- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
A colleague wrote a small MPI Isend/Recv test case to try to reproduce a performance issue with an application when using RoCE, but the test case hangs with large message sizes when run with 2 or more processes per node across 2 or more nodes. The same test case runs successfully with large message sizes in an environment with Infiniband.
Initially it hung with message sizes larger than 16K but usage of the FI_OFI_RXM_BUFFER_SIZE variable allowed increasing the message size to about 750K. We were trying to get to 1 MB, but no matter how large FI_OFI_RXM_BUFFER_SIZE is set to, the test hangs with a message size of 1 MB. Are there other MPI settings or OS settings that may need to be increased? I also tried setting FI_OFI_RXM_SAR_LIMIT, but that didn't help. Here are the current set of MPI options for the test when using RoCE:
mpi_flags='-genv I_MPI_OFI_PROVIDER=verbs -genv FI_VERBS_IFACE=vlan50 -genv I_MPI_OFI_LIBRARY_INTERNAL=1 -genv I_MPI_FABRICS=shm:ofi -genv FI_OFI_RXM_BUFFER_SIZE=2000000 -genv FI_OFI_RXM_SAR_LIMIT=4000000 -genv I_MPI_DEBUG=30 -genv FI_LOG_LEVEL=debug'
The environment is SLES 15 SP2 with Intel OneAPI Toolkit version 2021.2, with Mellanox CX-6 network adapters in Ethernet mode and 100 Gb Aruba switches. The NICs and switches have been configured for RoCE traffic per guidelines from Mellanox and our Aruba engineering team.
A screenshot of the main loop of MPI code (I will get the full source code from my colleague), along with the output of the test when the message size is 1 MB and I_MPI_DEBUG=30 and FI_LOG_LEVEL=debug are attached. The script that is used to run the test is shown below. The script input parameters are the number of repetitions and message size.
#!/bin/bash
cf_args=()
while [ $# -gt 0 ]; do
cf_args+=("$1")
shift
done
source /opt/intel/oneapi/mpi/2021.3.0/env/vars.sh
set -e
set -u
mpirun --version 2>&1 | grep -i "intel.*mpi"
hostlist='-hostlist perfcomp3,perfcomp4'
mpi_flags='-genv I_MPI_OFI_PROVIDER=verbs -genv FI_VERBS_IFACE=vlan50 -genv I_MPI_OFI_LIBRARY_INTERNAL=1 -genv I_MPI_FABRICS=shm:ofi -genv FI_OFI_RXM_BUFFER_SIZE=2000000 -genv I_MPI_OFI_PROVIDER=verbs -genv FI_OFI_RXM_SAR_LIMIT=4000000 -genv I_MPI_DEBUG=30 -genv FI_LOG_LEVEL=debug -genv I_MPI_OFI_PROVIDER_DUMP=1'
echo "$hostlist"
mpirun -ppn 1 \
$hostlist $mpi_flags \
hostname
num_nodes=$(mpirun -ppn 1 $hostlist $mpi_flags hostname | sort -u | wc -l)
echo "num_nodes=$num_nodes"
mpirun -ppn 2 \
$hostlist $mpi_flags \
singularity run -H `pwd` \
/var/tmp/paulo/gromacs/gromacs_tau.sif \
v4/mpi_isend_recv "${cf_args[@]}"

{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for posting in Intel Communities.
We are working on your issue internally and will get back to you soon.
