- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I'm working on following processor.
Intel Xeon X5365 3.0GHz ( code name : Clovertown)
L1 Cache : 32KB
L2 Cache: 4MB
I want to find the usage of VTune to measure different stalls and bottleneck.
First I calculated the size of square matrices (# of Matrices are three ) that would be fit in L1 and L2 cache combined.
Please find the calculation below, correct me if I'm wrong.
L2 size 4194304 (4MB of Cache)
L1 Size 32768 (32KB of Cache)
Total # of float element fit in L1 and L2 Cache 1,056,768
# of Elements for each matrix (# of Mats 3) 352256
Row size for each square Matrices(# of Mats 3) 593.51
Just to start with matrix multiplication program to estimate the theoretical cache misses and # of cache miss events reported by VTune. I interchanged i,j,k loop so that H/W prefetcher should not detect the pattern.
As per my understanding, three floating point matrices of size 512 will completely fits into L2 cache. We have 64 bytes of cache line size, it means each cache miss will fetch 16 element from physical memory to cache. So for one matrix the # of cache misses will be 16384 ((512* 152)/16 = 16384), means for three matrices total # of cache misses will be 49152 ( 16384 * 3 = 49152)
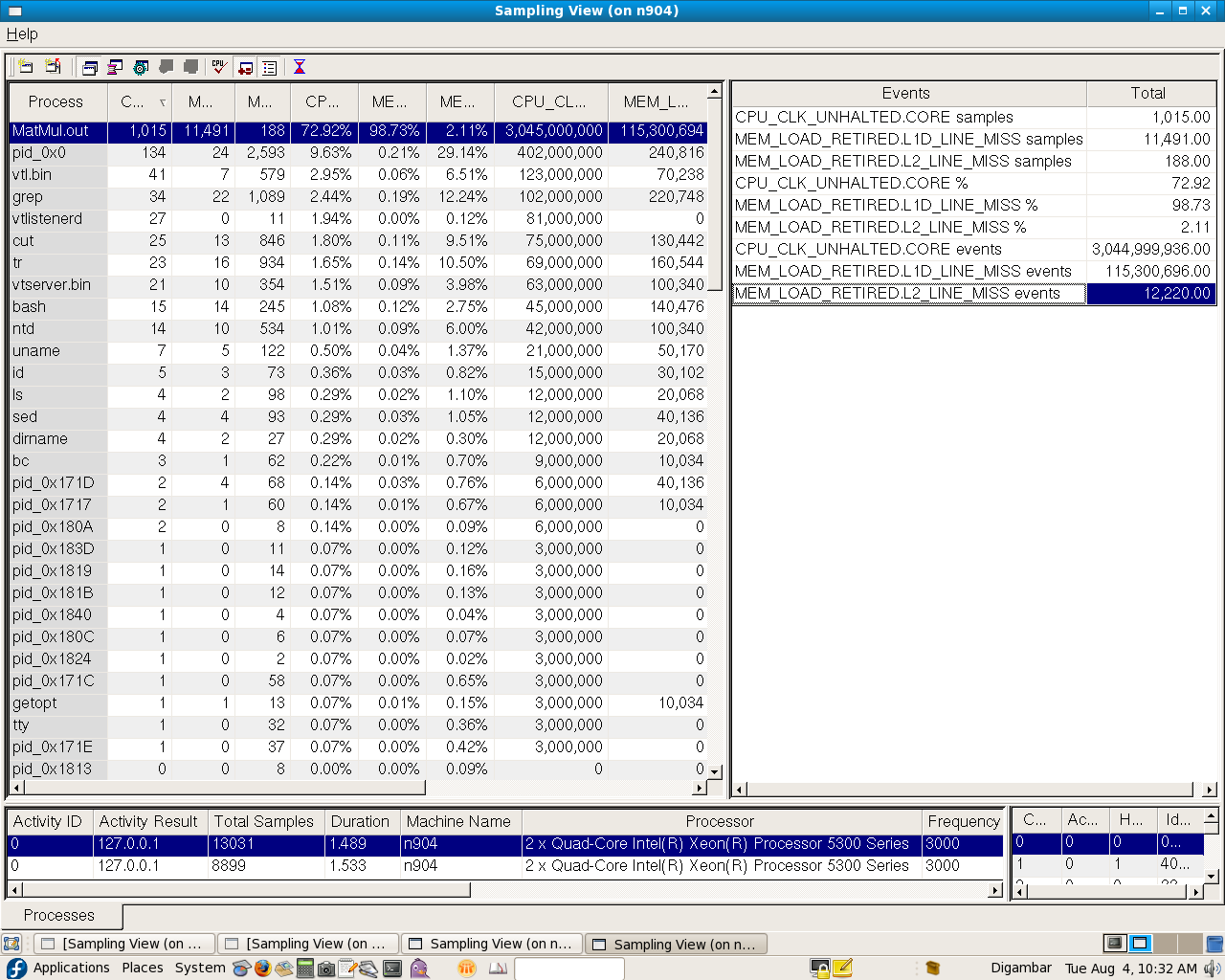
But I observed that VTune is reporting very less number L2 cache misses ~= 13400.
