- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello all,
I have a Cyclone V A9 device (300k LEs) and a big design that fit it 95% ALM 12% Memory bits 37% DSP. 14% of ALM are unavailable due to LAB input limits and wide-signals conflicts so real used space is 81% of ALM. Compilation fail due to Warning (16618): Fitter routing phase terminated due to routing congestion. Congestion details can be found in Chip Planner. Critical Warning (188026): The Fitter failed to successfully route the design. You may be able get this design to route by making design modifications, changing the fitter seed or by enabling the Fitter Aggressive Routability Optimizations logic option. etc.. Attached a Chip Planner blank and with congestion map. Threshold is at 99%, why in black area (= no my logic) there is a congestion? What is in that area (circled yellow into images)? I am trying to change some settings and floorplanning design but every compilation take 1+ hour (I use .vqm file generated by another tool so analysis and synthesis is fast, i do just routing) Image link: http://it.tinypic.com/r/2wecbdk/9 Thank you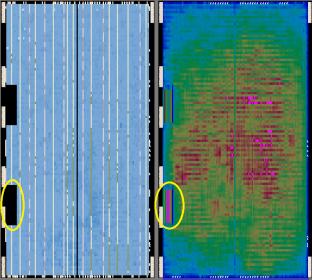{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think that's the Hard PCIe block. Strange it shows up as routing congestion but not sure if I've looked at that or not. In the messages, where is the area of most congestion?
Besides Fitter Aggressive Routability, I would suggest turning up the Placement Effort to 8(More Fitter Settings) and create a quartus.ini with the following: vpr_placement_effort_targets_all_edges = on This will make your compile time go up, but basically makes the placer spend more timing making moves that make the design get better timing AND make it more routable(without the .ini it just does the former). This might work, but you may be too congested. To be honest, reducing the logic a bit is probably your best bet in that case. Unless there's something explicitly wrong with the floorplan the fitter chooses, manually floorplanning doesn't really help. I also find it strange that 14% of your ALMs are lost due to LAB input limits. I don't look at the number much but I believe it's because that line item is usually a really small percentage. That basically means your LABs have the maximum number of signals coming into them, which basically means they require the maximum amount of required routing to get to them, i.e. not only are you using a lot of resources, your design is naturally tough to route. (This is one of those things that doesn't jump out of the raw numbers. You could build a shift register that uses 100% of the ALMs and Quartus would have no problem routing it, but a cross-bar mux would be significantly more difficult.) One last thing to try, if you're using a more recent version of Quartus(I forget which, maybe Q15.0 and beyond), but try Fitter -> More Settings -> Advanced Physical Optimizations, which is a different algorithm that is supposed to improve routability. Good luck, as fixing no routes is not easy.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't use PCIe, only 4 pins with external worlds. Design use a lot of pipeline stages with a lot of logic (dividers, multipliers, etc..).
Routing failure is with Placement Effort = 8.0 and using Advanced Physical Optimization. I am using latest version of Quartus (15.1 update 1). I will try vpr_placement_effort_targets_all_edges in the next compilation.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Pipe stages on their own shouldnt kill the routing. Do you have a lot of high fan out regs? could you do some register duplication?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello tricky,
This is my Quartus report: Maximum fan-out node pll:u_pll|pll_0002:pll_inst|altera_pll:altera_pll_i|outclk_wire[0] Maximum fan-out 68382 Total fan-out 910053 Average fan-out 3.92 I have enabled register duplication, now is compiling with three design partitions with logiclock regions with auto size and location. With custom logiclock regions (following altera guidelines) design failed into routing. Thanks- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
sometimes you just have to do manual register duplication in the HDL - its not too hard, but a little tedious.
Find some regs (a PLL is obviously going to have a high fanout) with a high fan out and use the maxfan attribute on them in the hdl, so that synthesis automatically duplicates a register when the fanout gets too high. Or you can manually duplicate the register and use the preserve synthesis attribute to prevent the two being merged. Then have separate parts of the design fed from the two separate (but identical) registers.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The PLL is on a global which has dedicated routing, so the fanout doesn't matter. Only 4 pins to the external world? That's impressive.
