- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We tried running our own ResNet model to detect heart arrhythmias (from 30 seconds of ECG data) on the NCS2 connected to a Raspberry pi. We obtained a pre-trained Keras model (in FP32) in hdf5 format, loaded the model and froze the graph, then saved a PB text file (tensorflow). We then used the openvino toolkit for Ubuntu (using Ubuntu 18.04) to convert the model to IR format, using the following command "python3 mo_tf.py --input_model <FILE NAME>.pbtxt --input_model_is_text --data_type=FP16 -b 1". The model was converted successfully, however the converted model does not perform correct inference. We ran the setup on the NCS2 on a raspberry pi(raspbian) and each time, we got a different result for the same input ( with the probabilities completly wrong).
All the files( network, converted files and scripts)
https://drive.google.com/open?id=1uzCFJ1ogryxzkwmqZUO2XS1LT3YQvhsO
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Men, Prit,
First, please make sure you're using the latest OpenVino 2019R1.1.
Does inference work properly without OpenVino ? Did you try running the regular frozen pb with TensorFlow inference ? Are the probabilities correct ?
Also when you create IR, do you need to include any of the following switches ? Often times when inference happens incorrectly, it's because improper IR was generated. IR may in fact get easily generated through a simple mo command, but it may still be wrong IR.
--scale SCALE, -s SCALE
All input values coming from original network inputs
will be divided by this value. When a list of inputs
is overridden by the --input parameter, this scale is
not applied for any input that does not match with the
original input of the model.
--mean_values MEAN_VALUES, -ms MEAN_VALUES
Mean values to be used for the input image per
channel. Values to be provided in the (R,G,B) or
[R,G,B] format. Can be defined for desired input of
the model, for example: "--mean_values
data[255,255,255],info[255,255,255]". The exact
meaning and order of channels depend on how the
original model was trained.
--scale_values SCALE_VALUES
Scale values to be used for the input image per
channel. Values are provided in the (R,G,B) or [R,G,B]
format. Can be defined for desired input of the model,
for example: "--scale_values
data[255,255,255],info[255,255,255]". The exact
meaning and order of channels depend on how the
original model was trained.
--reverse_input_channels
Switch the input channels order from RGB to BGR (or
vice versa). Applied to original inputs of the model
if and only if a number of channels equals 3. Applied
after application of --mean_values and --scale_values
options, so numbers in --mean_values and
--scale_values go in the order of channels used in the
original model.
Please report back here. And thanks for using OpenVino !
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Shubha,
Thank you for reverting back.
With regards to the questions you had posted, we are using the latest iteration of OpenVino on the raspberry pi (downloaded 2-3 weeks ago). With regard to the pb file, we recognised that there were some discrepancies between the actual results and what the program outputted. Regarding that, we wanted to ask if the method utilised on this page:
https://docs.openvinotoolkit.org/latest/_docs_MO_DG_prepare_model_convert_model_Convert_Model_From_TensorFlow.html
would always work when converting to a pb file(frozen). This is what we followed and have some indiscrepancies. Would it be better to convert to a meta-graph ( a non frozen method)?
Prithvi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
For the third comment, we do not use any of the options listed above but use --data_type=FP16. Do you recommend we use the options above or any of the ones on the 'converting a tensorflow file' page?
Prithvi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear all,
Yesterday we even made our own Tensorflow model ( using the Tensorflow Estimator API) as we thought it might be the Keras to Tensorflow file that might be causing problem. We trained the model and got the correct inference however, when we tried it with the compute stick, we got the wrong result yet again.
The new tensorflow file is on the drive:
https://drive.google.com/open?id=1uzCFJ1ogryxzkwmqZUO2XS1LT3YQvhsO
and this time, we tried the metagraph and saved model types of file to no avail.
If you could help us, that would be great. The final thing we are looking at it is how we are running the inference script and if you have an example and could share it, that would be great.
