- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear experts,
I did not found any answer to my question in any tutorial/book on OpenMP and local gurus also have not answered my questions:
What is the best/standard/sustainable way to manipulate with OpenMP threads in software?
Could you please provide any reference/your experience for a case described below?
I have a subroutine similar to calc_level_0 (See calc_level_0.f90), it manipulated over data with variable size “n”.
Profiling shows that for different n I must use not more than (n/10^4) cores to obtain speed-up. n ~ 0 – 10^6.
I wrote some tests and got excellent speed-up (by manually setting the omp_num_threads).
Then I incorporated my sub into upper level sub calc_level_1 (See calc_level_1.f90) which calls calc_level_0 for different arrays in loops. Each call required different number of optimal threads. Each loop can have 0 or 1 iteration, sometimes 2-5.
My observations:
1. Simulation on coarse grid (Nx and Ny are small): n <= 1,000 < 10^4, only 1 core must be used, otherwise slow down.
2. Simulation on medium grid:
Early iterations (time_step < 30): only 1 core for all loops;
Later iteration (time_step 30--100): 2-3 cores for loop A, 1 core for loops B and C;
3. Simulation on fine grid
Early iterations: 1-2 for Loop A, 1 core for loops B and C;
Later iteration: up to 10 cores for loop A, up to 5 core for loops B and C.
I create a sub get_optimum_number_of_threads() (see get_optimum_number_of_threads.f90 ) which returns the number of optimal threads, taken into account max_num_threads (from global vars).
Vers A. I can use omp_set_num_threads()
call get_optimum_number_of_threads( n, num_openmp_threads) call omp_set_num_threads(num_openmp_threads) !$OMP parallel do do k=1, n call f( array(k) ) end do !$OMP end parallel do
Drawback:
on the first iteration I got opt_num_threads=1,
I set number of threads to 1 (spoiling global var),
on the next call max_num_threads = omp_get_num_threads()
I will get "1" thread, and all subsequent loops will use only max 1 core. There is no way to get initial number of max threads (may be save locally and reset to max after each cycle execution? Is this a good solution?).
Vers B.
To overcome this issue I use NUM_THREADS( num_openmp_threads ) (see calc_level_0_dynamic.f90)
call get_optimum_number_of_threads( n, num_openmp_threads ) !$OMP parallel do NUM_THREADS( num_openmp_threads ) do k=1, n call f( array(k) ) end do !$OMP end parallel do
In this case I will not overwrite global number of threads, and each cycle will use optimum number of cores. (Victory?)
Drawback: I have 4 threads running, I use only 1, other 3 spins. I see that 4 out of my 8 cores are busy and only 1 actually is doing calculation 8(.
OK. I could have live with that.
BUT.
I see that other parts of simulations running slower with 3 spinning threads 8(.
I ran simulation with SET OMP_NUM_THREADS =1
Sub calc_level_1.f90 occupies 10 secs.
Other subroutine (non-parallel) occupies 40 secs.
Total time 50 secs.
SET OMP_NUM_THREADS = 4
Sub calc_level_1.f90 occupies 7 secs. (I get some speed-up here)
Other subroutine (non-parallel) occupies 60 secs. (I got drastic slow-down here)
Total time 67 secs (((((
With SET OMP_NUM_THREADS = 8 things are even worse, but laptop is really hot.
My question. What is recommended way to handle number of OpenMP in such a case?
Pass it as input explicit parameter from the upper subroutine (even if there are 10 levels above)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is an environment variable named KMP_BLOCKTIME. This is used to set the number of milliseconds that threads exiting a parallel region use for a spinwait time looking for your region initiating thread to enter its next parallel region. You can set this to 0. Depending on your version of OpenMP, you may also have a library function KMP_SET_BLOCKTIME that you can use to dynamically vary the block time.
An alternative method is to use OpenMP tasks. See: http://www.training.prace-ri.eu/uploads/tx_pracetmo/Tasks.pdf
This may require you to rethink your programming.
