- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I am using Intel Openvino 2020.2. I converted the trained yolov3 tiny weights and configs using the openvino documentation. After applying it to python demo, I have two classes 'person' and 'helmet' , the demo only detects the person class and does not detect the helmet class. Kindly tell me how to solve this.
Thanks and Regards,
Nagarjun
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Moving this case to openvino forum for a faster resolution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
Thanks for reaching out. It's unclear what the problem could be without many details of the model and commands used to convert.
Please share more information about your model, command given to Model Optimizer to convert the trained model to Intermediate Representation (IR), and environment details (versions of OS, Python, TensorFlow, CMake, etc.). If possible, please share the trained model files for us to reproduce your issue.
Regards,
Munesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
Thanks for reaching out.
My model has 2 classes : person and helmet
I used the instructions given here for converting my model:
I am attaching the converted IR representation for your reference.
Looking forward for your reply.
Best Regards,
Nagarjun
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
Any luck with the models ? Please update the status
Best Regards,
Nagarjun
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
I’ve validated your IR model using object_detection_demo_yolov3_async demo in Ubuntu 18.04 LTS and OpenVINO 2020.4, and I don’t see your model detecting person or helmet. Usually, performance issues are related to conversion from TensorFlow frozen model to IR format.
As such, please share the exact Model Optimizer command that you used to convert your frozen model to IR format. We also require the following environment details (versions of OS, Python, TensorFlow, CMake, etc.).
If possible, please share the trained model files for us to reproduce your issue.
Regards,
Munesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
I used the same commands given in the documentation.
I'm using the following:
1. Windows 10
2. Python 3.6.0
3. Tensorflow 1.13.1
4. Openvino 2020.2
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
Please use the following Model Optimizer command to convert your frozen model to IR format.
python "C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer\mo_tf.py" --input_model \path\to\yolov3_tiny.pb --tensorflow_use_custom_operations_config "C:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer\extensions\front\tf\yolo_v3_tiny.json" --batch 1 --data_type FP16 --reverse_input_channels
Regards,
Munesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
Hope you are doing well. We have used the same command to convert the frozen model to IR representation but with FP32 flag. The .bin and .xml I sent you were generated using this. Maybe I will share the frozen tf model, could you convert from your end and verify please ?
Attaching the frozen tf-model for your reference.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
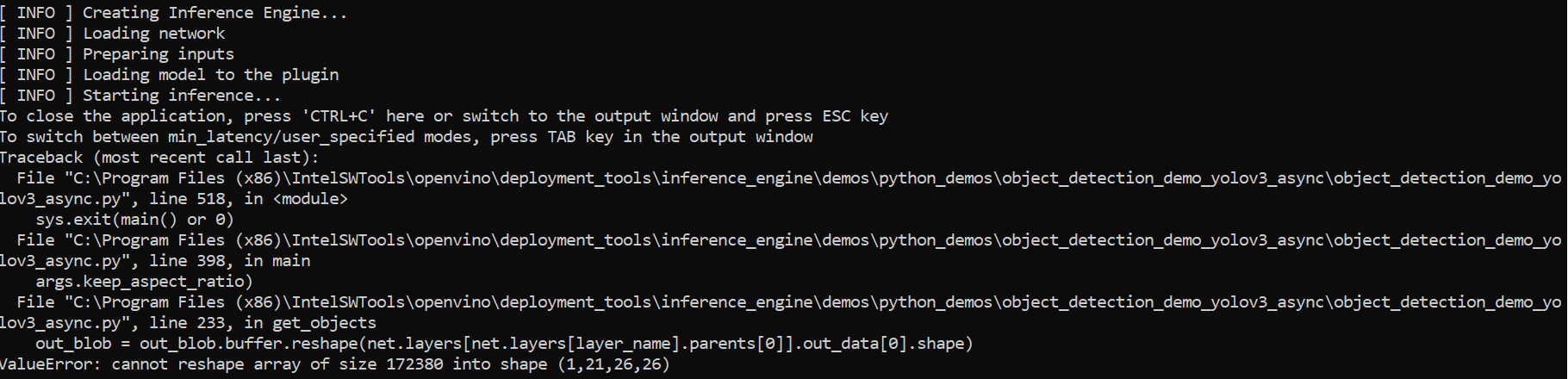
Hi Nagarjun,
The frozen model that you gave me seems to have output shape issues when loading for Object Detection YOLOv3 Async Python demo, upon converting using Model Optimizer using the command I gave you previously, as well as when using the input shape parameters for public YOLO models, which is [1,416,416,3].
https://github.com/openvinotoolkit/open_model_zoo/blob/master/models/public/yolo-v3-tf/model.yml#L30
Would you please provide the full Model Optimizer command that you’ve used to convert the frozen model to IR format?