Thanks & Regards,
Varsha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Attaching the full source code for the Isend/Recv test. Also, here are the settings configured on the Mellanox CX-6 adapter:
perfcomp4:~ # cat mellanox_advanced_tuning.sh
mlxconfig -d 43:00.0 --yes s ADVANCED_PCI_SETTINGS=1
mlxconfig -d 43:00.1 --yes s ADVANCED_PCI_SETTINGS=1
mlxconfig -d 43:00.1 --yes set MAX_ACC_OUT_READ=32
mlxconfig -d 43:00.0 --yes set MAX_ACC_OUT_READ=32
mlxconfig -d 43:00.0 --yes set PCI_WR_ORDERING=1
mlxconfig -d 43:00.1 --yes set PCI_WR_ORDERING=1
mlxfwreset -d 0000:43:00.0 --level 3 -y reset
perfcomp4:~ # cat config_mellanox_roce.sh
# Use ip link to set priority 3 on vlan_50
ip link set vlan50 type vlan egress 2:3
# set DSCP to 26 and PRIO to 3
mlxconfig -y -d 0000:43:00.0 set CNP_DSCP_P1=26 CNP_802P_PRIO_P1=3
mlxconfig -y -d 0000:43:00.1 set CNP_DSCP_P2=26 CNP_802P_PRIO_P2=3
mlxfwreset -d 0000:43:00.0 --level 3 -y reset
# set tos to 106
echo 106 > /sys/class/infiniband/mlx5_bond_0/tc/1/traffic_class
cma_roce_tos -d mlx5_bond_0 -t 106
# set trust pcp and set pfc for queue 3
mlnx_qos -i ens2f0 --trust pcp
mlnx_qos -i ens2f0 --pfc 0,0,0,1,0,0,0,0
mlnx_qos -i ens2f1 --trust pcp
mlnx_qos -i ens2f1 --pfc 0,0,0,1,0,0,0,0
# enable ECN for TCP
sysctl -w net.ipv4.tcp_ecn=1
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My colleague built the test case using Open MPI, and it runs to completion with Open MPI. So it appears, that we're missing some setting to allow it to work with Intel MPI, or there is a network or kernel setting that impacts the test case when using Intel MPI. Appreciate any insight that you may have.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Some additional info when the MPI provider is changed from verbs to the default setting of psm3:
If the following MPI flags are removed from the script to run the testcase, allowing the default settings to be selected, the testcase runs to completion with a message size of 1 MB:
mpi_flags='-genv I_MPI_OFI_PROVIDER=verbs -genv FI_VERBS_IFACE=vlan50 -genv I_MPI_OFI_LIBRARY_INTERNAL=1 -genv I_MPI_FABRICS=shm:ofi'
Setting I_MPI_DEBUG=10 shows that the provider when no flags are set is psm3:
[0] MPI startup(): libfabric provider: psm3
However, the Intel MPI documentation says that psm3 is for Intel NICs, and I am using Mellanox CX-6 NICs:
- PSM3 supports standard Ethernet networks and leverages standard RoCEv2 protocols as implemented by the Intel® Ethernet Fabric Suite NICs
Looking at tcpdump data collected during the run of the testcase, the tcpdump data with the psm3 provider differs from tcpdump data with the verbs provider:
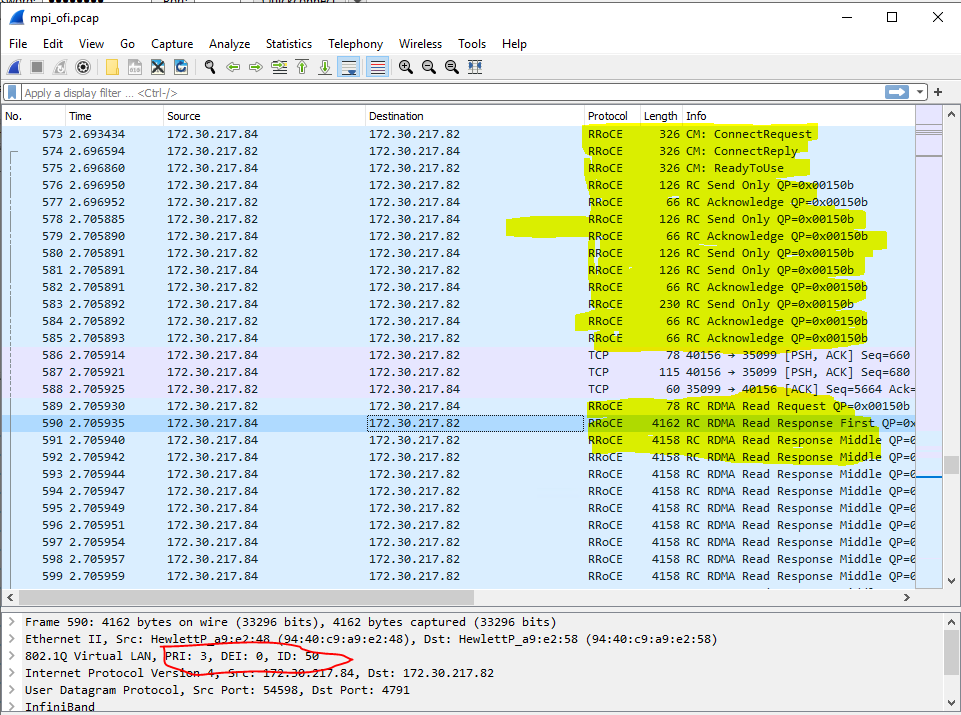
- The protocol is shown as RoCE, whereas with the verbs provider, the protocol is shown as RRoCE.
- With psm3, there are many fewer entries in the tcpdump data that are marked as RoCE as compared to the RRoCE entries seen with the verbs provider. All of the entries are shown as “UD Send Only”, whereas with the verbs provider, there are many types of entries, including “RD Send Only”, RD Acknowledge, RDMA Read Request, RDMA Read Response First, RDMA Read Response Middle, RDMA Read Response End.
