- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello All. This is not a question, but just a small thought about NiosII connected to Altera SDRAM controller which may be usefull for everyone I hope.
I have started a Nios II design with Altera SDRAM controller. As I plan to share the SDRAM with another Master on Avalon MM bus, i tried to look at the data throughput performannce of the SDRAM controller. I arrive now at the conclusion that the default connection in SOPC builder or QSYS between even just a NiosII/f and SDRAM controller is far from optimal and that just a few adjustement makes it far better. The quick solution, that I have not seen elsewhere (but I am a beginner with NIOS II) is to "show arbitration share" at the SDRAM connection and to set credit to 8 (instead of 1, default value) for both instruction and data master bus of NIOS II connected to SDRAM controller... I try a quick explanation on why we should put 8 instead of 1: Some of my friends tell me to activate burst in cache properties of NiosII/f to improve performance. Now it seems clear to me that it can make performance even worse. => bad idea. After reading all the documentation I have found on SDRAM controller (not a lot of details...), and after having performed some simulations with Modelsim, here is my understanding : SDRAM controller is not able to perform burst access on Avalon MM bus (by design). But it is able to perform pipelined read with variable latency which provide actually at least same performance and maybe better than burst access. Pipelined read access is able to transfer one word at every clock cycle and even if addresses are not in sequential order. (for burst access, 1st address is given, next are implicit and address bus becomes don't care...). For write access, it is also obvious that Avalon MM can transfer one word at each cycle, (no latency for data). So we have to forget burst access, and look at pipelined read transfer. NiosII/f has cache memory on both instruction and data, usually using 32byte line cache. So that every cached transaction is a packet of 32bytes=8 word of 32bits. When I look at avalon read or write signal on data bus or at read signal on instruction bus (no write here...) there are continously activated for at least 8 cycles (or more when there is wait state). SDRAM controller is able to accept internally many read request. The simulation results are so promising. Basically the NiosII/f and SDRAM controller are well matched and able to perform read and write access in pipelined mode. 1 transfer at each clock cycle (after the first which has latency). Good news ! So where is the problem ??? The problem arises when 2 masters try to perform an access at the same time. And it is not so seldom. NiosII/f is a multimaster : both instruction and data master bus. And NiosII/f asks instructions often (expecially with linear code without loop) and also transfer data. SOPC Builder or Qsys automatically put an arbitrer for multi-master access. The problem is that, by default, Qsys or SOPC builder define an arbitration share credit of 1 for each master. And 1 means actually one word transfer. So that when both masters ask for 8 words, The first master is allowed to transfer one word only then it is stalled to allow the other master to transfer also 1 word only, then alternatively each master is allowed to transfer 1 word... But at the SDRAM controller, the result is catastrophic : usually instructions are not in same address range than data or stack, so not in same SDRAM row (maybe not in same bank, but SDRAM controller open only one bank at a time) : For each word, the SDRAM controller has to PRECHARGE (close) the current bank (tRP maybe 3 cycles), ACTIVATE (open) the next (tRCD maybe 2 or 3 cycle), Perform one READ (CL latency maybe 2 or 3 cycle)... multiply this by 16 words transfers (8 instruction and 8 data)... Instead of (with arbiration share of 8 = 8 credit word transfer for each) one PRECHARGE, one ACTIVATE, one READ with CL latency but then only 7 cycles for the remaining 7 words... Why Altera doesn't put 8 credit for each master by default in this hidden, not well explained feature ? I guess that many design could be optimized :) Michel. note: Simulation can be done by designing a small system (one NiosII/f, one SDRAM 32bits, one JTAG UART), then building a small Hello World application in NIOS EDS and using Run As -> Modelsim. In the Qsys or SOPC builder, Nios reset address should be in SDRAM, and SDRAM controller should include the functionnal memory model. When in Modelsim, type s, w and run 300 us. No need of a quartus top design, just the Qsys or SOPC builder system. Attached is a screenshot of this simulation with first 2 single access (instruction read) returning 1 word at every cycle (good !) but then an access both instruction and data read... Look how datareadvalid signal is so scattered...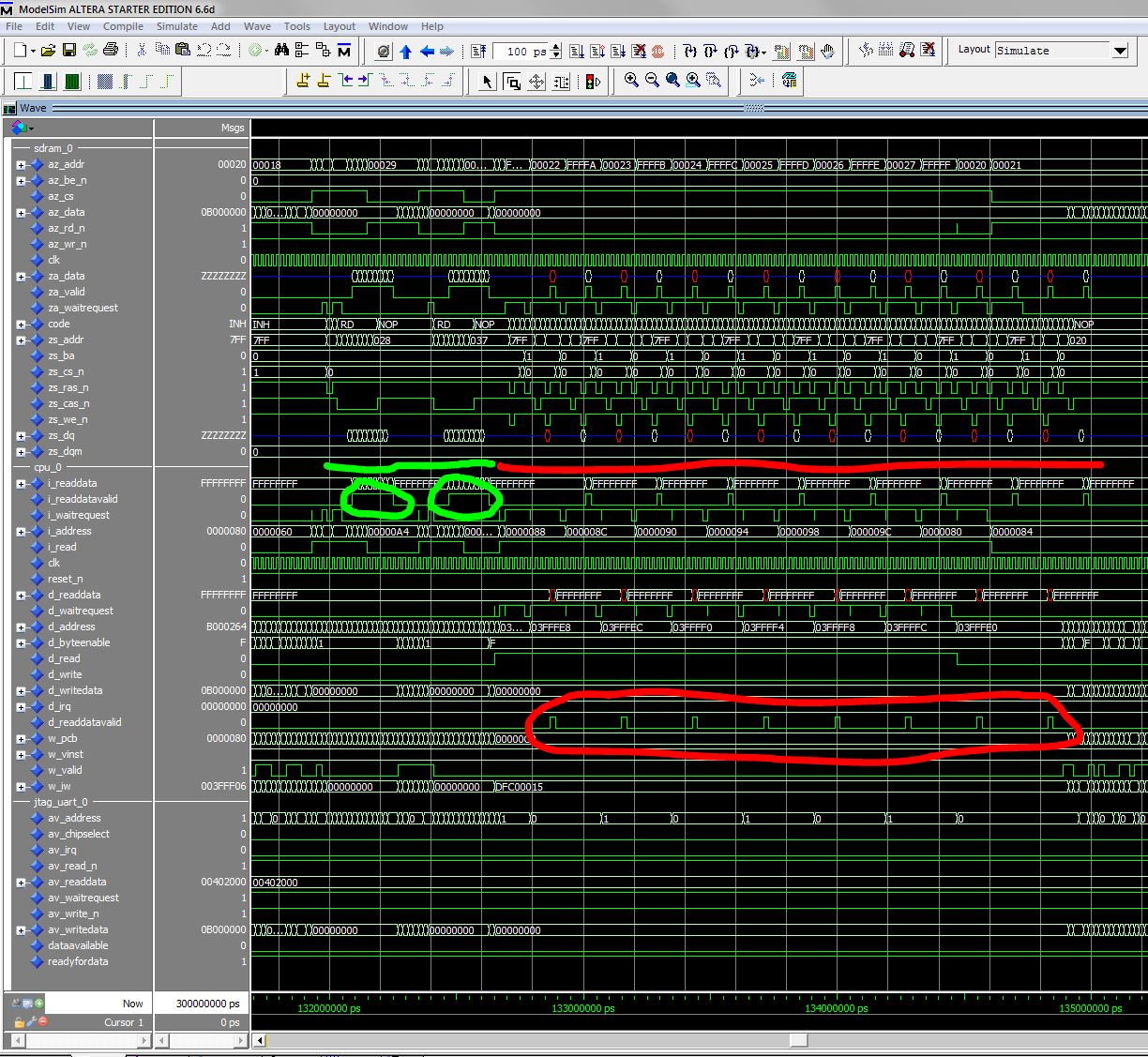{kind=link}