Regards,
Munesh
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
Thanks for checking on your end. I have used the following commands :
1. Converting the yolo to tensorflow model :
python tensorflow-yolo-v3-master/convert_weights_pb.py --class_names coco.names --data_format NHWC --weights_file yolov3.weights --tiny
2. TF model to IR :
python mo_tf.py --input_model C:/Users/Admin/Desktop/InnovatorsBay/frozen_darknet_yolov3_model.pb --tensorflow_use_custom_operations_config extensions/front/tf/yolo_v3_version.json --batch 1 --reverse_input_channels
3. Running the demo :
python object_detection_demo_yolov3_async.py -i C:/Users/Admin/Desktop/InnovatorsBay/ppe_helmet_detection/data/BLM_Cam_2_vid_2_clip_03.mp4 -m frozen_darknet_yolov3_model.xml -d CPU -t 0.05 -iout 0.05 --labels C:/Users/Admin/Desktop/InnovatorsBay/coco.names
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
We suspect that the custom trained model has a different architecture than the OpenVINO supported YOLOv3 model from Darknet (pjreddie). As such, we would like to enquire how you re-trained the YOLOv3 tiny model, and can you provide your .cfg file if you trained your model in Darknet?
Besides that, since you mentioned that after running the demo your model only detects the person class and does not detect the helmet class, can you confirm if your TensorFlow model detects helmet class as expected? If not, then that is a problem in model training phase and you would need to retrain the model.
Regards,
Munesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Munesh,
Thanks for the info ! I am doing the inference of the converted model in TF. While doing this, I am unable to figure out the node names from tf graph required for the inference code. Can you please share the details of node names required from tf graph as below:
1. input_node name
2. detection_boxes name
3. detection_scores name
4. detection_classes name
Currently, I am using the following names attached in the code snippet for your reference but getting error due to wrong node names. Also, will send you the other details shortly. Attached is my tf inference code for converted yolov3 tiny model.
"""
image_tensor = detection_graph.get_tensor_by_name('inputs:0')
detection_boxes = detection_graph.get_tensor_by_name('concat:0')
detection_scores = detection_graph.get_tensor_by_name('output_boxes:0')
detection_classes = detection_graph.get_tensor_by_name('detector/yolo-v3-tiny/concat_7:0')
num_detections = detection_graph.get_tensor_by_name('detector/yolo-v3-tiny/concat_6:0')
"""
Thanks,
Nagarjun
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
YOLOv3 model originally implemented in the Darknet framework includes feature extractor called Darknet-53 with three branches at the end that make detections at three different scales and these branches must end with the YOLO Region layer.
However, implementation of Region layer in various publicly available YOLOv3 models vary significantly, and the tendency is to create the Region layer using simple layers, since many popular frameworks do not have the Region layer implemented as a single layer. This badly affects performance.
For this reason, the main idea of YOLOv3 model conversion to IR is to cut off these custom Region-like parts of the model and complete the model with the Region layers where required.
For YOLOv3 models originally implemented in the Darknet framework, I would suggest you start by dumping TensorFlow model out of https://github.com/mystic123/tensorflow-yolo-v3 GitHub repository, by following the instructions at the following link:
After that, convert the YOLOv3 TensorFlow Model to IR by following the steps available at the following link:
The color channel order (RGB or BGR) of an input data should match the channel order of the model training dataset. If they are different, perform the RGB<->BGR conversion by specifying the command-line parameter: --reverse_input_channels. Otherwise, inference results may be incorrect. For more information about the parameter, refer to the following link:
Another important parameter to consider is input shape. For more information about input shape parameter, refer to the following link:
Regards,
Munesh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Nagarjun,
This thread will no longer be monitored since we have provided recommendations and suggestions. If you need any additional information from Intel, please submit a new question.
Regards,
Munesh
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page