the efficient way to use video memory on Windows7 for decoding and extract raw frame from surface for rendering.
Thanks,
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Any input or suggestions on my issues n queries?
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ramashankar,
As I am understanding your use case, you need to feed the data from decode to another buffer for rendering and for that you are doing memycpy to system memory. If that is the case, please use MSDK_IO_Pattern for that, this IO pattern access requested patterns for SDK function. It should be MFX_IOPATTERN_OUT _SYSTEM_MEMORY which outputs to SDK functions is a linear buffer directly in system memory instead of doing memcpy which CPU intensive operation and will cause performance drops. Please change the value of m_mfxVideoParams.IOPattern in pipeline_decode.cpp.
Let us know if we didn't get your question correct.
Surbhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For windows 7 & windows 8 question - Intel Media SDK supports d3d11 on windows 8 or newer, not on windows 7.
From your results seems like you are using old graphics drive, I will recommend to update to the latest available on Intel website - https://downloadcenter.intel.com/download/25978/Intel-Graphics-Driver-for-Windows-7-8-1-15-36-
We release driver update frequently, which have bug fixes and better performance, please watch above link for latest ones in every few months :)
Surbhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Surbhi,
Thanks for your reply. Yes you understood my use case correctly. I need to get the data from decoder into a buffer which i can pass to other module (my custom renderer).
Regarding setting the IO Pattern to MFX_IOPATTERN_OUT _SYSTEM_MEMORY, I guess it is the same thing which is being done when I configure the decoder with m_memType = SYSTEM_MEMORY. Isn't it so?
Yes, when I set m_memType = SYSTEM_MEMORY then fetching decoded frame (using memcpy) from decoder's output surface is relatively very fast but by using system memory I observe that decoding speed gets slowed down.
So to get the optimum performance:
1. when setting MFX_IOPATTERN_OUT _SYSTEM_MEMORY, is there any way to pass my buffer to decoder so that it directly put decoded frames in that buffer? Currently I am doing explicit memcpy to get frames from output surface (refer sample code attached in above threads).
2. Since Intel sample decode app also does rendering through D3D device when using video memory, so I tried utilizing that in my case. I passed the decoder's output surface directly to my renderer module which is also created using DirectX9 interfaces, but it is unable to render from this surface. So can you let me know if it is feasible what I am trying here? Can decoder output surface be passed to any other renderer? if yes then how?
Thanks,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ramashankar,
The best performance option is to use memtype as video memory and IOpattern to be same i.e. video memory. However if one wants to have the data out in system memory to apply other filters or do some cpu intensive operation, then IOpattern = system memory can provide better results than memcpy, frames are stored in outsurface to be used for next operation.
Yes, decoder surface can be passed to another implementation of render. Can you please tell what your pipeline is like after decode, are you passing it to a filter and after that to render? If not, then why you need to get the data to system memory.. can you please give an idea?
Thanks,
Surbhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Surbhi,
Thanks for your reply. My pipeline is as following (attached a rough diagram for this):
[client devices] --> (send h264/jpeg stream over network) --> [Jpeg/H264 Decoders] --> (provides raw RGB32/NV12 frames in buffer) --> [Custom Renderer (perform stretching/re-aligning display on video wall)]
In an experiment, instead of passing raw frame buffers when I passed the decoder output surface object directly to renderer then it did not render, IDirect3DDevice9::UpdateSurface() or StretchRect return with D3DERR_INVALIDCALL error. I think as I am creating a d3d9 device object in renderer also so probably that device can not render from a surface which is attached with another d3d9 object. Do you alos think same?
But if I pass raw frame buffer to renderer then it works fine, but it is taking time in copying frames from output surface into frame buffers.
That's why I am looking for approach where
i. either I can pass decoder output surface directly to render, or
ii. I can get decoded frames in memory buffer in much faster way.
Hope my scenario is clear to you now.
Regards,
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Surbhi,
i. either I can pass decoder output surface directly to render, or
I implemented above approach successfully by passing decoder output surface and D3D9 device object both to my custom renderer module. Earlier I was passing only output surface then it didn't render. Now when I am passing d3d device object also, it is able to render properly with all the display effect implemented in my renderer.
Do you any further input or suggestions which needs to be taken care in above implementation?
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Surbhi, Intel Support Team,
Awaiting for your reply...
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ramashankar,
Yes, your scenario is much clearer now. Glad the first approach worked for you. With your first approach i.e. passing the surfaces to render looks like the best possible solution. Now going back to memory discussion. Let me know the following setting in your application -
Are you setting mem type to be system or video memory?
What is your IO pattern setting?
Are you doing single or multiple decode?
What is the async depth setting?
Thanks,
Surbhi
P.S. Apologies for late reply, was attending training event.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Surbhi,
Thanks for your reply.
- Are you setting mem type to be system or video memory?
- What is your IO pattern setting?
Earlier, when I was doing memcpy from decoder output surface, I was using system memory and MFX_IOPATTERN_OUT _SYSTEM_MEMORY. But now, in my new approach of rendering through surface, I am using Video (D3D9) memory and MFX_IOPATTERN_OUT_VIDEO_MEMORY.
- Are you doing single or multiple decode?
Its single decode per session for up to 6 sessions simultaneously. Each decode is in separate session/instance.
- What is the async depth setting?
async depth setting is 1 as I need to have low latency for real time streaming and rendering.
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ramashankar,
That's good, I believe you have all the best options included in your pipeline. If you see any particular media sdk piece being the bottle neck, feel free to contact us.
Thanks,
Surbhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ramashankar,
That's good, I believe you have all the best options included in your pipeline. If you see are seeing any particular media sdk piece being the bottleneck, please let us know.
Thanks,
Surbhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks Surbhi for your reply.
Yes. I do have some more queries but that is on different topic from this, so I will ask them in new post. You can close this thread.
Regards,
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page