- In addition, both the NICs and the Aruba switches are configured to set RoCE traffic to priority 3, which is allowed more bandwidth on the switch than other traffic. However, when the psm3 provider is used, the RoCe traffic seen in the tcpdump data is shown with priority 0.
The attached file named mpi_psm3.pcap.png is a sample of the tcpdump data shown in wireshark for the case where the provider is psm3. Note that the only RoCE traffic is “UD Send Only” and the priority is 0.
The attached file named mpi_verbs.pcap.png is a sample of the tcpdump data when the provider is verbs. Notice that there are many types of RRoCE entries and the priority is set to 3.
My understanding was that I should be using the verbs provider to use RoCE protocol with the Mellanox CX-6 provider. What am I missing to get the testcase to run to completion with a message size of 1 MB?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here are the screenshots of the tcpdump data mentioned in the last post (see attached files)
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Karen,
Can you check the UCX version? With Intel MPI 2021.2 and above UCX version needs to be >1.6.
to check UCX version:
~> ucx_info -v
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The UCX version is 1.10.0:
perfcomp3:~ # ucx_info -v
# UCT version=1.10.0 revision 7477e81
# configured with: --host=x86_64-suse-linux-gnu --build=x86_64-suse-linux-gnu --program-prefix= --disable-dependency-tracking --prefix=/usr --exec-prefix=/usr --bindir=/usr/bin --sbindir=/usr/sbin --sysconfdir=/etc --datadir=/usr/share --includedir=/usr/include --libdir=/usr/lib64 --libexecdir=/usr/lib --localstatedir=/var --sharedstatedir=/var/lib --mandir=/usr/share/man --infodir=/usr/share/info --disable-dependency-tracking --disable-optimizations --disable-logging --disable-debug --disable-assertions --enable-mt --disable-params-check --without-java --enable-cma --without-cuda --without-gdrcopy --with-verbs --without-cm --with-knem --with-rdmacm --without-rocm --without-xpmem --without-ugni --disable-numa
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I ran some additional tests, varying the number of processes per node (ppn), and running multiple iterations of the test. With 2 ppn, the test hangs on the first iteration. With 4 or 16 ppn, multiple iterations can be run, but eventually the test hangs:
|
|
2 nodes |
4 nodes |
|
2 ppn |
Hangs on 1st repetition |
Hangs on 1st repetition |
|
4 ppn |
Hangs on 28th repetition |
Hangs on 8th repetition |
|
16 ppn |
Hangs on 10th repetition |
Hangs on 2nd repetition |
When the test hangs, all of the processes are consuming 100% CPU, so perhaps they are all spinning and waiting on some resource. Do you have any recommendations on how to determine what it's waiing for?
