- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all!
I'm creating a design that uses a Nios II processor with on board memory and wish to be able to read & write to the on-chip memory from custom Verilog. I did originally try using the Altera MM templates however as discussed by other users (search for 'Avalon MM templates in Qsys' on this forum), I experienced problems so have switched to using the mSGDMA template. My question is what ports should I be exporting to use in the my custom Verilog? Thanks, probably a simple question for someone!Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I suspect it is just the descriptor_slave port that needs written to. Is this correct?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm guessing you would want to expose the master data streaming port so that you can move data back and forth and the descriptor slave port so that you can instruction the DMA where it should be reading/writing. I'm assuming you are moving a block of data at a time to/from the on-chip RAM. If you are just performing random word accesses to the on-chip RAM then there is no point involving a DMA, just use a master interface in that case. Since you are accessing on-chip memory are you sure you don't want to just create a master interface and have your logic access it directly? Since your custom logic already knows where it wants to transfer data it's not much more than just an address (up) counter, a length (down) counter, and control logic that pauses the counters when waitrequest is asserted to recreate DMA types of transfers. If you describe what you are trying to do we can probably give you pointers of what to do.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi BadOmen
Thanks for your reply. Yes, random word access sounds like a good idea, so I'd like to create a master interface. I did try to use the templates here (altera.com/support/examples/nios2/exm-avalon-mm.html) however they did not seem to work. A pointer of where to start would be very helpful!- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Those templates basically implement half a DMA but by the sounds of it that doesn't sound like what you want.
That Avalon-MM specification is fairly flexible so you just include the signals that you need. If you want just a simple master interface you'll just need address, read, write, byteenable, readdata, writedata, and waitrequest. If you want higher performance add the readdatavalid signal which will allow your master to post multiple reads before data returns. So the first step is just to determine whether you need high performance reads. If the logic responsible for reads and writes can work independently you may want to implement two masters, one dedicated to reads and another for writes. Waitrequest is the most important signal to pay attention to, any time you are posting a read or write if waitrequest is asserted then you must continue to hold read/write high and keep the address, byte enables, and write data (if it's a write access) constant until waitrequest deasserts itself. When waitrequest is low and read/write is high then you consider that transfer complete and can move on to the next location you want to access. I recommend reading the Avalon-MM specification, it'll have more details. Essentially the logic you would have needed to control the master templates gets you half way to having a custom master, the other half is just making sure you heed waitrequest.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have implemented a memory master using the template from Qsys new component wizard. I've attached a screenshot of my signals from ModelSim when I'm writing to the on-chip memory. However when I access the same location using C code from the Nios II the value doesn't seem to have written. Do these signals look correct to you?
