- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My previous thread on sine function optimization grow very large so I was being asked by Sergey Kostrov to create a new threads for my other functions implementations.
Now I'am starting with gamma stirling approximation.The code is based on formula taken from "Handbook of Mathematical Functions" p. 257 formula 6.1.37
Function was tested against the book's table and later against the Mathematica 8which is used as areference model for an accuracy comparision.
There are two implementations.
One of them is based on 1d arrays ,library pow() calls and division inside for-loop
to calculate coefficients and to sum the series expansion.First function uses 14 terms of stirling expansion second uses 10 terms of stirling expansion btw regarding the slower implementation with more terms was not able to increase the accuracy when compared to Mathematica 8 reference result.
Second method is faster because array'scoefficients fillingand summation is eliminated
and also pow() library calls are not used.Instead the function relies on simple calculation of
argument x ofconsecutivepowers mulitplied by constant denominator and divided by thenumerator.
Pre-calculation of coefficients was not possible because of dependency of denominator on argument x.
Accuracy when compared to Mathematica code is between 15-16 decimal places.
Feel free to optimize and test this code and please do not forget to post your opinion.
Code for C implementation of stirling gamma function
slower version
[bash]inline double gamma(double x){ double sum,result; sum = 0; result = 0; if( x > gamma_huge){ return (x-x)/(x-x); //NaN }else if( x < one){ return (x-x)/(x-x); }else{ double ln,power,pi_sqrt,two_pi,arg; two_pi = 2*Pi; double coef1[] = {1.0,1.0,139.0,571.0,163879.0, 5246819.0,534703531.0,4483131259.0, 432261921612371.0, 6232523202521089.0, 25834629665134204969.0,1579029138854919086429.0, 746590869962651602203151.0,1511513601028097903631961.0 }; double coef2[] = {12.0,288.0,51840.0,2488320.0,209018880.0, 75246796800.0, 902961561600.0,86684309913600.0, 514904800886784000.0, 86504006548979712000.0, 13494625021640835072000.0,9716130015581401251840000.0, 116593560186976815022080000.0,2798245444487443560529920000.0 }; int const size = 14; double temp[size]; double temp2[size]; double temp3[size]; int i,j; long k; k = 0; for(i = 0;i
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Results for the faster version of gamma stirling approximation which uses 10 stirling series coefficients.Was not able to use Horner scheme directly because of an accumulated error when implemented division inside the polynomial.So my code looks really ugly:)
Code for faster version.
[bash]inline double fastgamma(double x){ double sum,result; sum = 0; result = 0; if( x > gamma_huge){ return (x-x)/(x-x); }else if( x < one){ return (x-x)/(x-x); }else{ double ln,power,pi_sqrt,two_pi,arg; two_pi = 2*Pi; double nom1,nom2,nom3,nom4,nom5,nom6,nom7,nom8,nom9,nom10; double denom1,denom2,denom3,denom4,denom5,denom6,denom7,denom8,denom9,denom10; double coef1,coef2,coef3,coef4,coef5,coef6,coef7,coef8,coef9,coef10; double z1,z2,z3,z4,z5,z6,z7,z8,z9,z10; nom1 = 1.0; nom2 = 1.0; nom3 = 139.0; nom4 = 571.0; nom5 = 163879.0; nom6 = 5246819.0; nom7 = 534703531.0; nom8 = 4483131259.0; nom9 = 432261921612371.0; nom10 = 6232523202521089.0; denom1 = 12.0; denom2 = 288.0; denom3 = 51840.0; denom4 = 2488320.0; denom5 = 209018880.0; denom6 = 75246796800.0; denom7 = 902961561600.0; denom8 = 86684309913600.0; denom9 = 514904800886784000.0; denom10 = 86504006548979712000.0; z1 = x; z2 = z1*z1;//x^2 z3 = z2*z1;//x^3 z4 = z3*z1;//x^4 z5 = z4*z1;//x^5 z6 = z5*z1;//x^6 z7 = z6*z1;//x^7 z8 = z7*z1;//x^8 z9 = z8*z1;//x^9 z10 = z9*z1;//x^10 ln = exp(-x); arg = x-0.5; power = pow(x,arg); pi_sqrt = sqrt(two_pi); sum = ln*power*pi_sqrt; coef1 = nom1/(z1*denom1); coef2 = nom2/(z2*denom2); coef3 = nom3/(z3*denom3); coef4 = nom4/(z4*denom4); coef5 = nom5/(z5*denom5); coef6 = nom6/(z6*denom6); coef7 = nom7/(z7*denom7); coef8 = nom8/(z8*denom8); coef9 = nom9/(z9*denom9); coef10 = nom10/(z10*denom10); result = one+coef1+coef2-coef3-coef4+coef5+coef6-coef7-coef8+coef9+coef10; } return sum*result; }[/bash]
Results of 1e6 iterations of fastgamma() called with an argument 2.0 incremented by 0.000001