Note that the same test case runs successfully with Open MPI. The 4-node 16 ppn test was getting very high latency, but that was resolved by setting UCX_RNDV_THRESH to a value higher than the message size (in this case the message size is 1 MB and I set UCX_RNDV_THRESH to 2 MB). With Intel MPI, I have already set FI_OFI_RXM_BUFFER_SIZE=2000000, but that only allowed running with a message size up to 750 MB for the 2-node, 2 ppn test.
Is it possible to use the UCX options with Intel MPI and the verbs provider? Or is the mlx provider (which I believe requires Infiniband) required to use UCX?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please try MLX provider as it covers RoCE as well as IB. With MLX provider you may use same set of UCX-level controls you are using with OpenMPI+UCX if needed.
Can you run command $ ibv_devinfo and send me the details. (need to know which transport it is using)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here is the output from the ibv_devinfo command:
perfcomp3:~ # ibv_devinfo
hca_id: mlx5_bond_0
transport: InfiniBand (0)
fw_ver: 20.30.1004
node_guid: 9440:c9ff:ffa9:e258
sys_image_guid: 9440:c9ff:ffa9:e258
vendor_id: 0x02c9
vendor_part_id: 4123
hw_ver: 0x0
board_id: MT_0000000453
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 4096 (5)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
I tried using the UCX options with the mlx provider, but am getting errors about using that provider:
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn.sh --repetitions 1 --size 1000000
Intel(R) MPI Library for Linux* OS, Version 2021.3 Build 20210601 (id: 6f90181f1)
-hostlist perfcomp3,perfcomp4
perfcomp3
perfcomp4
num_nodes=2
[0] MPI startup(): Intel(R) MPI Library, Version 2021.3 Build 20210601 (id: 6f90181f1)
[0] MPI startup(): Copyright (C) 2003-2021 Intel Corporation. All rights reserved.
[0] MPI startup(): library kind: release
[0] MPI startup(): shm segment size (1580 MB per rank) * (2 local ranks) = 3160 MB total
[2] MPI startup(): shm segment size (1580 MB per rank) * (2 local ranks) = 3160 MB total
[0] MPI startup(): libfabric version: 1.12.1-impi
Abort(1091215) on node 2 (rank 2 in comm 0): Fatal error in PMPI_Init: Other MPI error, error stack:
MPIR_Init_thread(138)........:
MPID_Init(1169)..............:
MPIDI_OFI_mpi_init_hook(1419): OFI addrinfo() failed (ofi_init.c:1419:MPIDI_OFI_mpi_init_hook:No data available)
Here are the UCX options that I tried:
mpi_flags='-genv I_MPI_OFI_PROVIDER=mlx -genv I_MPI_FABRICS=shm:ofi -genv UCX_TLS=self,rc,dc,ud -genv UCX_NET_DEVICES=mlx5_bond_0:1 -genv UCX_RNDV_THRESH=2000000 -genv UCX_IB_SL=3 -genv UCX_IB_TRAFFIC_CLASS=106 -genv UCX_IB_GID_INDEX=3 -genv I_MPI_DEBUG=10'
All of the UCX options except UCX_TLS have been used successfully with the Open MPI version of this testcase. I added UCX_TLS because I found the following info that says that UCX_TLS must be explicitly set when using Intel MPI with AMD processors (and the test case was also failing with the same error shown above before I added UCX_TLS):
https://github.com/openucx/ucx/issues/6253
Here are the available transports from the ucx_info command:
perfcomp4:/var/tmp/pcap # ucx_info -d | grep Transport
# Transport: posix
# Transport: sysv
# Transport: self
# Transport: tcp
# Transport: tcp
# Transport: tcp
# Transport: rc_verbs
# Transport: rc_mlx5
# Transport: dc_mlx5
# Transport: ud_verbs
# Transport: ud_mlx5
# Transport: cma
Here is the mpirun command line when using the Open MPI version of the test case:
mpirun -np $num_proc \
--machinefile hfile_karen \
--prefix /var/tmp/paulo/openmpi-4.1.2 \