A third alternative also requires you to rethink your parallelism. This is not as bad as you think:
! my guess at your current code do i=1, nArrays ... setup array contex call get_optimum_number_of_threads( n, num_openmp_threads ) !$OMP parallel do NUM_THREADS( num_openmp_threads ) do k=1, n call f(array(k)) end do !$OMP end parallel do end do ! consider using !$OMP PARALLEL !$OMP MASTER do i=1, nArrays ... setup array contex call get_optimum_number_of_threads( n, num_openmp_threads ) slice = n / num_openmp_threads do iThread=1,num_openmp_threads !$omp task kBegin = slice * (iThread - 1) kEnd = iBegin + slice if(iThread .eq. num_openmp_threads) iEnd = n do k=kBegin, kEnd call f(array(k)) end do !$omp end task end do ! iThread end do ! nArrays !$OMP END MASTER !$OMP END PARALLEL
The above is all untested.
What you did not show, in sketch form or in total, is if or how the remainder of the program is going parallel. This information will help immensely.
Jim Dempsey
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You should be aware that entering and leaving a parallel section causes overhead. Therefore it pays off to make the outermost loops parallel.
In your case, with the outer loops responsible for only a few iterations, you may need to look for a way to keep the inner loops - or at least the threads - going. Just thinking out loud here: perhaps a master/slave set-up? Hand out tasks to the lower-level routine in the OpenMP threads. Set up the loops in a parallel section and at the end of that wait for new tasks. It may be tricky to set up and my description is probably not the clearest possible, but that is what I can advise.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Settings such as omp_places=cores could impact your conclusions if you have hyperthreads enabled.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is an environment variable named KMP_BLOCKTIME. This is used to set the number of milliseconds that threads exiting a parallel region use for a spinwait time looking for your region initiating thread to enter its next parallel region. You can set this to 0. Depending on your version of OpenMP, you may also have a library function KMP_SET_BLOCKTIME that you can use to dynamically vary the block time.
An alternative method is to use OpenMP tasks. See: http://www.training.prace-ri.eu/uploads/tx_pracetmo/Tasks.pdf
This may require you to rethink your programming.
A third alternative also requires you to rethink your parallelism. This is not as bad as you think:
! my guess at your current code do i=1, nArrays ... setup array contex call get_optimum_number_of_threads( n, num_openmp_threads ) !$OMP parallel do NUM_THREADS( num_openmp_threads ) do k=1, n call f(array(k)) end do !$OMP end parallel do end do ! consider using !$OMP PARALLEL !$OMP MASTER do i=1, nArrays ... setup array contex call get_optimum_number_of_threads( n, num_openmp_threads ) slice = n / num_openmp_threads do iThread=1,num_openmp_threads !$omp task kBegin = slice * (iThread - 1) kEnd = iBegin + slice if(iThread .eq. num_openmp_threads) iEnd = n do k=kBegin, kEnd call f(array(k)) end do !$omp end task end do ! iThread end do ! nArrays !$OMP END MASTER !$OMP END PARALLEL
The above is all untested.
What you did not show, in sketch form or in total, is if or how the remainder of the program is going parallel. This information will help immensely.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Comments on the above:
The parallel region was located higher in your loop nest (you can move it higher in your call nest too). This reduces the region entry/exit by a factor of 1/nArrays. Also, be aware that tasks of this region that are in spinwait are immediately available to a new task for this region. *** using tasks, you would not typically want the KMP_BLOCKTIME=0 ***, although on exit of the parallel region you might want at least a reduced time.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Arjen Markus wrote:
Just thinking out loud here: perhaps a master/slave set-up? Hand out tasks to the lower-level routine in the OpenMP threads. Set up the loops in a parallel section and at the end of that wait for new tasks. It may be tricky to set up and my description is probably not the clearest possible, but that is what I can advise.
Arjen, your description is inedeed very short. I think that below Jim Dempsey provided an example how to setup master/slave. Am I right?
I will try it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Most definitely :). There are a bunch of details that you need to take care of of course, but his post is what I had in mind.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tim P. wrote:
Settings such as omp_places=cores could impact your conclusions if you have hyperthreads enabled.
Thank you. I read about omp_places and rerun the program with different options. No changes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jim,
I wrote an answer to you, try to insert the picture, and IE lost my answer…
jimdempseyatthecove wrote:
A third alternative also requires you to rethink your parallelism. This is not as bad as you think:
Thank you for your code example, I will try when I have enough time, and update you with the results.
