- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello!
I have very big problems with parallelism on my laptop. I've written simple OpenMP parallel program like
#pragma omp parallel num_threads(8)
#pragma omp for schedule(static)
<arithmetics>
and then Hotspots analysis have revealed that parallelism is very bad. Debug version runs for a relatively long time, but it has at least some parallelism (can't attach pictures due to an error on this site :( ). Release version is much faster, but it has no parallelism at all. By the way, microarchitecture exploration analysis revealed that I have many problems with hardware (for example, bad Front-End Bound parameters).
I have no idea why parallelism is so bad even for simple arithmetic program :( The model of laptop is Acer Nitro AN515-51
P.S. I have Windows 10 and NetBeans with MinGW compiler.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Griogrii,
Thanks for reaching out to us.
Could you please give more information about your laptop configuration. Kindly, give your scripts or workload that you are trying out. So that we can try it from our end.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Chithra_Intel,
thank you for your response!
Tell me, please what kind of information are you interested in?
As I said, the model of laptop is Acer Nitro AN515-51 and CPU is Intel(R) Core(TM) i7-7700HQ.
I am trying to run simple arithmetic program:
#include <stdio.h>
#include <iostream>
#include <math.h>
#include <omp.h>
using namespace std;
int main(int argc, char* argv[])
{
double a[100000];
#pragma omp parallel num_threads(8) //number of threads is varied
{
#pragma omp for schedule(static)
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 20000; j++){
a = 0;
a++;
a = a / (a+0.3424782);
a=sqrt(a);
}
}
}
cout<<a[0]<<" "<<a[12900]<<" "<<a[46540]<<" "<<a[78706]<<" "<<a[99000]<<" "<<a[99909]<<" "; //checking the correctness of the work
return 0;
}
HW-based Hotspots analysis has revealed that for 8 threads, for example, I have 31.4% parallelism anf 57.3% microarchitecture usage.
(To my great regret, I can't attach screen of histogram due to technical problem in this site, but it is terrible:
1 logical CPU column is very high, 2-7 logical CPU columns are low and 8 logical CPU column is empty :( ).
But then I tried to test parallelism manually and obtained contradictory results.
These are the results of computation with different number of threads (number of threads - corresponding execution time):
Debug
1 74s
2 38s
4 20s
8 11s (22.8s with Intel VTune Profiler and scary histogram)
(parallelism is almost ideal !)
Release
2 47-53? ms
4 53-58? ms
8 47-69? ms
(? means big range of values)
(Release runs faster than Debug, but has no parallelism; -fopenmp is enabled)
So, in Debug case maybe the problem is in some Intel Vtune Profiler Options? I run it as an administrator.
However, causes of problems in Release mode are still unclear. It is interesting that the time of execution doesn't change with the change of maximum of j parameter.
But if some actions with j are added (for example the 3 row of cycle is changed to a = a / (a+0.3424782+(j*1.0/10000));), all of the problems disappear:
Release (jmax 20000->100000)
1 47s
2 24s
4 16s
8 11s (22.6s with Intel VTune Profiler and scary histogram analogous with the descripted above)
(parallelism is good but not ideal, it is strange)
So, I think that the trouble may be in compiler optimization. The compiler understands that cycle with j is useless and just skips it.
The compilation row from Netbeans:
g++ -fopenmp -c -O2 -std=c++11 -MMD -MP -MF "build/Release/MinGW-Windows/main.o.d" -o build/Release/MinGW-Windows/main.o main.cpp
Summary:
1) Why program runs slower with Intel VTune Profiler and has worse parallelism than if I run it manually? (in both Debug and Release modes)
My idea: I should change some options of Intel VTune Profiler. I run it as an administrator.
2) Why Release mode has no parallelism in some cases?
My idea: compiler understands that some job is useless and just skips it.
3) Why I have unideal parallelism in Release mode with actions with j even for such a simple arithmetic program with almost 100% parallel actions?
Have no good ideas.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Griogrii,
We are trying this from our end and will get back to you with the updates soon.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi!
I have obtained that Profiler slows programs only in HW-based Hotspots analysis. In User-Mode all work correct (parallelism and histogram is almost ideal).