--map-by ppr:8:socket --report-bindings \
--mca btl ^openib \
--mca pml ucx -x UCX_IB_SL=3 -x UCX_NET_DEVICES=mlx5_bond_0:1 -x UCX_IB_TRAFFIC_CLASS=106 -x UCX_IB_GID_INDEX=3 \
--allow-run-as-root \
./runme.sh
What are the proper options to use to allow UCX to be used with Intel MPI?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There have been several email exchanges in the past week, but none of the suggestions have resolved the issue. I tried using I_MPI_OFI_PROVIDER=mlx and FI_MLX_NET_DEVICES=mlx5_bond_0:1, but this results in the message "no mlx device is found". So it's not clear that the mlx provider can be used with the Mellanox CX-6 adapter in Ethernet mode with RoCE protocol. So I'm still trying to understand how to use UCX options with Intel MPI. My test case runs successfully with Open MPI and UCX options, but hangs with Intel MPI with the provider set to verbs if the message size is 1 MB, and it fails with an error with the provider set to mlx. Further details are provided in the email exchange shown below, and the output from setting log level to debug with the mlx provider is attached.
Sent: Thursday, March 31, 2022 11:34 AM
Hi Julia,
Thanks for the suggestion. The error message remains the same when using FI_MLX_NET_DEVICES. The output with log level set to debug is attached. The MPI options that were used and some of the output with the error message is shown below. I’m still puzzled about the suggestion to use the mlx provider, since the Intel MPI documentation indicates that it is for usage with Mellanox Infiniband hardware. I am using the Mellanox CX-6 adapter, but it is configured in Ethernet mode, not Infiniband, and I don’t have Infiniband switches. The network adapters and switches are configured for RoCE. I was trying to use the UCX options with Intel MPI because this test case that fails with Intel MPI is working fine with Open MPI and UCX options on this same hardware. I’m trying to determine if it’s possible to use the UCX options with Intel MPI. Note that originally I was using I_MPI_OFI_PROVIDER=verbs but the test case was hanging with a message size of 1 MB. Any further advice on how to get the test to work with Intel MPI and UCX (or other options) are much appreciated. The full details of the original case are posted here:
Thanks,
Karen
mpi_flags='-genv I_MPI_OFI_PROVIDER=mlx -genv I_MPI_FABRICS=shm:ofi -genv FI_MLX_NET_DEVICES=mlx5_bond_0:1 -genv I_MPI_DEBUG=10 -genv FI_LOG_LEVEL=debug'
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn.sh --repetitions 1 --size 1000000 2>&1 | tee launch_mpi_isend_recv_v4_2ppn_ompi_debug_MLXdev.out
libfabric:16416:verbs:fabric:verbs_devs_print():880<info> list of verbs devices found for FI_EP_MSG:
libfabric:16416:verbs:fabric:verbs_devs_print():884<info> #1 mlx5_bond_0 - IPoIB addresses:
libfabric:16416:verbs:fabric:verbs_devs_print():894<info> 172.30.217.84
libfabric:16416:verbs:fabric:vrb_get_device_attrs():618<info> device mlx5_bond_0: first found active port is 1
libfabric:16419:mlx:core:mlx_getinfo():171<info> no mlx device is found.
libfabric:16419:core:core:ofi_layering_ok():964<info> Need core provider, skipping ofi_rxm
Abort(1091215) on node 2 (rank 2 in comm 0): Fatal error in PMPI_Init: Other MPI error, error stack:
MPIR_Init_thread(138)........:
MPID_Init(1169)..............:
MPIDI_OFI_mpi_init_hook(1419): OFI addrinfo() failed (ofi_init.c:1419:MPIDI_OFI_mpi_init_hook:No data available)
Sent: Thursday, March 31, 2022 6:56 AM
Hi Karen,
Could you please replace UCX_NET_DEVICES environment variable to FI_MLX_NET_DEVICES and rerun with FI_LOG_LEVEL=debug, FI_PROVIDER=mlx?
