- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I'm evaluating IPP's multirate FIR filter for my application where performance is the major concern.
It is very intuitive and easy to use.
However, I found that ippFirMR performs poorly when compared to hand written AVX2 code(40% slower).
I ran the VTune profiler on code that runs IPP FIRMR and found that the reason for poor performance was the low vector capacity usage. VTune micro-architecture exploration shows only 50% vector capacity usage.
I tried setting CPU features to dispatch L9 implementation, but found no difference.
Does ippFirMR have an implementation for L9(AVX2) and K0(AVX512) ? or does it only have the SSE versions.
Am I missing something ?
Implementations for K0 and L9 would be of great help as I do not want to maintain separate versions of handwritten code for every architecture.
I'm using the 2020.1.216 version of IPP. I'm running on an Intel Corei7-7600U processor(with windows 10) that has AVX2 capabilities.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update:
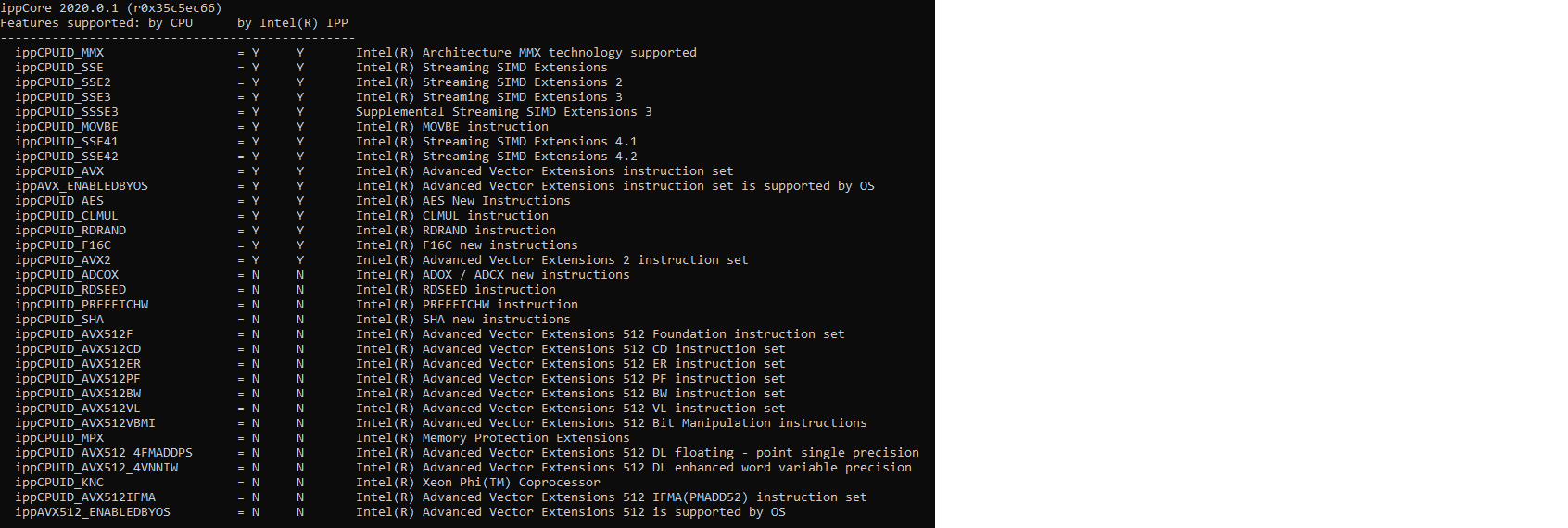
ippSetCpuFeatures(L9_FM) returns 49(ippStsFeatureNotSupported)
CPU features attached below.
Definition of L9_FM(copied from https://software.intel.com/en-us/ipp-dev-reference-setcpufeatures 64-bit code):
#define PX_FM ( ippCPUID_MMX | ippCPUID_SSE | ippCPUID_SSE2 )
#define M7_FM ( PX_FM | ippCPUID_SSE3 )
#define U8_FM ( M7_FM | ippCPUID_SSSE3 )
#define N8_FM ( U8_FM | ippCPUID_MOVBE )
#define Y8_FM ( U8_FM | ippCPUID_SSE41 | ippCPUID_SSE42 | ippCPUID_AES | ippCPUID_CLMUL | ippCPUID_SHA )
#define E9_FM ( Y8_FM | ippCPUID_AVX | ippAVX_ENABLEDBYOS | ippCPUID_RDRAND | ippCPUID_F16C )
#define L9_FM ( E9_FM | ippCPUID_MOVBE | ippCPUID_AVX2 | ippCPUID_ADCOX | ippCPUID_RDSEED | ippCPUID_PREFETCHW )
#define K0_FM ( L9_FM | ippCPUID_AVX512F )
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Kolthaya, Shreeharsha,
Thanks for investigating IPP and raising your question. We reproduced ippSetCpuFeatures(L9_FM) returns 49(ippStsFeatureNotSupported), investigation is on-going, will back to you once there is any update.
Even the return is 49, while you can use the sample code below to check function ippSetCpuFeatures() works.
Ipp64u emask = ippGetEnabledCpuFeatures();
printf(" ippCPUID_AVX2 = ");
printf("%c\t%c\t", (mask & ippCPUID_AVX2) ? 'Y' : 'N', (emask & ippCPUID_AVX2) ? 'Y' : 'N');
printf("Intel(R) Advanced Vector Extensions 2 instruction set\n");
Another question about performance lower than hand written AVX2 code(40% slower). Could you send out your sample code to help investigate?
Best Regards,
Ruqiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi RUQIU C.,
Thanks for the quick response!
I think the reason ippSetCpuFeatures(L9_FM) returned 49 was that ippCPUID_SHA was set in the L9_FM mask which is not supported by my cpu.
I get zero return value after having removed ippCPUID_SHA from the mask.
The output of running the sample code from http://scc.ustc.edu.cn/zlsc/intel/2020/ipp/common/get_started.htm in the attachment.
Unfortunately I cannot share the source code for the handwritten version.
Although I can say that the reason it performs better is that it uses avx2 intrinsics and the ippFirMR has been using SSE as shown by VTune Profiler logs. Also there is no change in ipp performance when I set cpu features to PX_FM.
To dispatch L9 implementation of the multirate filter is it necessary that the CPU has support for all features listed under L9 including SHA instructions?
On CPUs that have AVX2 support but lack other features like SHA does the dispatcher regress to lower versions of the implementation ?
Thanks,
Shreeharsha
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Shreeharsha,
To dispatch L9 implementation of the multirate filter, it's not necessary that the CPU support all features listed under L9 including SHA instructions.
On CPUs that have AVX2 support but lack other features like SHA does, the IPP internal dispatcher will find the best path to make it has best performance according the platform.
Regards,
Ruqiu
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page