However, questions I've mentioned above are still actual.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
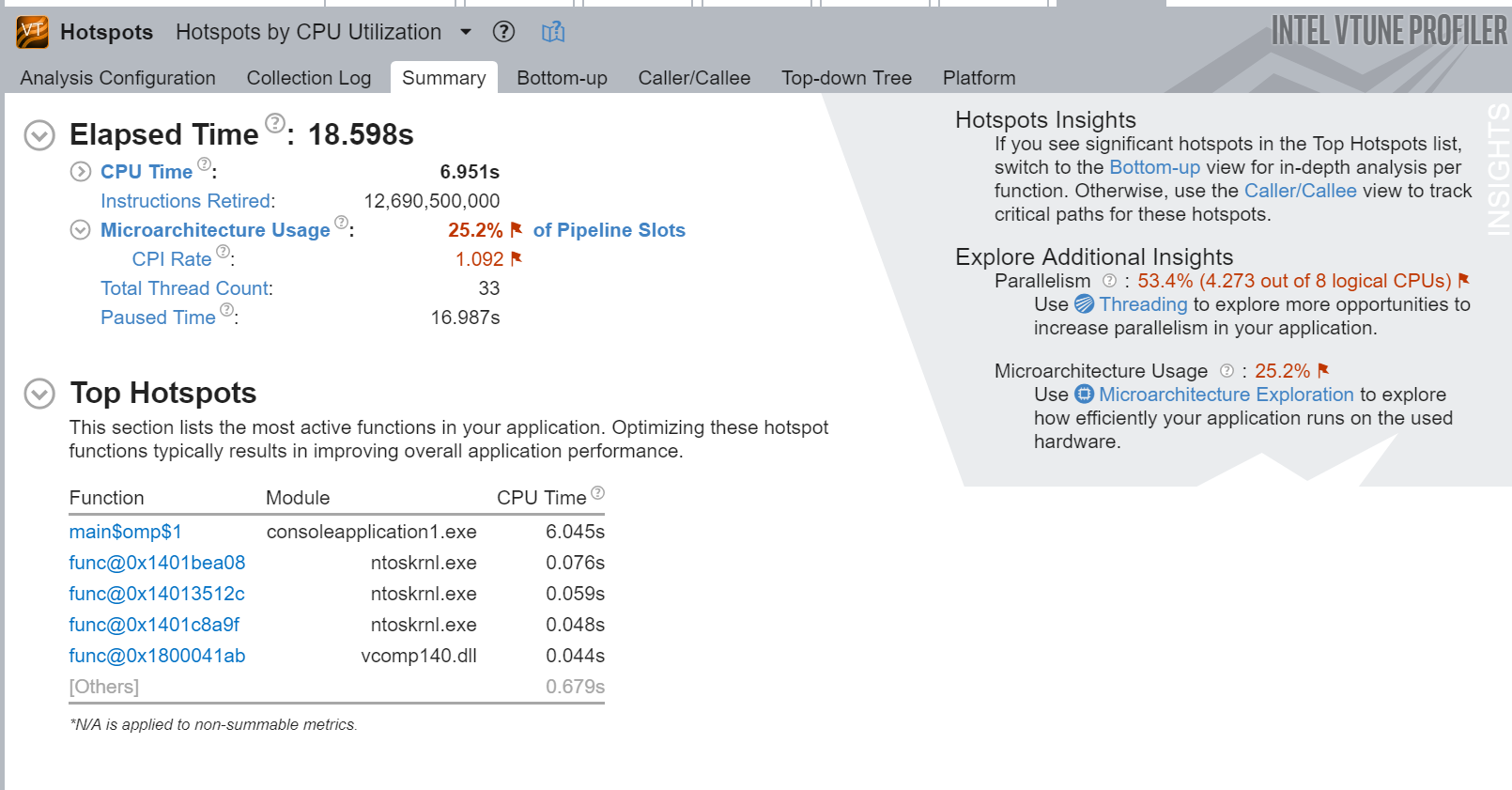
Hi Grigorii,
We tried to take the H/w event based hotspots analysis for your application and able to see the same behavior as noticed by you (Please refer to the screenshots of the vtune summary page attached). So, we had informed this issue to SME and checking this internally.
As you said, the overhead will be more in h/w based profiling compared to user mode sampling, since it has to monitor and collect the underlying h/w events. So, could you please let me know the percentage of difference you observed in h/w based and user mode sampling.