Thanks
Prithvi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Men, Prit,
The suggestion I gave you above --scale, --mean_values etc...should be given as hints to Model Optimizer, that is - if you even know what values to put there. The person who builds/trains the model should know what values to use in those switches. These switches should be used in addition to the switches defined in the 'converting a tensorflow file' page.
A frozen pb versus a meta file should not make a difference in the results.
Can you kindly do me a favor ? Don't run on Raspberry PI for now. Let's keep it simple. Re-do your Model Optimizer command leaving out --data_type=FP16. That way it will build for FP32 (default). Re-run your inference on CPU. Does it work ? Another thing to try, leave Raspberry Pi out of it. Just run your myriad stick as a USB on Linux or Windows (FP16).
There are plenty of examples in the OpenVino installation, both Python and C++. What kid of inference does your Resnet model run ? Classification I suppose ?
Also, if you're using an OpenVino from 3 weeks ago, that is already old (for non-raspberry pi anyway). We just released OpenVino 2019R1.1 last week. I promise to take a look at your code soon. I haven't had a chance to do so yet.
You're probably using this version of raspberry pi correct ?
https://download.01.org/opencv/2019/openvinotoolkit/
Hope it helps,
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hwy there Shubha,
We decided to try the inference on a Linux computer ( without Myriad and on a Virtualbox) howvever, I get the error:
Unsupported primitive of type: ArgMax name: ArgMax.
Also when trying to run the on the Movidius (linux virtualbox), I get the error that the deivce was not found.
All the openvinos have been updated to the latest version ( 2019.1.144) for both linux and raspberry pi. We are running a resnet model for classification ( heart arrythmia detection). On the google drive, we have the script for the inference file and this is the only part we think might be causing a problem.
https://drive.google.com/open?id=1uzCFJ1ogryxzkwmqZUO2XS1LT3YQvhsO
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Shubha,
I also checked Openvino's supported layers and Argmax is supported on both CPU and Myriad
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Men, Prit,
Please study this thread to fix your virtual box issue:
https://software.intel.com/en-us/forums/computer-vision/topic/805215
Someone says:
It seems NCS2 USB device ID changes when script starts loading model to MYRIAD.
I was able to resolve it by adding a new USB device filter with VID= 03e7 and PID=f63b in addition to VID= 03e7 and PID=2485 in Virtualbox USB settings.
*.148 is the latest Linux release. 144 is old. Please retry your code on CPU and Myriad (no Raspberry Pi) with *.148 and post back here.
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Shubha,
With regards to the virtual box, I have done that step yet to no avail.
With regards to the linux version, I did a fresh installation today and the latest version is 2019_1_144.
Link: https://registrationcenter.intel.com/en/products/postregistration/?sn=CNP6-S4757DV9&EmailID=pritmister%40gmail.com&Sequence=2474365&dnld=t#
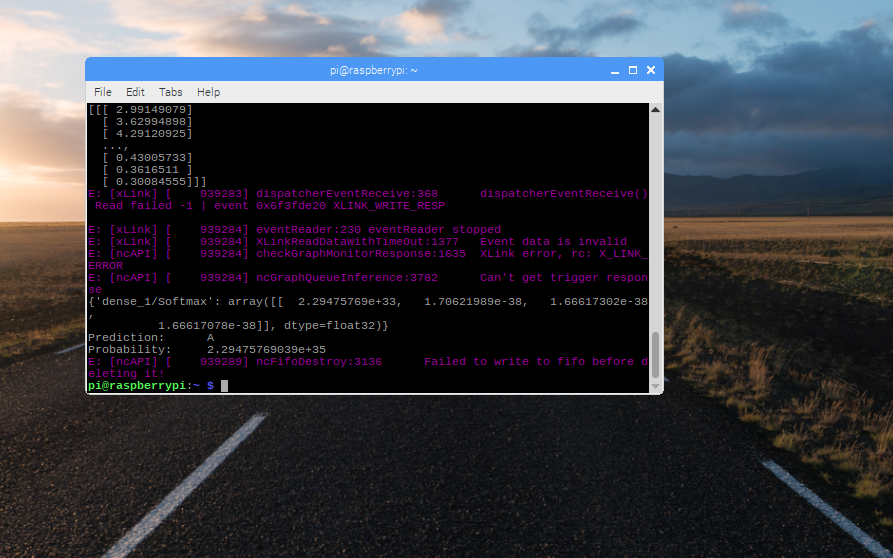
I have attached an image below to show what I see on the screen.