Microsoft optimized compiler
fastgamma() start value is 13214688
fastgamma() end value is 13214875
execution time of fastgamma() 1e6 iterations is: 187 millisec
fastgamma 2.000000016396600500000000
The same test compiled with Intel compiler
fastgamma() start value is 24296016
fastgamma() end value is 24296157
execution time of fastgamma() 1e6 iterations is: 141 millisec
fastgamma 2.000000016396600500000000
IntelCompiler settings
/Zi /nologo /W3 /MP /O2 /Ob2 /Oi /Ot /Oy /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /EHsc /GS- /Gy /arch:SSE2 /fp:precise /QxHost /Zc:wchar_t /Zc:forScope /Fp"Release\inline.c.pch" /FAcs /Fa"Release" /Fo"Release" /Fd"Release\vc100.pdb" /Gd /TP
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
coefN = nomN / (zN*denomN)
with
coefN = nomN/denomN* rcpzN
nomN/denomN: precomputed constant
rcpzN = (1/x)^N, you can compute 1/x once then use only multiplications to get (1/x)^2, etc.
it should be a lot faster since you'll avoid most divides
for a better accuracy, add first the smallest absolute values, since x>1 it looks likeit will be better to do result =coef10+coef9-coef8... +one
next steps may be to see how you can rewrite it using Horner's scheme (based on 1/x instead of x) and get rid of the libc calls like exp() and pow()
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
After studying the formula I came with the same solution like yours.If I could get rid of divides I would have been able to reduce the exec speed probably by ~140-160 cycles.I implemented Horner-like scheme initialy exactly as in formula ,but encountered an error probably because of wrongoperators precedence.The accuracy was less than 2 decimal places.
How can I get rid libc calls?.In the case of exp() I can"inline" my fastexp() but will it be faster than library call.
Can I enforce compiler to inline pow() and exp() calls both of them are not hot-spots for this code.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
How can I get rid libc calls?.In the case of exp() I can "inline" my fastexp() but will it be faster than library call
It's beyond my expertise but I suppose the goal will be to find the best polynomial or rational approximations forgamma(x) without using the Stirling'sformula (Muller advise to use Maple for this but Mathematica should be OK too) it will be probably a series of approximations to cover the whole domain, now I may well be wrong since I havezero practical experience with gamma functions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is possible to force compiler to inline library calls.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
probably but the best you can hope is to have a direct call to the native x87 instructions (it will be slow and amenable neither to vectorized code nor FMA usage for AVX2 targets), even if you inline the code for some exp() and pow() approximations you will basically do 3x a range reduction and will compute 3 different polynomial/rational approximations when the best (speed vs accuracy) solutionis probably to use a single range reduction and a single minimax polynomial/rational approximation, now if Mathematica do all the work for you you'll not learn as much as you do by studying different methods, so I suppose one question is what is your key goalIt is possible to force compiler to inline library calls.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think that inlining of library calls could depend on frequency of these calls.As you can see fastgamma() calls only oncemath library functions so compiler did notinline the code, but if the calls were made from within the for-loop which is natural hot-spot and 100% branch predicted in such a case smart compiler could perform inlining to reduce calling overhead.
>>even if you inline the code for some exp() and pow() approximations you will basically do 3x a range reduction and will compute 3 different polynomial/rational approximations when the best (speed vs accuracy)
Range reduction and input checking in non-periodic functions will be also present during function call when code execution is transfered to MSVCRT.DLL which implements math libraries.
The best solution is to write the formula in such a way to eliminate dependency on library calls,but not always will it be possible.
