- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am writing a code that uses many FFTs (billions) of fairly long sequences (100,000 - 1,00,000). It is crucial to find the fastest way to execute those. I read a technical report:
https://epubs.stfc.ac.uk/manifestation/45434584/RAL-TR-2020-003.pdf
that claims that the execution time for complex-to-complex FFTs with MKL is about twice as LOW as that of real-to-real FFTs of the same length (in particular, for a length of around 1,000,000).
This seems counter-intuitive, as the complex-to-complex transform should require about twice the number of operations. In fact, one can process two real-to-real transforms in one complex-to-complex call. I can imagine the execution time being roughly equal if complex arithmetic is performed in parallel in the micro-architecture, but it would puzzle me if it is lower.
My first question is simply if this is true.
My second question is what settings this result depends on (e.g. mkl_num_threads, compiler optimization, storage scheme, flags to encourage SIMD processing, et cetera).
If this is true for -Ofast compiling and when allowing MKL to grab any number of threads (up to the number of physical cores) then I will commit to using complex-to-complex transforms.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
From that paper, it seems that the relative performance difference between real and complex is sensitive to the characteristics of the number of variables (value of N). And that there are two sections of the calculation: Initialization and execution. In looking at the charts:

It would seem to indicate that you may benefit by padding your number of points to the next power of 2 .OR. making the number for N be the product of two integers. The values you use in the padding cells should be chosen as to not adversely affect the results data.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also:
>>I am writing a code that uses many FFTs (billions) of fairly long sequences (100,000 - 1,00,000). It is crucial to find the fastest way to execute those. I read a technical report
If each of the many FFT's are independent of each other (with each FFT having long sequences), you should experiment with using:
OpenMP to loop through each FFT, calling (linked with) the MKL sequential library (iow .NOT. the parallel library).
Also, you will want determine the cache requirements to determine the most effective number of threads to employ. This may require you to sort the sequences by sized where the smaller sized sequences could use more threads than the larger sized sequences.
As to what these numbers are, will depend on not only the system cache sizes but also the memory bandwidth.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the suggestions. I had forgotten to add that I can fix the length at will, so it is set to 2^n for n in the range 14-21. Also, it is a time-stepping code, so I cannot run the transforms in parallel (other than parallelizing a single transform which, I think, MKL takes care of). Has either of you experiences the complex-to-complex transform being faster than the real-to-real transform of the same length?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Out of curiosity, how long does it take for each timestep? Say for the 100,000 and 1,000,000.
And, how long does it take to run through all your timesteps?
I am trying to assess a trade-off between the amount of programming effort is warranted to attempt to improve the performance.
If any amount of time savings is of great importance, what you might (I stress might) be able to do is something similar to what I did in Chapter 5 of High Performance Parallelism Pearls. This break apart the processing sequencing of a time-step such that each portion of a time-step can be run in parallel. In other words, this is to pipeline the algorithm. In the case of the chemical diffusion program, I was able to partition each timestep into three parts and attain a 45% improvement on the larger problem sizes.
I haven't seen the internals of the code currently being used for FFT, nor have I seen what you may be doing inter-timestep, so I cannot assess the probability of pipelining your code.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
At this point, I measure about 0.015(s) per step. Each step requires two complex-to-complex FFTs of length n=2^19. The two transforms must be done on order. I am solving a PDE in one space dimension using a Semi-Implicit Backward Differentiation (SBDF) scheme that requires only a single evaluation of the right-hand side of the PDE per time step.
From that chapter I understood you are mapping out what variables are in what part of the cache in order to minimize cache misses, is that correct? If so, I am not sure if that is applicable. However, I did notice a huge improvement in performance in your code when adding SIMD instructions. That is where I might gain efficiency. Is there a part of the book (or another source) that explains how to do that properly?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@Barbara_P_Intel , having been in Northern Iowa with almost zero cell service for the best part of a week, it is pleasant to read these posts and not wonder what is happening in the outside world.
Re MKL, thank you for the smile, there are really only two to four people who comment intelligently on these sorts of problems. All of them are on this forum, so the MKL Forum is nice, but really this is the critical one.
I suggest you put up a sample file, I am interested as to why you need 500000 or so data points, the FFT is likely a mess to read.
With FFT it is better to move up a computer model than try and optimize code using the modern compilers and MKL.
One method is to break the FFT into parts, say 16384 and then do a lot, and use statistical analysis on the results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Consider me a noob on FFT usage.
From my little understanding of FFT usage I will make some assumptions.
One of the usages of FFT is for signal processing. The algorithms developed, eg. MKL and elsewhere, are written where you put a signal in (single sample of a signal for a duration of time). The FFT algorithm steps through a sequence of frequences, together with phase shifting, in order to construct a frequency domain list (frequency and probability at that frequency).
IOW the algorithms are not optimized for batches of signal samples (a batch be of different portions of a signal, overlapping or not, or entirely different signals).