Many thanks!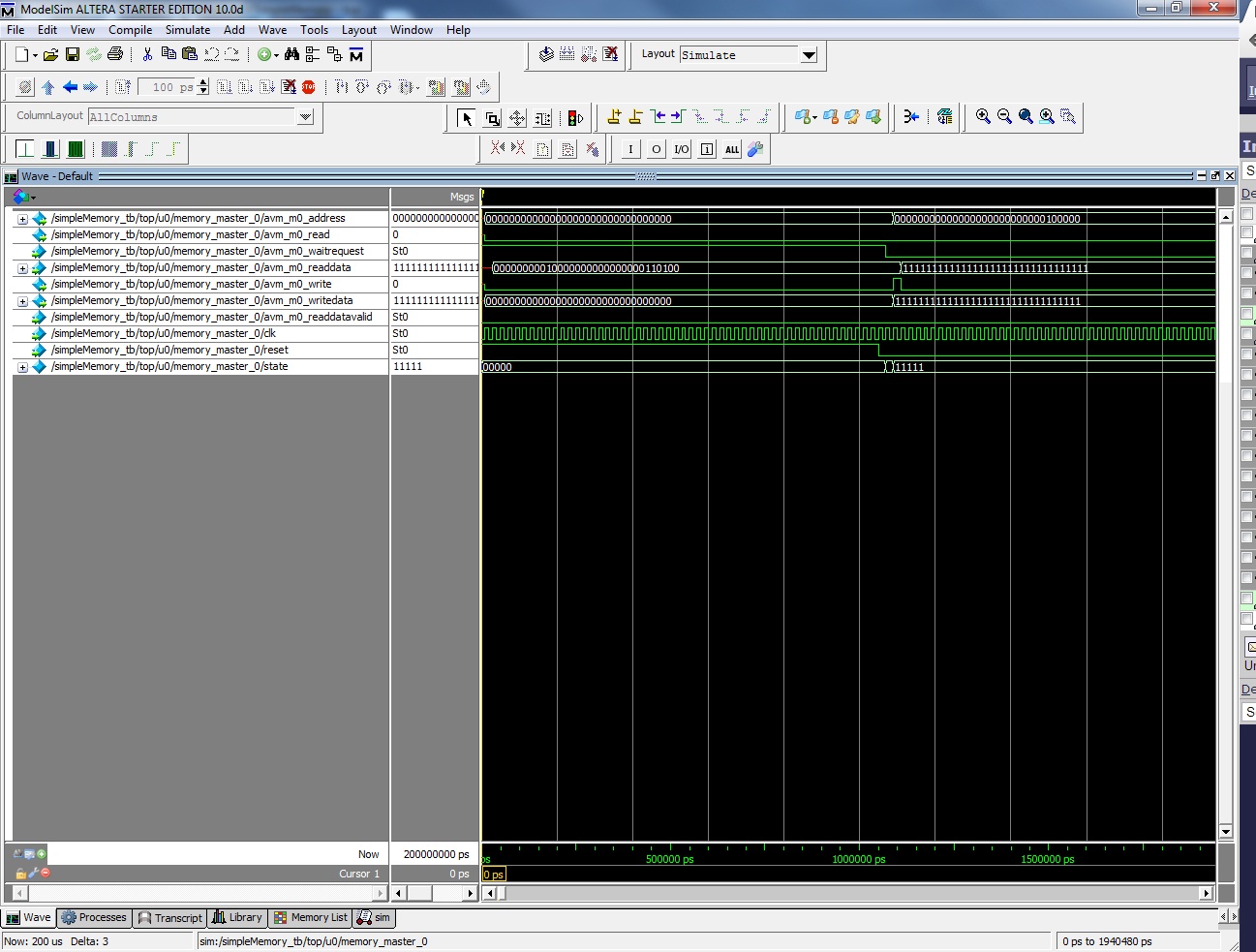{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Looks fine to me, I suspect you used IORD and passed in an offset of 0x100000? IORD uses 32-bit word offsets so you might have just accessed the wrong location.
I avoid IORD/IOWR and use the direct macros instead IORD_32DIRECT/IOWR_32DIRECT. Those ones you byte offsets so if that was your issue you should be able to just replace the macro and it should work.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also you should probably include byte enables, when you don't include them the tools assume that you are performing full word accesses. I would include them anyway and hardcode them high just in case you ever need to perform partial word accesses later down the road.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Adding the template from Qsys didn't give me the parameter of byte enables, how would I add this in?
I forgot my Nios II program would also be stored in the memory, which was overwriting my data, doh! It's working now. Many thanks for your help!- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's a common mistake, anyone that has worked with DMAs would be lying if they claimed they have never have done that :)
If you create a linker region you can have the CPU avoid putting code or data in that region if you want to share that memory with the external master. I forget how to do that in the linker script but the Nios II BSP editor should make that easier since it's graphical. * edit * Missed that part about the template. I wasn't aware the templates didn't have byte enables (oops). For now it would be just a matter of adding one one more signal to the template 'byteenable' and mapping it to the 'byteenable' Avalon-MM type. Then in the HDL you would just assign all ones to it. The width of the signal would be "DATA_WIDTH/8" so to assign a varible set of all ones you could do this: assign byteenable = {(DATA_WIDTH/8){1'b1}}; // takes '1' and replicates it (DATA_WIDTH/8) times- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi BadOmen and all,
I am using cyclone V SOC kit from Terasic. Currently I am searching for method to get high latency and thoughput, otherthan AXI bridges. Currentlly, I am using AXI bridge to communicate between FPGA and HPS; but I found this bridge seems ​to work​ with low latency. I made hps to fpga bridge connection for Light weight hps to FPGA communication. P.S : I go through exaple of Datamover; ​but I found it bit complicated. ​Could you please suggest me best method to communicate between HPS and FPGA for higher latency and higher thoughput. can I use datamover? ( https://rocketboards.org/foswiki/view/projects/datamover ) ​ ​Thanks in advance.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Even though this design is for Arria 10 SoC I would take a look at it to get a ballpark estimate of the performance you can expect from Cyclone V SoC: https://www.altera.com/support/support-resources/design-examples/soc/fpga-to-hps-bridges-design-example.html The design uses a baremetal program to control a bunch of mSGDMAs and pattern generator/checker cores in the FPGA to move data back and forth and measure the performance.