While reading about master/slave, I found OMP_THREAD_LIMIT and omp_get_thread_limit()
I used them to store unmodified max number of threads, and it solved last mentioned issue in my post with spinning threads.
In get_optimum_number_of_threads.f90 I substitute
max_num_threads = omp_get_num_threads()
by
max_num_threads = omp_get_thread_limit()
In calc_level_0.f90 I substitute
call get_optimum_number_of_threads( n, num_openmp_threads ) !$OMP parallel do NUM_THREADS( num_openmp_threads ) do k=1, n call f( array(k) ) end do !$OMP end parallel do
by
call get_optimum_number_of_threads( n, num_openmp_threads ) call omp_set_num_threads(num_openmp_threads) ! I still can increase the number of threads later !$OMP parallel do do k=1, n call f( array(k) ) end do !$OMP end parallel do
This allowed me to keep only 1 thread in the beginning of simulation and then increase/decrease it when necessary.
jimdempseyatthecove wrote:
What you did not show, in sketch form or in total, is if or how the remainder of the program is going parallel. This information will help immensely.
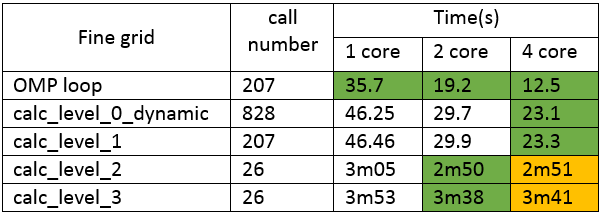
I made profiling for the latest version please find in attached files
for coarse frid there is a small gain from 2 threads. Call number for calc_level_0_dynamic is higher (828), than OMP_loop, because ~600 calls occured with n=0, value of n can be increased inside calc_level_0.
On fine grid, results are better, but I still see, some slow down at 4 cores.
Issue.
Before calling the exec, I must set two variables
set OMP_NUM_THREADS=2
set OMP_THREAD_LIMIT=%OMP_NUM_THREADS%
If I have OMP_THREAD_LIMIT undefined, than
max_num_threads = omp_get_thread_limit()
returned me max_num_threads = 2*10^9 (hmmm, I expected the same value as omp_get_num_threads() ) So I can't rely on this approach, as no one around me has these variables defined, and I can not define OMP_THREAD_LIMIT from inside the running program.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gents,
What do you think about merging loops A, B and C into one? Updated calc_level_1.f90:
!$OMP parallel do private (n, ...)
do k = 1, (k1 + k2 + k3)
select case( k )
case( : k1)
n = get_data_size( A, k, time_step, Nx, Ny )
call calc_level_0( n, A( 1:n, k) )
case( k1 + 1 : k1 + k2 )
n = get_data_size( B, k-k1, time_step, Nx, Ny )
call calc_level_0( n, B( 1:n, k-k1) )
case( k1 + k2 + 1 : )
n = get_data_size( C, k-k1-k2, time_step, Nx, Ny )
call calc_level_0( n, C( 1:n, k-k1-k2) )
end select
end do
!$OMP end parallel do
+ when n is big -> use nested parallelizm for these threads.
When (k1+k2+k3) >= OMP_NUM_THREADS: each thread processes the whole 1D array(1:n, k);
When (k1+k2+k3) < OMP_NUM_THREADS: several threads should process 1D array;
Upd 1. Hmm, "Select Case" does not work with variables, then one could use if-then-else
!$OMP parallel do private (n, ...) do k = 1, (k1 + k2 + k3) if( k <= k1) then n = get_data_size( A, k, time_step, Nx, Ny ) call calc_level_0( n, A( 1:n, k) ) elseif( k <= k1 + k2 ) then n = get_data_size( B, k-k1, time_step, Nx, Ny ) call calc_level_0( n, B( 1:n, k-k1) ) else n = get_data_size( C, k-k1-k2, time_step, Nx, Ny ) call calc_level_0( n, C( 1:n, k-k1-k2) ) end if end do !$OMP end parallel do
How it should organized in a professional way?
Upd 2. I think it is better to keep loops A, B, C not merged, and use NOWAIT for each loop.
I implemented the approach at Upd.1. It is slower.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page