BRs,
Julia
Sent: Wednesday, March 30, 2022 8:25 PM
Hi Alex,
Thanks for the suggestions. The output with log level set to debug is attached. With Open MPI, I was using UCX_NET_DEVICES=mlx5_bond_0:1, but when using Intel MPI with that setting and I_MPI_OFI_PROVIDER=mlx, I see that it says no Mellanox device is found:
libfabric:9588:mlx:core:mlx_getinfo():171<info> no mlx device is found.
Looks like it is seeing mlx_bond_0 as a verbs device:
libfabric:31635:verbs:fabric:vrb_get_device_attrs():618<info> device mlx5_bond_0: first found active port is 1
But I am trying to use the mlx provider so that I could specify the UCX options. The servers have dual-port CX-6 Mellanox adapters configured with Ethernet mode and the two ports are configured in a bond. The NICs and Aruba 100Gb switches are configured for RoCE. Is that compatible with using the mlx provider? If so, what device name should be specified? With Intel MPI and the verbs provider, I was specifying FI_VERBS_IFACE=vlan50. The vlan device vlan50 is configured on top of the bond for the Mellanox adapter. With OpenMPI, I was using UCX_IB_GID_INDEX=3, which corresponds to the vlan50 device with RoCE v2:
perfcomp4: # /usr/sbin/show_gids
DEV PORT INDEX GID IPv4 VER DEV
--- ---- ----- --- ------------ --- ---
mlx5_bond_0 1 0 fe80:0000:0000:0000:9640:c9ff:fea9:e248 v1 bond0
mlx5_bond_0 1 1 fe80:0000:0000:0000:9640:c9ff:fea9:e248 v2 bond0
mlx5_bond_0 1 2 0000:0000:0000:0000:0000:ffff:ac1e:d954 172.30.217.84 v1 vlan50
mlx5_bond_0 1 3 0000:0000:0000:0000:0000:ffff:ac1e:d954 172.30.217.84 v2 vlan50
n_gids_found=4
I tried setting UCX_NET_DEVICES=vlan50 but that gives the same errors as when using UCX_NET_DEVICES=mlx5_bond_0:1. Also, not specifying UCX_NET_DEVICES at all yields the same error.
Also, you requested, “please align UCX settings for IMPI and OpenMPI”. Which settings are you suggesting that I add or remove? This is what I am using with Intel MPI and UCX options:
mpi_flags='-genv I_MPI_OFI_PROVIDER=mlx -genv I_MPI_FABRICS=shm:ofi -genv UCX_TLS=self,rc,dc,ud -genv UCX_NET_DEVICES=mlx5_bond_0:1 -genv UCX_RNDV_THRESH=2000000 -genv UCX_IB_SL=3 -genv UCX_IB_TRAFFIC_CLASS=106 -genv UCX_IB_GID_INDEX=3 -genv I_MPI_DEBUG=10 -genv FI_LOG_LEVEL=debug'
This is what I am using with Open MPI:
--mca pml ucx -x UCX_IB_SL=3 -x UCX_NET_DEVICES=mlx5_bond_0:1 -x UCX_IB_TRAFFIC_CLASS=106 -x UCX_IB_GID_INDEX=3 -x UCX_RNDV_THRESH=2000000
Note that UCX_TLS=self,rc,dc,ud was only added after receiving errors using I_MPI_OFI_PROVIDER=mlx with Intel MPI. The errors are the same regardless of whether that option is used or not.