Moreover, could you please try converting or even running the xml bin files we have on the google drive. We have also have the pb saved directory and variable files on the drive. We have literally tried everything and it doesnt seem to work. (when you run the inference file on the A00021.mat input), you are supposed to get the result as N ( no arrhytmia) and a probability around 94%
Thanks
Prithvi
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Men, Prit,
Of course I will take a look at your files. I'm sorry i haven't just yet - but I have not forgotten about you.
Thanks for your patience,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hey Shubha,
Hope you are well.
With regards to the code, did you have the chance to take a look at what could be possibly go wrong? We have a demo day for our project on the 12th and would love to get the model running on the neural stick working before that.
Thanks and looking forward to your answer
Prithvi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Men, Prit,
Not yet but I promise to do so by the end of this week.
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi.
I'll add a couple cents on this:
I trained my own SSDv2 300x300 using the TFOD API; a predict.py using tensorflow functions and a .pb file seems to be working fine.
And using the line mentioned:
-
mo_tf.py --input_model=/tmp/ssd_inception_v2_coco_2018_01_28/frozen_inference_graph.pb --tensorflow_use_custom_operations_config <INSTALL_DIR>/deployment_tools/model_optimizer/extensions/front/tf/ssd_v2_support.json --tensorflow_object_detection_api_pipeline_config /tmp/ssd_inception_v2_coco_2018_01_28/pipeline.config --reverse_input_channels
Wit my own .pb file, I was able to convert it without an issue to bin/xml (just had to be very mindful of creating a specific virtualenv with: python 3.5.2 and a very specific set of pip packages, including tensorflow <=1.4 for running the conversion script (it doesn't work with 1.12, and also made sure of using the switch for FP16, for running the model on the NCS2).
The json support file is essential, else conversion doesn't seem to work... or gives an error (and I used the same pipeline.config for my custom dataset).
What I still don't know, and I would appreciate to know::
- The reverse_input_channels switch, would it make the bin/xml format to be RGB, or BGR ? (i'm kind of lost here, even if it's a single thing).
- The model for TFOD API gives me the detection boxes in the range [0, 1] for X (Width) and Y (Height) coordinates, and to properly position them in my processed image, I have to convert them to the respective [0, maxX], [0, maxY] ). After the conversion to bin/xml, that behavior is still kept? So that I also have to scale properly the detection-boxes in my images, after the conversion to bin/xml.
Maybe the point in 2 makes the detections be off... I'm still adapting a script, but I need to know these two details, to properly assess my results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Sapiain, Roberto
For 1) If your model is trained in RGB, then you need the --reverse_input_channels to run most of our samples since OpenCV reads images in BGR and OpenVino samples use OpenCV.
For 2) If you are scaling your images before training your tensorflow model (meaning normal sized images are passed into Tensorflow Placeholder(s) then scaled before feeding into training) there is no way for Model Optimizer to know about the scaling which you did to get Tensorflow to train and perform inference correctly. You must specifically tell model optimizer how you scaled your image, using the parameters I mention above. If you are not scaling your image before training and rather, scaling during Tensorflow Inference, then you must apply a similar scaling in your Inference Engine code (i.e. using OpenCV API).
I hope this helps.
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear everyone,
Please carefully use the --input_shape parameter to your MO command. Make sure you know exactly what the image size is that your model was trained on, and that what you pass to --input_shape exactly matches it. Having the --input_shape switch incorrect can definitely mess up detection results.
Hope it helps,
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Shubha.
I met the same problem. I think it might be a bug...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page