Please find the test code I used and the screenshot of VTune numbers (two activities just to cross check the numbers).
Can you please give some suggestions for this?
Regards,
Dny,
{kind=link}
{kind=link}
Link Copied
6 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Optimizing compilers should include loop nest optimization. You should be able to see in the asm view whether that has happened.
I would expect that the 2nd sector prefetch would work as intended in a case like this, so that effective cache line size would be doubled. If you are trying to separate the effect of the hardware prefetchers, you might try to shut them off. Of course, documentation on that is weak.
I don't believe the L1 and L2 cache are exclusive, as you appear to have assumed, but I suppose that's not material to your question.
I would expect that the 2nd sector prefetch would work as intended in a case like this, so that effective cache line size would be doubled. If you are trying to separate the effect of the hardware prefetchers, you might try to shut them off. Of course, documentation on that is weak.
I don't believe the L1 and L2 cache are exclusive, as you appear to have assumed, but I suppose that's not material to your question.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dny,
You can use the events L2_LINES_IN.SELF.DEMAND and L2_LINES_IN.PREFETCH to measure how many cache lines are brought in by cache misses and how much the prefetcher gets for you. I also second Tim's suggestion to disable the prefetcherto cross-check your assumptions, which usually can be done in the BIOS. It might also be worth noting that hardware prefetchers nowadays can also detect regular strides.
There are further events like L2_LD.SELF.DEMAND.I_STATE or L2_LD.SELF.PREFETCH.I_STATE, which you can put in relation to L2_LD.SELF.DEMAND.S_STATE, L2_LD.SELF.DEMAND.M_STATE, and so on. Using these events, you should be able to get a fairly good picture of what is going on in the L2 cache.
Kind regards
Thomas
You can use the events L2_LINES_IN.SELF.DEMAND and L2_LINES_IN.PREFETCH to measure how many cache lines are brought in by cache misses and how much the prefetcher gets for you. I also second Tim's suggestion to disable the prefetcherto cross-check your assumptions, which usually can be done in the BIOS. It might also be worth noting that hardware prefetchers nowadays can also detect regular strides.
There are further events like L2_LD.SELF.DEMAND.I_STATE or L2_LD.SELF.PREFETCH.I_STATE, which you can put in relation to L2_LD.SELF.DEMAND.S_STATE, L2_LD.SELF.DEMAND.M_STATE, and so on. Using these events, you should be able to get a fairly good picture of what is going on in the L2 cache.
Kind regards
Thomas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quoting - Thomas Willhalm (Intel)
Dny,
You can use the events L2_LINES_IN.SELF.DEMAND and L2_LINES_IN.PREFETCH to measure how many cache lines are brought in by cache misses and how much the prefetcher gets for you. I also second Tim's suggestion to disable the prefetcher to cross-check your assumptions, which usually can be done in the BIOS. It might also be worth noting that hardware prefetchers nowadays can also detect regular strides.
There are further events like L2_LD.SELF.DEMAND.I_STATE or L2_LD.SELF.PREFETCH.I_STATE, which you can put in relation to L2_LD.SELF.DEMAND.S_STATE, L2_LD.SELF.DEMAND.M_STATE, and so on. Using these events, you should be able to get a fairly good picture of what is going on in the L2 cache.
Kind regards
Thomas
You can use the events L2_LINES_IN.SELF.DEMAND and L2_LINES_IN.PREFETCH to measure how many cache lines are brought in by cache misses and how much the prefetcher gets for you. I also second Tim's suggestion to disable the prefetcher to cross-check your assumptions, which usually can be done in the BIOS. It might also be worth noting that hardware prefetchers nowadays can also detect regular strides.