I think you've just hit a wall and will probably have to remove some logic, which admittedly is not easy. There's no guarantee that a device can be filled that full and always fit. (Although I have seen some impressive thing, like the largest Stratix V GX BB device filled to 99% Logic Utilization which I would have said would never fit.) Two designs of the same Logic Utilization can have significantly different routing requirements, or at least enough to have one always fit and one not fit at all.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What may also help is to partition the design into key blocks - ones where there are many internal routes, but a lower number of routes between that block and the rest of the design. What you can then do is add logiclock regions into the design to constrain partitions to certain areas. This can help timing in some cases (brings logic with critical paths closer together), but also can help with routing congestion by avoiding the logic being scattered around in a way which means there is lots of competition for resources.
On a design I'm working on, it is pretty much impossible to get it to route and meet timing without logiclock regions.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, a simple UART to talk to external world.
I tried with max fanout limit of 90 but now I am out of LAB.. I am revisiting reset logic to reduce congestion.. Wow.. a 952K LEs full.. I hope compile times is good enought :)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If it's just a uart, then surely the data rate isnt very high? cant you just re-use some of the logic and process different stages at different times, so you dont use all the logic (and hence the routing) all up?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Data is inserted into system at startup and then a very long algorithm is executed.. at the end data is retrieved to read result. No way to reuse some of the logic..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That sounds highly inefficient. Can't you insert data during run time? What latency is required? If you don't care about latency then you could re use as much logic s you wanted.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This isn't real-time data processing, problem is one-shoot but resolution is very long so need to use parallel computation
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you have as long as you like, then make the calculation use time division multiplex. eg. use one multipler to calculate 8 different values in 8 clocks rather than 8 multipliers to get the value in 1 clock. Stuff like that. Then all you worry about is getting data in and out of ram. The fan out is really small and the routing is simpler.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Nobody else asked so I will. Any chance you can move to a larger device, like an Arria V? Or split the design into two C5s? Stuffing a device to 99% full can be a costly endeavor. Even if you spend the NRE now to squeeze it in, if you ever need to add logic or even fix a bug, you could be in trouble. And with the device that full using SignalTap is impossible. Even if you verify everything in simulation, SignalTap can still be a lifesaver when unexpected things happen in hardware.
I got stuck in this situation once in an Arria II device (99% full) because system requirements changed over time. For a while we got away with it. Then over time a couple of changes were made and it started to fail timing, so I had to slow down the memory clock. Then eventually it just would no longer fit. The extra cost of using a larger device to start with would have been a huge cost savings in the end. And we eventually ended up there anyway. If this is just a prototype or hobby project then have at it and good luck. But going into production with that part 99% full would be extremely risky.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't have as long as I want, it is on FPGA to speed up so I try to get max performance :)
Clearly one day this will go into Stratix/Arria devices OR multiple Cyclone devices but I want to close a demo with just a Cyclone V for demonstration. I don't use 99% but 81% that seem reasonable. Then 14% of ALM are unavailable due to congestion :( By design routing "should" be simple but when divisors (100+) are synthetized with Synplify with pipeline inferred with retiming problem arise.. (12+ hours of RTL compilation + Fitter that fail after 1+ hour).. too things packed.. I have to try to use LPM_DIV with pipeline but this isn't a great option for "portability" of system.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12 hours of RTL compilation? That seems way, way too long. Can you do partitions(I think they have another name for it) in Synplify to reduce that?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, but first time it compile all partitions. I noticed that compiling same design for Spartan6 LX150 is better for compile time (2h+ for RTL).. maybe Synplify is more optimized for Xilinx architecture.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
--- Quote Start --- ... but when divisors (100+) are synthetized ... --- Quote End --- Wow, 100+ dividers! There could be room for improvement? Are all numerators truly dynamic, or are some loaded by the application, or are some constant?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dividers (fixed point) are always 1/X where X change so no tricks..
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why are you doing 1/X divides? are the results of this fed into a multiplier? why not just do Y/X in the first instance?
12+ hours of RTL compile is far far far too long. The longest Ive ever seen (for a very full stratix 4) was 1 hour (with 4-8 hours fit). Do you have some rams that are actually being synthesised as registers? that is usually the culprit for long synthesis (and would then result in a very full and congested chip).- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page