Thanks,
Karen
Sent: Wednesday, March 30, 2022 4:21 AM
Hi Karen,
Could you please add FI_LOG_LEVEL=debug and provide a log for this run. That would allow to identify root cause of the problem with mlx provider.
Additionally could you please align UCX settings for IMPI and OpenMPI?
Thanks in advance.
> What are the proper options to use to allow UCX to be used with Intel MPI?
In general, FI_PROVIDER=mlx or I_MPI_OFI_PROVIDER=mlx should be enough.
-
With best regards, Alex.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Karen,
1) can you try it using a newer libfabric? The one shipped by IMPI is 1.12.1 but the newest should be 1.15.0
2) can you reproduce this issue in an Intel machine with the newest libfabric?
3) if yes, can you show where the call hangs, e.g. by using gstack?
Cheers,
Rafael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
According to my benchmark output, Intel MPI 2021.4 is using libfabric 1.13.0-impi and 2021.5 is using 1.13.rc1-impi. Where can I get the Intel version of 1.15? I tried downloading and building libfabric 1.15.1 from github and decided to first try it with Intel MPI 2021.4 because 2021.4 was already working with my test case. I modified
/opt/intel/oneapi/mpi/2021.4.0/env/vars.sh
to point to point to the libfabric 1.15.1 directory but the test is getting a segfault, and says that provider mlx is unknown. The github version of 1.15.1 didn't have a libfabric/lib/prov directory, so I had just left it pointing to the original 2021.4 directory. Here's what I changed in vars.sh
case "$i_mpi_ofi_library_internal" in
0|no|off|disable)
;;
*)
PATH="${I_MPI_ROOT}/${PLATFORM}/libfabric/bin:${PATH}"; export PATH
# LD_LIBRARY_PATH="${I_MPI_ROOT}/${PLATFORM}/libfabric/lib:${LD_LIBRARY_PATH}"; export LD_LIBRARY_PATH
LD_LIBRARY_PATH="/root/libfabric/libfabric-1.15.1/src/.libs:${LD_LIBRARY_PATH}"; export LD_LIBRARY_PATH
if [ -z "${LIBRARY_PATH}" ]
then
# LIBRARY_PATH="${I_MPI_ROOT}/${PLATFORM}/libfabric/lib"; export LIBRARY_PATH
LIBRARY_PATH="/root/libfabric/libfabric-1.15.1/src/.libs"; export LIBRARY_PATH
else
# LIBRARY_PATH="${I_MPI_ROOT}/${PLATFORM}/libfabric/lib:${LIBRARY_PATH}"; export LIBRARY_PATH
LIBRARY_PATH="/root/libfabric/libfabric-1.15.1/src/.libs:${LIBRARY_PATH}"; export LIBRARY_PATH
fi
FI_PROVIDER_PATH="${I_MPI_ROOT}/${PLATFORM}/libfabric/lib/prov:/usr/lib64/libfabric"; export FI_PROVIDER_PATH
;;
esac
The output from the test case when using libfabric 1.15.1 is attached. The output is showing:
[0] MPI startup(): libfabric version: 1.15.1
libfabric:56808:1653261977::core:core:verify_filter_names():562<warn> provider mlx is unknown, misspelled or DL provider?