Link Copied
3 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- So we have to forget burst access, and look at pipelined read transfer. --- Quote End --- I don't believe this is accurate and I agree with your friends who suggested using bursts. While the SDRAM component itself does not implement a burst slave port, Qsys will automatically generate an adapter for you. You may enjoy reading https://www.altera.com/content/dam/altera-www/global/en_us/pdfs/literature/hb/qts/qsys_optimize.pdf --- Quote Start --- Altera recommends that you design a burst-capable slave interface if you know that your component requires sequential transfers to operate efficiently. Because SDRAM memories incur a penalty when switching banks or rows, performance improves when SDRAM memories are accessed sequentially with bursts. --- Quote End ---
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I find 2 reasons not to use burst with NiosII and Altera SDRAM controller : 1) I think it is slower than using Arbitration share to 8 without burst. After looking at simulation, burst adapters inserted (because SDRAM doesn't accept burst) add 2 cycles to every access. With a bank & row hit, SDRAM (with my configuration) returns 8 words of data in 14 cycles, so in 16 cycles with burst on. Read and write command arrive at SDRAM 2 cycle after leaving NiosII. Without burst, read and write arrive immediately at SDRAM, no latency added. 2) The size of design may increase due to burst adapter instantiated for each Nios II connection to slave. In a small sopc for Small hello world application (one NiosII/f with debug + sdram + JTAG uart) SOPC builder for instance seems to add 5 burst adapters. But after doing again more carrefully simulation with burst while leaving arbitration share to default value 1, simultaneous access are not scattered. So speed it is better than without burst enable in this case. The benefit is so balanced between 2 cycles added to each 32byte transaction and simultaneous accesses not scattered. The result may depend of actual application... Using no burst and arbitration share to 8 gives best result in all domains : no latency added, simultaneoeus accesses not scattered and no extra logic added... Attached is 3 simulations of small hello world application : 1=> no burst with arbitration share to 1 defulat, 2=>burst 3=> no burst with arbitration share to 8. There are not a lot of accesses, but I think it show the difference. The faster execution is without burst but with arbitration share set to 8. Time is measured from end of SDRAM configuration to end of hello world message display. 1=> 80.52us, 2=> 80.32us, 3=>78.82us. I am also a bit concerned with the recommendation of ALTERA you quoted: ALTERA seems to advice to design burst capable slave especially in the case of SDRAM controller, but its own made SDRAM controller doesn't implement burst itself ? That said, I love SOPC builder, it is actually a great tool to build system, and I just want to take the best of it :). Michel- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I agree with Michel's opinion.
Burst adapters inserted by Qsys is over-design from Avalon interconnect perspective and may reduce system Fmax. Right now the most efficient bursting is to ensure that both Master-Slave share the same burst properties, such as line or wrap burst and burst sizes. Nios itself supports fixed burst of 8 at both instruction and data masters but they employed wrapping and incremental burst types respectively. This makes it complicated to create a slave interface with burst that fits both cases. I think the value of 8 is used because Nios perform pipeline reads at size fixed at 8 as this is supported cache line size (D-cache can be configured for 4,16,32(default) bytes, I-cache fixed at 32 bytes). Let's say you have other masters connected to the SDRAM, 8 may not be the optimum value. In essence, "arbitration share" controls the interconnect behavior and is system dependent. For equality purpose, Qsys always defaulted to '1' for equal arbitration distribution and does not make any assumptions that user needs weighted distribution such as in Nios-SDRAM case. Overall, that is good findings though. Should recommend to Altera FAEs.
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page