>>solutionis probably to use a single range reduction and a single minimax polynomial/rational approximation
Yes it would be the best options in terms of speed.
>>Mathematica do all the work for you you'll not learn as much as you do by studying different methods,
I suppose that Mathematica uses a Lanczos approximation with arbitrary precision.
I could enter such a command like N[Gamma[some value],precision value] to obtain the result but I would like to write the code by studying different methods and relying on Mathematicaas a reference model for testing.
It is also possible to write such a code directly in Mathematica as procedural program ,but my knowledge of Mathematica programming is basic.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was talking about a method to get the all the coefficients of the mimimax approximation, not a single value, IIRCin the Muller's book he says it's something you get after runs of around 5 minutes with Waterloo Maple, so I suppose it's as simple as saying something like"give me the minimax approximation for gamma(x) in the sub-domain [1.0,1e6] with 53-bit precision" and after a while it will return saying "you must use a xth order approximation and your coefficients are these: a0=xxx, a1=xxx,..."Icould enter such a command like N[Gamma[some value],precision value] to obtain the result but I would like to write the code by studying different methods and relying on Mathematica as a reference model for testing.
EDIT: just found this http://www.maplesoft.com/support/help/Maple/view.aspx?path=numapprox/minimax
also if you don't have yet the Muller's book some background material on minimax approximations and the Remez algorithm can be found in this paper (lacka lot of details though):
http://www.research.scea.com/research/pdfs/RGREENfastermath_GDC02.pdf
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you. I'll providefeedback soon including some additional comments for the 'FastSin' function.
A message for the Intel Software Network administration:
What do you think about a new forum "Algorithms", or something like this?
Best regards,
Sergey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was talking about a method to get the all the coefficients of the mimimax approximation, not a single value
Misunderstood your post.Mathematica 8 has minmax approximation package which is suitable for such a calculation here is linkhttp://reference.wolfram.com/mathematica/FunctionApproximations/tutorial/FunctionApproximations.html
scroll down to see minimax approximation.
Today I will try to use this approx on gamma function.
>>in the sub-domain [1.0,1e6]
For arbitrary precision system as Mathematica the upper range is possible to calculate,but on fixed-precission system value like 2.0e2 gives overflow.
>>also if you don't have yet the Muller's book some background material on minimax approximations and the Remez algorithm can be found in this paper (lacka lot of details though)
Thanks for link.I don't have Muller's book ,but I will try to study "A first course in numerical analyssis" good textbook butfilled with fortran-like pseudocode without anyword of how to implement those algorithms in C.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sergey could you alsotry to test gamma approximation ?I'll providefeedback soon including some additional comments for the 'FastSin' function
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
give me the minimax approximation for gamma(x) in the sub-domain [1.0,1e6] with 53-bit precision" and after a while it will return saying "you must use a xth order approximation and your coefficients are these: a0=xxx, a1=xxx,..."
Here are the results for MiniMaxApproximations obtained from Mathematica 8 package FunctionApproximation
[bash]command entered: mmagam = MiniMaxApproximation[Gamma
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Second MiniMaxApproximation of Gamma(x)on range [0.01,1].The Relative Error Plot was added as an attachmentgive me the minimax approximation for gamma(x) in the sub-domain [1.0,1e6] with 53-bit precision" and after a while it will return saying "you must use a xth order approximation and your coefficients are these: a0=xxx
[bash]MiniMaxApproximation of Gamma
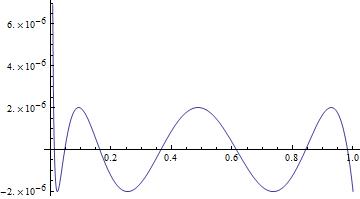{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the code of improved version:
[bash]inline double fastgamma2(double x){ double sum,result; sum = 0; result = 0; if( x > gamma_huge){ return (x-x)/(x-x); }else if( x < one){ return (x-x)/(x-x); }else{ double const coef1 = 0.08333333333333333333333333; double const coef2 = 0.00347222222222222222222222; double const coef3 = -0.00268132716049382716049383; double const coef4 = -0.000229472093621399176954733; double const coef5 = 0.000784039221720066627474035; double const coef6 = 0.0000697281375836585777429399; double const coef7 = -0.000592166437353693882864836; double const coef8 = -0.0000517179090826059219337058; double const coef9 = 0.000839498720672087279993358; double const coef10 = 0.0000720489541602001055908572; double ln,power,pi_sqrt,two_pi,arg; two_pi = 2*Pi; double invx = 1/x; ln = exp(-x); arg = x-0.5; power = pow(x,arg); pi_sqrt = sqrt(two_pi); sum = ln*power*pi_sqrt; result = one+invx*(coef1+invx*(coef2+invx*(coef3+invx*(coef4+invx*(coef5+invx*(coef6+invx*(coef7+invx*(coef8+invx*(coef9+invx*(coef10)))))))))); } return sum*result; }
Here are the results for 1e6 iterations ,compiled with Intel compiler
fastgamma2() start value is 14962227
fastgamma2() end value is 14962305
execution time of fastgamma2() 1e6 iterations is: 78 millisec As You can see this code is 2x faster than previous version
fastgamma2 is: 2.000000016396600100000000
[/bash]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
As You can see this code is 2x faster than previous version
cool, you're fast, optimizing code is fun isn't it ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
cool, you're fast, optimizing code is fun isn't it ?