There are further events like L2_LD.SELF.DEMAND.I_STATE or L2_LD.SELF.PREFETCH.I_STATE, which you can put in relation to L2_LD.SELF.DEMAND.S_STATE, L2_LD.SELF.DEMAND.M_STATE, and so on. Using these events, you should be able to get a fairly good picture of what is going on in the L2 cache.
Kind regards
Thomas
Hello Sir,
Thanks for your reply.
I will definitely try using events you suggested. for all thease test cases I'm using iccc 11.0 and I turn off any compiler optimization O0 flag.
icc -O0 Add.c -o Add.out
For another very simple test case I tried counting cache misses for a loop of calculating sum of matrix elements
I had taken array size of 1024 which should fit completely in cache, then initialize and calculate the sum.
I calculated the theoretical cache miss which should maximum of (2048, if we consider cache miss for every element and two for loops), but I observed that the L1 cache misses are massively greater than the total number of elements in array.
For 1024 element cache misses reported by VTune are approx 30,000, which should not be possible in any case.
The total cpu cycles are correct as I calculated using total run time.
Its very surprising to see this result.
Also why the cache miss numbers are changing for two consecutive runs.
Please find the test code and VTune output.
Thanking you,
Regards,
Dny
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quoting - Dny
Hello Sir,
Thanks for your reply.
I will definitely try using events you suggested. for all thease test cases I'm using iccc 11.0 and I turn off any compiler optimization O0 flag.
icc -O0 Add.c -o Add.out
For another very simple test case I tried counting cache misses for a loop of calculating sum of matrix elements
I had taken array size of 1024 which should fit completely in cache, then initialize and calculate the sum.
I calculated the theoretical cache miss which should maximum of (2048, if we consider cache miss for every element and two for loops), but I observed that the L1 cache misses are massively greater than the total number of elements in array.
For 1024 element cache misses reported by VTune are approx 30,000, which should not be possible in any case.
The total cpu cycles are correct as I calculated using total run time.
Its very surprising to see this result.
Also why the cache miss numbers are changing for two consecutive runs.
Please find the test code and VTune output.
Thanking you,
Regards,
Dny
Hello,
For this test case I'm focusing on L1 cache misses.
During futher expriment, I added a bigger outer loop to my original loop of calculation sum, to increase the runtime of test case.
#define SIZE 1024
int main(int argc, char *argv[])
{
float a[SIZE];
int i,k=0,j;
float sum=0;
for(i=0;i
k=(k+1)%10;
}
for ( j =0 ; j < 2*SIZE *SIZE ; j++){
sum=0;
for ( i =0 ; i < SIZE ; i++){
sum+=a;
}
}
printf("n # of Iterations=%d, # of Element= %d, Sum = %fn",j,SIZE, sum );
printf("n Addition Completen");
return 0;
}
Following are my calculations and learnings
Array size = 1024
Total Memory required for array = 4196 Byes
It will use only 13% of total L1 cache (32KB), so my assumption is that all the elements of array should be in L1 cache after first loop of initialization. Second loop is computing the sum of array element.
If we add a bigger outer loop to this, it should not increase the L1 cache misses (Since all the elements of array are in L1 cache).