The selected FFT will internally generate the candidate frequencies and phase shifts on each call to the algorithm. This is perfectly fine should the FFT function be called once or a few times.
It would seem then that there could be an optimization (tradeoff of memory vs runtime) where the candidate frequency tables are generated once (which can be referenced at different offsets for phase shifting), one table per candidate frequency.
This is analogous to making a harvest of random numbers, where the tables are created once, and referenced many times.
As to if this would increase performance, I cannot say. The multiple tables may introduce cache line miss overhead that exceed the computational gains (by not having to run through the sin an cos functions each iteration).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is rather surprising. I would expect the MKL FFT to use the classical Cooley-Tukey algorithm, which has a complexity of O(n log(n)) and is thus likely the bottleneck. If there exists anything more efficient I would love to learn about it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Let me clarify: I am using this for a pseudo-spectral time-stepping code for a nonlinear partial differential equation, not for data processing. The length of the sequence is fixed by bounds on the truncation error. If I make it much shorter, the simulation will become inaccurate and, ultimately, unstable. If this is a field you do not normally plow, essentially this is the algorithm: in each step we need to evaluate the linear part of the equation, which is best done in Fourier space where derivatives are scalar multiplications. We also need to evaluate the nonlinear term and that is best done on real space (i.e. on a grid) as it involves products of functions. To evaluate the linear term in real space would have complexity O(n^2), as would evaluating the nonlinear term in Fourier space. Since the FFT has a complexity O(n log(n)) it is more efficient to go back and forth. Therefore, in each time step, we need one backward and one forward transform. I use complex-to-complex transforms because I actually need two real-to-real transforms, backward and forward.
everything else in the code is O(n) so the FFTs are the bottleneck. I was hoping for experience users or Intel engineers to give me the long and the short of optimizing the complex-to-complex calls for n=100,000 - 500,000.
Then I came across the document I cited in my opening message and was mystified by the observation that the complex-to-complex function is FASTER than the real-to-real function, even though it should have about twice the number of FLOPs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The FFT algorithm is of a class of a convergence algorithm (iterative process to reach a solution). Apparently, convergence from two "sides" occurs in fewer steps that convergence from one "side".
Bear in mind that while the (MKL) FFT has lesser complexity than the linear term, introducing this may be causing a bottleneck into an otherwise parallelizable algorithm. Of course, there may be no better alternative.
From your description, a sketch of your code is:
loop (linear procedure, FFT procedure, FFT procedure, consolidate procedure)
While each procedure step is likely parallelable, there are two issues that arise:
1) You cannot overlap the transitions from procedure to procedure (lesser issue)
2) The thread teams used outside of the FFTs may be different from the thread teams inside the FFTs (greater issue).
I suspect that there may (stress may) be an advantage gained by extracting a good FFT algorithm out of a library, then pipelining the former list of procedures. This has the potential of eliminating the two aforementioned issues.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Fourier transform is complex numbered. The simplest available FFT is the '70s Fortran version of the Numerical Recipes. I would get Jim and the others to look at this early version and work out how can you make it as fast as possible, because it is as simple as possible. It is in the public domain or you can get it easily.
I still use this version as a check on new versions.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@JohnNichols @Van_Veen__Lennaert
I found this F90 FFT sample program
This is a test program, with timing of various calls.
This may or may not be optimized, but that is a different task.
For production code, you would use the procedures called by the test program. (Just the FFT part)
A few changes I would make:
1) The sample code has an upper limit on the input data points of 1000000. I would not place such a restriction. If you have enough memory, why not permit any size.
2) Considering that @Van_Veen__Lennaert will call repeatedly using the same sizes of arrays, any and all of the local work storage arrays would be allocated only once, or deallocated and re-allocated should the input size diminish. Note, a pointer to a section of the larger allocated arrays can be used should the size of the call diminish.
3) The w array (Omega) need only be calculated once (for the first of consecutive same input size).
4) Now this next change is questionable but is a good place to start to look for further optimizations.
From viewing several of the online educational videos, the FFT (or FT) is an iterative process that:
1) Finds the major (attenuation) frequency of the input signal, and subtracts that from the input signal (or into a copy buffer?)
2) Finds the next (attenuation) frequency of the input signal, (or by finding the major frequency of the copy buffer), and subtracts that from the input signal (or copy buffer).
3,4,5,...)And repeats this for the number of (attenuation) frequencies desired.
The optimization could possibly be that as the (attenuation) frequencies are determined, the result could be pipelined out of the FFT for concurrent processing by the next step in the caller's application.
Effectively the found frequencies outputs are asynchronously sent as they are determined.