I really like to optimize code.Now I will try to optimize 45 functions which are based on iterative methods.
Fastgamma2() is 2x faster than previous version,but it is still dominated by two library calls.By crude calculation each of them takes 25-30 ns to execute.
Bronxzv Did you look at MiniMaxApproximation for Gamma(x) at interval [0.01,1] this rational polynomial will introduce some overhead when implemented in fastgamma2().
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
that's quite a lot! to keep your code clean and manageable I'll advise to design a library of simple helper functions such asEvalPoly5() here http://software.intel.com/en-us/forums/showpost.php?p=186020, the main functions will be a bit shorter and more readable without impact on speednow I will try to optimize 45 functions which are based on iterative methods
look at MiniMaxApproximation for Gamma(x) at interval [0.01,1] this rational polynomial will introduce some overhead when implemented in fastgamma2().I don't knowwhich overhead you are refering to, it's simply two low order polynomials and a division it should be a lot faster than your last example since it's not calling pow() and exp()
the code for the rational approx. will be basically: EvalPoly2(a0,a1,a2,x) / EvalPoly4(b0,b1,b2,b3,b4,x) with a0..a2, b0..b4 constants
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is good approach to keep code clean.I will redesignmy C++ static library exactly as you advised me.I have only 8 months of serious programmingexperience :)I'll advise to design a library of simple helper functions such asEvalPoly5()
>>I don't knowwhich overhead you are refering to, it's simply two low order polynomials and a division it should be a lot faster than your last example since it's not calling pow() and exp()
Sadly Mathematica 8 was not able to calculate MiniMaxApproximationfor fastgamma(x)on whole interval i.e. [0.001,160] because of "division by zero" errors.Knowing that fastgamma(x) is not accurate on interval [0,1]
I decided to calculate minimax approximating polynomial only for this interval.So I can not get rid of library pow() and exp()calls.I willimplement two branching statement on input checking simply when 0.001
Mathematica's minimax approximating polynomial will be executed and when 1.0
P.S.
Bronxzv have you ever tried to write your library of special and elementary function from the book "Handbook of Mathematical Functions".
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ilia,Bronxzv have you ever tried to write your library of special and elementary function from the book "Handbook of Mathematical Functions".
I have basically writen only the functions useful for my 3D rendering needs, some directly taken from Abramowitz & Stegun, but never a full library like you are doing
3D rendering use cases are generally easy since you don't need a lot of precision, the key goal is to have approximations that you can vectorize, though
functions that I use the most are sin, cos, arccos, ln, exp
thanks tothe Muller's book I have now abasicunderstanding of the subject, beyond my current needs
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes 3D rendering is mostly based on the elementary functions.Regarding precision do you use in your project double precission floating-point values because afaik Windows 7 rendering stack and current display hardware cannot work with more than 10-12bit per colour component.3D rendering use cases are generally easy since you don't need a lot of precision, the key goal is to have approximations that you can vectorize, though
functions that I use the most are sin, cos, arccos, ln, exp
How do you calculate more esoteric function like "BSDF" which could be physically based and involves calculation of an integral(as stated in "Physically based rendering")book.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page