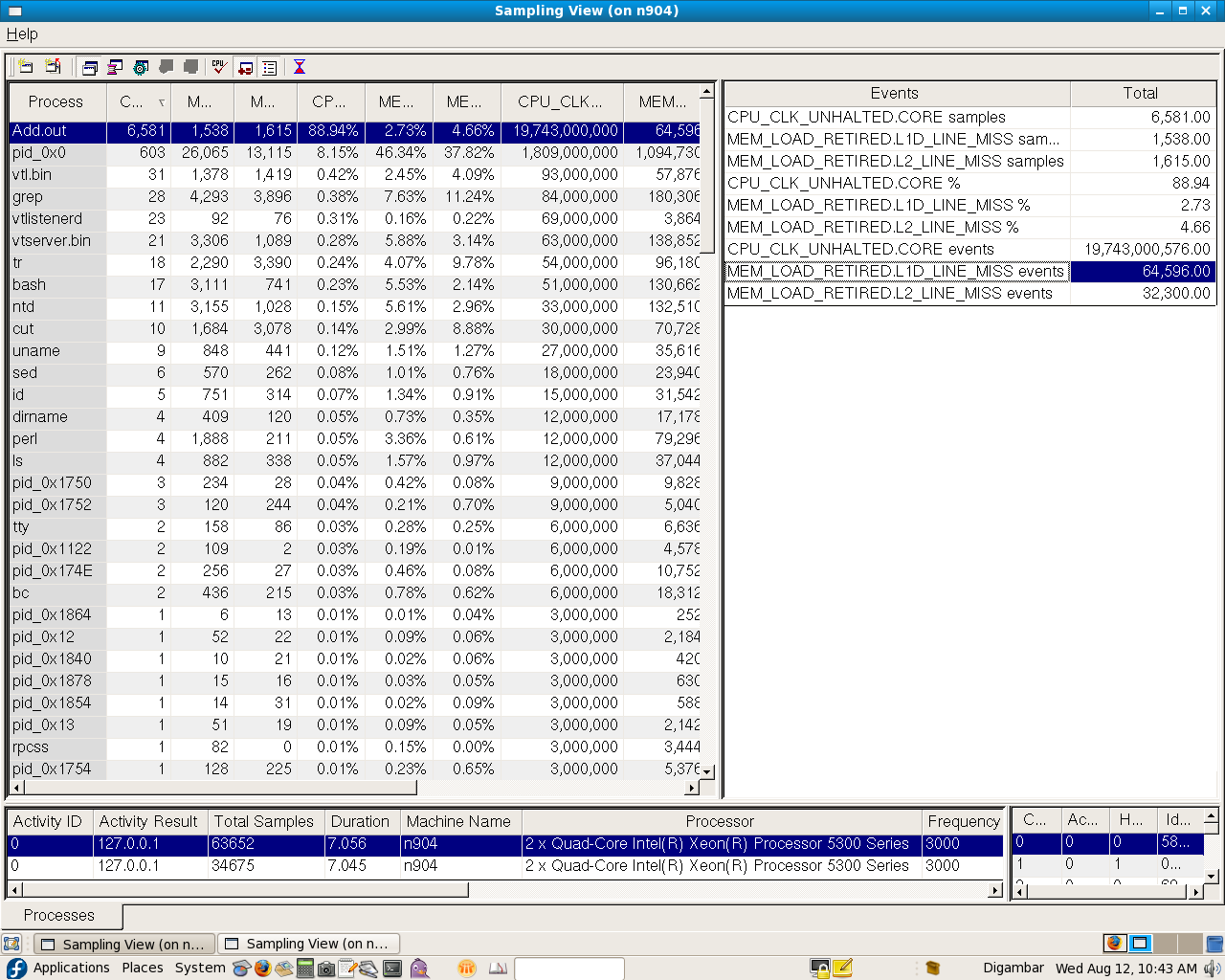
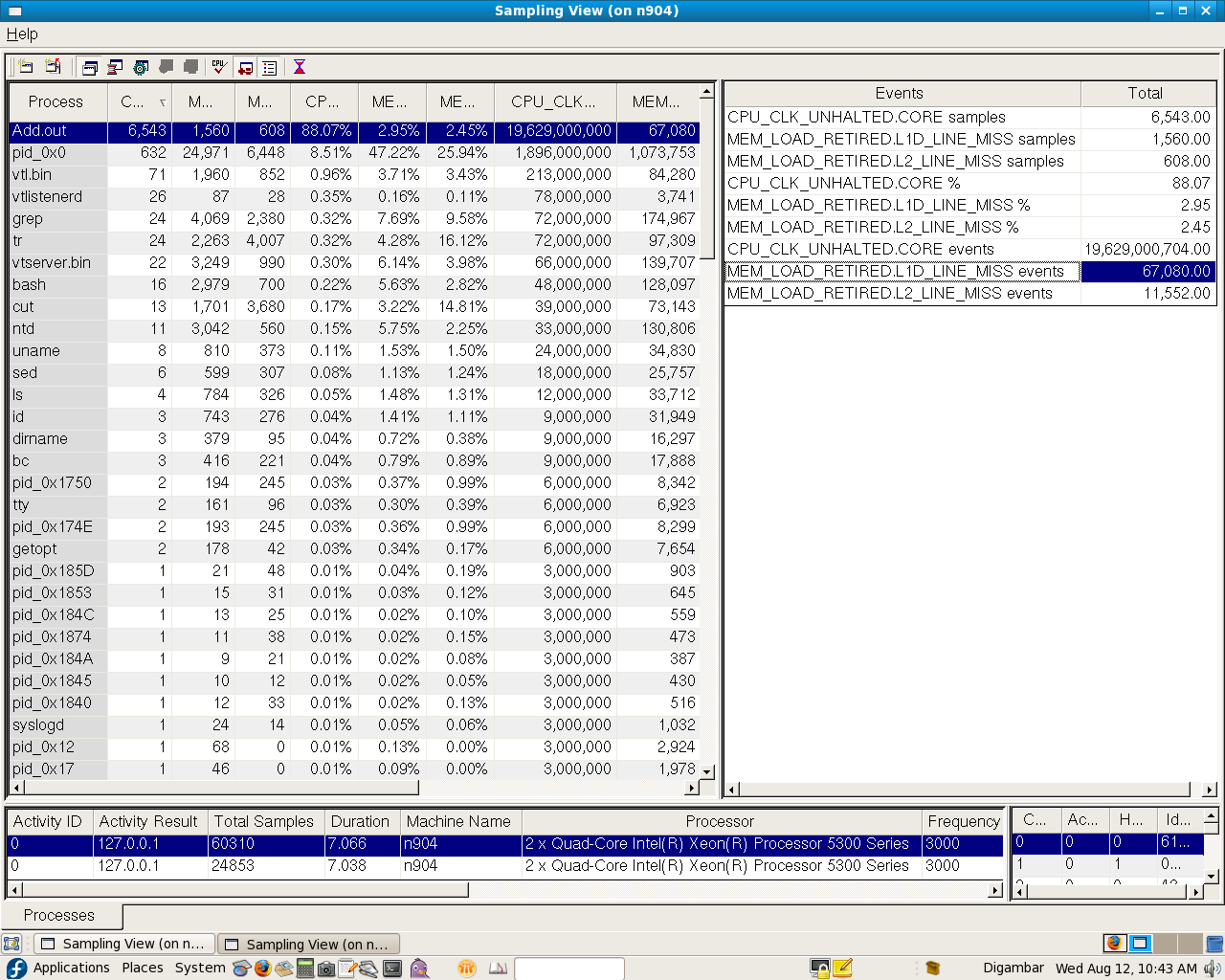
I observed that after adding outer loop L1 cache misses doubled.
I'm very surprised with numbers reported by VTune.
Can you please give your suggestion for this ?
Thanking you,
Regards,
Dny
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quoting - Dny
Hello,
For this test case I'm focusing on L1 cache misses.
During futher expriment, I added a bigger outer loop to my original loop of calculation sum, to increase the runtime of test case.
#define SIZE 1024
int main(int argc, char *argv[])
{
float a[SIZE];
int i,k=0,j;
float sum=0;
for(i=0;i
k=(k+1)%10;
}
for ( j =0 ; j < 2*SIZE *SIZE ; j++){
sum=0;
for ( i =0 ; i < SIZE ; i++){
sum+=a;
}
}
printf("n # of Iterations=%d, # of Element= %d, Sum = %fn",j,SIZE, sum );
printf("n Addition Completen");
return 0;
}
Following are my calculations and learnings
Array size = 1024
Total Memory required for array = 4196 Byes
It will use only 13% of total L1 cache (32KB), so my assumption is that all the elements of array should be in L1 cache after first loop of initialization. Second loop is computing the sum of array element.
If we add a bigger outer loop to this, it should not increase the L1 cache misses (Since all the elements of array are in L1 cache).
I observed that after adding outer loop L1 cache misses doubled.
I'm very surprised with numbers reported by VTune.
Can you please give your suggestion for this ?
Thanking you,
Regards,
Dny
Hello All,
Please please reply to my queries.
Its a big bottleneck for my analysis using the VTune for my other application. I'm running thease test cases only to understand the VTune event numbers.