Now, how this fits into @Van_Veen__Lennaert program usage that if calls two FFT operations back-to-back, I cannot say if the asynchronous outputs of the first FFT can be asynchronously fed into the second FFT, and if the second FFT's asynchronous output can be fed into the next stage of his code. This kind of thing is what I would be looking for.
|---input data processing---|
|----FFT-1 processing ----|
|----FFT-2 processing -----|
|----Next step processing-----|
The amount of time gained would depend on the degree of overlap (available concurrency) less the additional code for pipelining.
Can you get 2x, 1.5x, -2x!
And how large of potential performance gain makes it worth it to attempt the programming effort?
Note, the OpenMP has ORDERED and DEPEND clause (with dependency-types). These may help in the pipelining.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
To be honest, I do not understand points 1) through 4) on "attenuation frequencies". Perhaps you have a reference with more explanation?
As for the overlapping, that would unfortunately not work. The work flow is like this. Let uh be the discrete Fourier transform of a real-values function on a regular grid with n points. We want to evaluate a function on the grid, i.e. v_j=F(u_j). We follow the order:
uh --- backward FFT -> u -- evaluate F on grid --- forward FFT -> ...
so the evaluation of F on all grid points must be completed before entering the forward FFT.
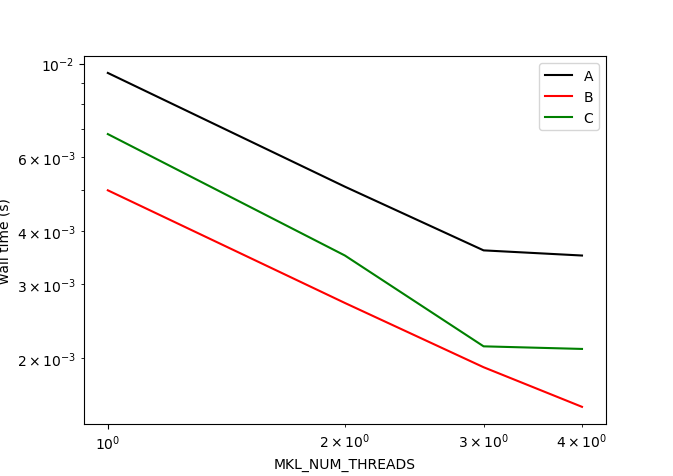
I bit the bullet and did some testing. I compared three transforms of length n=2^20. A is the complex-to-complex transform (forward or backward, same result). B is the real-to-complex (forward) transform (the image is complex-valued but has the "conjugate-even" symmetry and can be stored with n real numbers). Finally, C is the complex-to-real (backward) transform. I had my laptop (4 physical cores, 8 hyperthreads, 11th Gen Intel(R) Core(TM) i7-1185G7 @ 3.00GHz) perform a few hundred transfroms and took the average. I repeated the test for MKL_NUM_THREADS from 1 to 4 (at which point there is no more speed-up for this length of the transform).
I found that the complex-to-complex transform is consistently about 2 times slower than the real-to-complex transform, in line with the FLOP count. However, it is only about 1.5 time faster than the complex-to-real transform. I am not sure why, but I would guess there is an explanation based on the ways one can exploit the conjugate-even symmetry.
So, a bit disappointing. Using complex-to-complex both ways will save me wall time as compared to two real-to-complex and two complex-to-real transforms, but I do not see that factor of 2 that the publication I cited above found.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>Core(TM) i7-1185G7
That system has two memory channels, 12MB "smart cache".
The person that wrote the article stated:
>> It consists of 4920 compute nodes each containing two 12-core Intel E5-2697 v2
And I did not locate much more about his configuration.
Assuming he used only one node.
That node (2 sockets) had a total of 8 memory channels (4 each CPU). And 60MB cache (30 each CPU).
We do not know it he used 1 or 2 of the CPUs on a node, nor the thread count and placement. He did state that he disabled kmp_affinity.
This leads be to believe that whatever thread count he used, it was (permitted to) spread over the 2 CPUs.
The amount of cache and memory channels as used by him verses that available to you must be the factor for the observed difference in relative performance.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is a very interesting and helpful suggestion. I will run this code on a cluster with a range of different nodes, so I will spend some time finding the nodes with the best cache/memory configuration. Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I came across an interesting video on YouTube. I do not know if this might be useful in partitioning the execution of the application.
Dirichlet Invented this Function to Prove a Point
It talks about what happens with (how to handle) Fourier series at discontinuities.
In your case, partitioning the sample data would present (I presume) very small discontinuities.
Years ago, I posted an article/post in response someone making the statement that some algorithms are simply not parallelizable. Unfortunately, those at Intel running the forum and articles decided a cleanup was in order and threw out a lot of content.
The problem was the inclusive scan, where the elements of an array are processed in order and each step depends on the output of the prior step. I took that as a challenge and rewrote the simplified algorithm to produce a parallel version that ran faster.
Attached is the code (as of 4/13/2015).
Maybe you can learn that "impossible to parallelize" is not always true.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page