In the documentation subdirectory you'll find an excel spreadsheet with the numbers collected. The data shown is for the FPGA operating at 250MHz with 128-bit ports into the HPS and HPS SDRAM ports. In Cyclone V SoC if you have unidirectional data then what you could do is gang all the F2S ports together into a single 256-bit data path and move bulk data through it.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- Even though this design is for Arria 10 SoC I would take a look at it to get a ballpark estimate of the performance you can expect from Cyclone V SoC: https://www.altera.com/support/support-resources/design-examples/soc/fpga-to-hps-bridges-design-example.html The design uses a baremetal program to control a bunch of mSGDMAs and pattern generator/checker cores in the FPGA to move data back and forth and measure the performance. In the documentation subdirectory you'll find an excel spreadsheet with the numbers collected. The data shown is for the FPGA operating at 250MHz with 128-bit ports into the HPS and HPS SDRAM ports. In Cyclone V SoC if you have unidirectional data then what you could do is gang all the F2S ports together into a single 256-bit data path and move bulk data through it. --- Quote End --- Hello BadOmen, Many thanks for reply. I am using bidirectional data so could you please let me know another method? Your help would make my task easy :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think I need more information about what problem you are trying to solve since all the buses between the FPGA and HPS are bidirectional. With Avalon-MM connectivity you can only issue a read or write at any given time but AXI allows simultaneous reads and writes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi BadOmen,
I am quite new with Quartus. So basically, I used Qsys to generate my hps component ans my system. I created 2 slave component(read and write) ( avalon memory mapped slave) and i can through the lightweight HPS-to-FPGA bridge map the address of the first slave (write) and write data. Also with the second one i can read data from it by the hps. The problem is that the lightweight HPS-to-FPGA bridge has a capacity of 32 bits. So now, I would like to use the HPS-to-FPGA bridge which has a capacity of 128 bits. I did the same thing that i did for the lightweight. but it doesn't work. I don't know why?? What is the difference between those two bridges? is there something to add (configuration)? Could you please help me out from it?? It will be your great help!!- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The lightweight bridge is 32-bit because it's mostly meant for controlling IP (accessing control and status registers) whereas the H2F bridge is intended for higher throughput memory transfer operations. That said if you are looking to maximize the performance having the FPGA move data in/out of the HPS through the FPGA-to-SDRAM interface is going to be the fastest method for bulk data.
In order for either of the H2F bridges to operate they need to be mapped into the address space (registers in the system manager control this) as well as they have to be receiving an active clock and pulled out of reset. The security of the bridge slave ports also needs to be set accordingly, by default the entire system is secure so if you have been dividing the system in secure and non-secure regions it could be security getting into the way. That's about all I can tell you without knowing how it fails. Do you get a memory access error if you attempt to access the FPGA? Does the system crash when you attempt to access the FPGA? Does the MPU lock up when you attempt to access the FPGA, and if so have you checked to see if the transaction reaches the FPGA using signaltap?- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- The lightweight bridge is 32-bit because it's mostly meant for controlling IP (accessing control and status registers) whereas the H2F bridge is intended for higher throughput memory transfer operations. That said if you are looking to maximize the performance having the FPGA move data in/out of the HPS through the FPGA-to-SDRAM interface is going to be the fastest method for bulk data. In order for either of the H2F bridges to operate they need to be mapped into the address space (registers in the system manager control this) as well as they have to be receiving an active clock and pulled out of reset. The security of the bridge slave ports also needs to be set accordingly, by default the entire system is secure so if you have been dividing the system in secure and non-secure regions it could be security getting into the way. That's about all I can tell you without knowing how it fails. Do you get a memory access error if you attempt to access the FPGA? Does the system crash when you attempt to access the FPGA? Does the MPU lock up when you attempt to access the FPGA, and if so have you checked to see if the transaction reaches the FPGA using signaltap? --- Quote End --- Hi BadOmen, Thanks for your reply. Now,I am able to use H2F AXI bridge; which ofcourse increase throughput. Now, my second point is to decrease latency so could you please let me know which method should I use? For calling component I am using dev/mem method which is calling my component so as per my thoughts which is leading to increase latency. so could you please let me know other method. Many thanks in advance :)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Unfortunately there will not be much you can do to reduce the latency from the HPS into the FPGA from a hardware perspective.
I suspect what you need is a kernel driver that talks to your hardware directly because I think dev/mem maintains a copy of the data and moves it to/from the destination which is adding an additional copy operation. Keep in mind I'm a hardware engineer so I could be completely wrong. Your driver would mmap the region and provide APIs for accessing the hardware. I would search around for online material about how to write a Linux device driver because this information isn't Altera SoC specific and there is a lot of material on the web about this. You might find quite a bit of information on rocketboards about this as well, for example this: https://rocketboards.org/foswiki/view/documentation/ws3developingdriversforalterasoclinux- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page