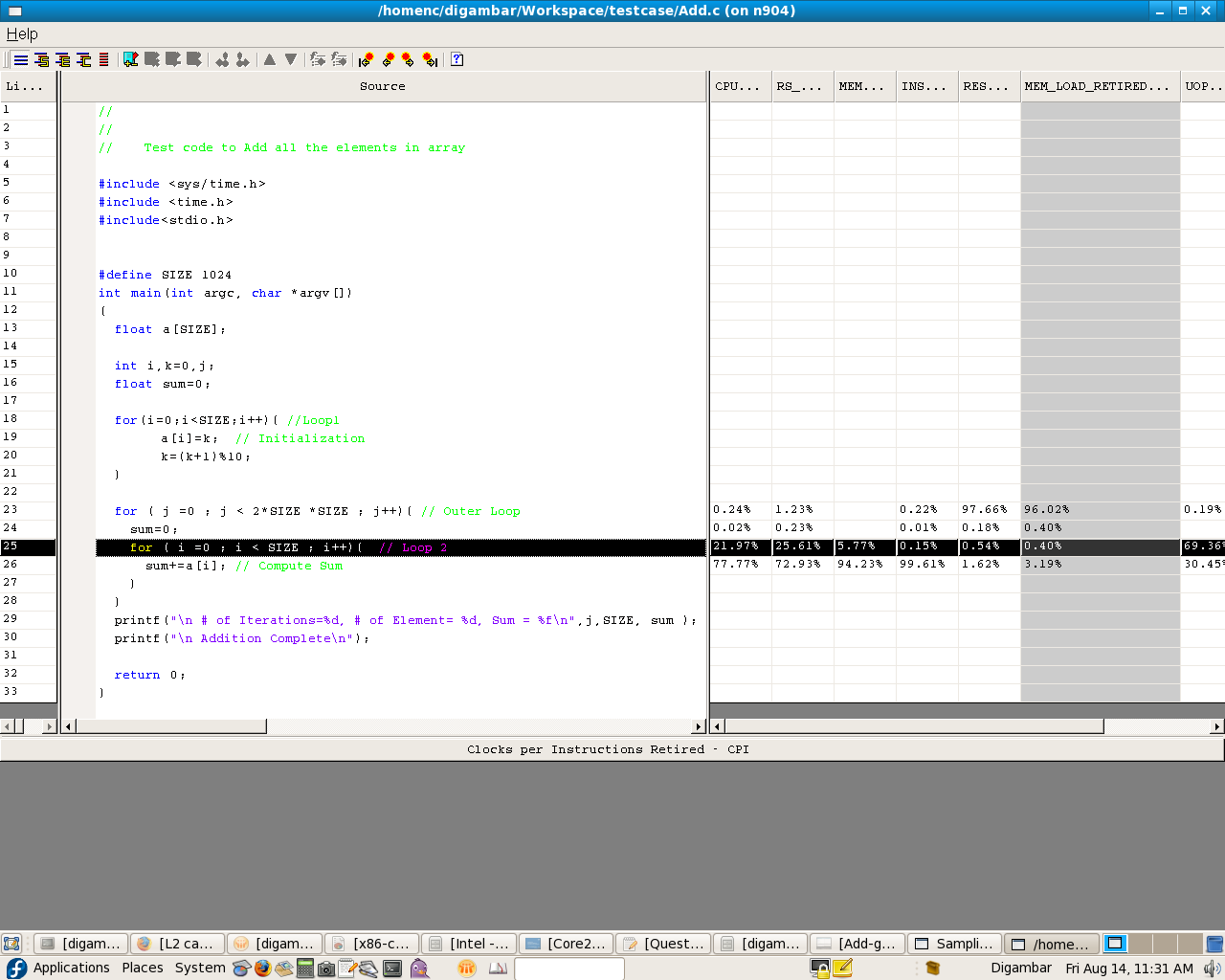
I observed that in source code view of VTune, for loop at line 23 its showing 96% of of L1 cache misses, but loop from line 18 to 21 , does not contributing to any cache misses (Ideally it should cause majority of L1 cache missses).
I'm not able to understand this behaviour, why does incl instruction is causing 45% of L1 cache.
Can you please give some suggesion for this ?
Thanking you,
Regards,
Dny
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Quoting - Dny
Hello All,
Please please reply to my queries.
Its a big bottleneck for my analysis using the VTune for my other application. I'm running thease test cases only to understand the VTune event numbers.
I observed that in source code view of VTune, for loop at line 23 its showing 96% of of L1 cache misses, but loop from line 18 to 21 , does not contributing to any cache misses (Ideally it should cause majority of L1 cache missses).
I'm not able to understand this behaviour, why does incl instruction is causing 45% of L1 cache.
Can you please give some suggesion for this ?
Thanking you,
Regards,
Dny
Could you check my response on http://software.intel.com/en-us/forums/showthread.php?t=67659
With slight modification of my response with above link, you can conclude the solution for this thread too.
Let me know if you have problem still.
~BR
Mukkaysh Srivastav
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page