Thanks.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Chithra_Intel,
thank you for your response!
It seems that user mode sampling analysis affects weakly on the execution time and hw-based analysis prolongs it for about 2 times.
However, questions 2 and 3 are still very actual for me:
2) Why Release mode has no parallelism in some cases?
My idea: compiler understands that some job is useless and just skips it.3) Why I have unideal parallelism in Release mode with actions with j even for such a simple arithmetic program with almost 100% parallel actions?
Have no good ideas.
Should I open a new thread?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grigorii,
The few insights/thoughts we got from SME's on your queries are:
- Release mode guarantees compiler’s O2 optimizations but it is not necessary you will get better threading in Release mode compared to Debug mode. Compiler may have made the choice to generate less user threads or may have engaged less CPU cores.
- What ultimately matters is the improvement in elapsed time in both modes.
- The total parallelism in summary pane is cumulative result of user + supporting kernel level threads, so it can’t indicate a true picture of parallelism for the application. Probably for your application, user mode sampling is doing a better job by eliminating kernel threads.
Is this clarifies your 2nd query?
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Chithra_Intel,
thank you very much for your response!
Yes, it clarifies my 2nd question.
I want to inform you about my progress in 3rd question. I was advised to disable hyper-threading function to increase parallelism on my laptop. If I'm not mistaken, it should be done in BIOS. However, there is no hyper-threading option in BIOS on my laptop. I've asked Acer about it and the answer was that this setting isn't provided.
Tell me, please if idea about hyper-threading is correct and I correctly understand that problems are connected to hardware and can't be solved.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grigorii,
Thanks for your response. Please look into few points/answers for your queries:
Q:Why program runs slower with Intel VTune Profiler and has worse parallelism than if I run it manually? (in both Debug and Release modes)
Answer: Actually, the elapsed time you observed in the Vtune summary page is the cumulative result of Idle time( In which CPU doesn't do any useful works) and runtime of the application(Where CPU is utilizing). So, in order to get the actual runtime of your application, do:
Elapsed time - Idle time(The first bar in the CPU utilization histogram indicates the idle time where no logical cpu cores are used) = Runtime of the application.
Now, compare this result with the elapsed time you got after running the application without Vtune and this should be comparable. Please let me know whether you are getting comparable result.[Note: please share the results, if possible with snapshots]
Q: Why I have unideal parallelism in Release mode with actions with j even for such a simple arithmetic program with almost 100% parallel actions?
Answer: Compiler optimization happens only in release mode. In your code, without including any operations with 'j' variable, compiler assumes it as dead variable. So, it will perform some optimizations like merge/fuse the loop or something.(Don't know exactly what compiler is doing).
So, we are looking to generate compiler report for getting more picture of this & what happens while introducing actions with 'j' variable. We will give you the updates on this later.
Q: Disabling hyper threading function will improve parallelism or not?
Answer: Currently, we don't have ideas on this.But,while analyzing your application with Vtune, we were able to see that the application performance is good in terms of parallelism.It would be better to stick on User-mode sampling(Hotspots) or do user mode threading analysis to get more detailed information about parallelism. Because, the H/w based hotspots analysis also collects the kernel level threads along with user threads, the parallelism in summary pane can't indicate a true picture of parallelism.
(Link for threading analysis: https://software.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/parallelism-analysis-group/threading-analysis.html).
If possible, could you please share the snapshots of the bottom-up timeline pane for H/w based and User mode sampling results( Both debug and release mode) for detailed analysis.
Hopes this clarifies your some queries.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Chithra_Intel,
thank you very much for your response!
I'm sorry, but I am extremely busy right now and have a lot of another problems. I truly appreciate your help and will try to provide information you ask as soon as possible.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
1. There is no sense to profile a debug version without optimizations. Better would be release+debug info.
2. The loop body does not depend on j, so only 100000 iterations are executed in the release mode.
3. it would be better to gather concurrency collection and look at imbalance details, not summary. it looks you have imbalance on the end of parallel region.
Bottom line: IMO low amount of work + imbalance shows summary pictures you see.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grigorii,
Please let us know that your queries get clarified or not. So, we can close the thread. If not, please share the requested details.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Grigorii,
We are closing the case by assuming that your queries get clarified. Please feel free to raise a new thread if you have further issues.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page