[perfcomp3:56808:0:56808] Caught signal 11 (Segmentation fault: address not mapped to object at address (nil))
==== backtrace (tid: 56808) ====
0 /usr/lib64/libucs.so.0(ucs_handle_error+0xe4) [0x15548926e6d4]
1 /usr/lib64/libucs.so.0(+0x21a4c) [0x15548926ea4c]
2 /usr/lib64/libucs.so.0(+0x21c02) [0x15548926ec02]
3 /lib64/libpthread.so.0(+0x132d0) [0x1555534962d0]
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I found out that it's necessary to enable the providers when building libfabric. Following the directions found here:
https://github.com/ofiwg/libfabric
--enable-<provider>=[yes|no|auto|dl|<directory Using ./configure --enable-verbs=dl builds the verbs provider, but the mlx provider does not exist (it isn't documented on the site listed above, and an error is received when attempting to use --enable-mlx=dl :
erfcomp3:~/libfabric/libfabric-1.15.1 # ./configure --enable-mlx=dl --enable-verbs=dl
configure: WARNING: unrecognized options: --enable-mlx
***
*** Built-in providers: opx dmabuf_peer_mem hook_hmem hook_debug perf rstream shm rxd mrail rxm tcp udp sockets psm2
*** DSO providers: verbs
Where can I get a copy of libfabric 1.15 that has the mlx provider?
Thanks,
Karen
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Karen!
That is correct, mlx provider is available in our build of libfabrics and is not present in the opensource repository. Can you please test with your original settings i.e. I_MPI_OFI_PROVIDER=verbs, or unset?
Cheers!
Rafael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I was able to get the test case to work with the open source version of libfabric 1.15.1 by either
1) specifying the verbs provider with FI_PROVIDER=verbs
2) not explicitly specifying a provider (in which case the verbs provider was used).
Note that using I_MPI_OFI_PROVIDER=verbs didn't work with the open source libfabric. It throws the error "MPIDI_OFI_mpi_init_hook:No data available"
So it appears that the initial problem of the test case hanging with the verbs provider is related to the use of libfabric 1.13 that ships with Intel MPI.
Note that even though the test case works with the verbs provider and libfabric 1.15.1, the performance is very poor as compared to using the mlx provider with Intel MPI 2021.4 and libfabric 1.13. For the latter combination, the test case with a message size of 1 MB had a latency of 325 us, while the same test case with the verbs provider and libfabric 1.15.1 has a latency that was 3820 us, over a factor of 10 longer than with the mlx provider (see output below).
Does Intel have plans to update Intel MPI to use libfabric 1.15.1? Will the mlx provider be included?
Thanks,
Karen
Here is the output of the test case when using Intel MPI 2021.4 and the mlx provider. Note that latency is 325us.
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM.sh --repetitions 1 --size 1000000 2>&1 | tee launch_mpi_isend_recv_v4_2ppn_BM_2021.4.log
[0] MPI startup(): libfabric version: 1.13.0-impi
[0] MPI startup(): libfabric provider: mlx
[0] MPI startup(): I_MPI_ROOT=/opt/intel/oneapi/mpi/2021.4.0
[0] MPI startup(): I_MPI_MPIRUN=mpirun
[0] MPI startup(): I_MPI_HYDRA_TOPOLIB=hwloc
[0] MPI startup(): I_MPI_INTERNAL_MEM_POLICY=default
[0] MPI startup(): I_MPI_FABRICS=shm:ofi
[0] MPI startup(): I_MPI_OFI_PROVIDER=mlx
[0] MPI startup(): I_MPI_DEBUG=10
nrep = 1
sendcount = 1000000
recvcount = 1000000
wtime = 0.001
Bandwidth per receiver process = 3080.514 MB/s
MPI_Recv latency = 324.621 us
Here is the output of the test case when using Intel MPI 2021.4 with libfabric 1.15.1 and not explicitly specifying a provider, which results in the verbs provider being used. Note that latency is 3821us, an increase of over a factor of 10.
mpi_flags='-genv I_MPI_DEBUG=10'
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM_libfabric1.15.1.sh --repetitions 1 --size 1000000 | tee launch_mpi_isend_recv_v4_2ppn_BM_libfabric1.15.1_noprovider.log
[0] MPI startup(): libfabric version: 1.15.1
[0] MPI startup(): libfabric provider: verbs;ofi_rxm
[0] MPI startup(): I_MPI_ROOT=/opt/intel/oneapi/mpi/2021.4.0
[0] MPI startup(): I_MPI_MPIRUN=mpirun
[0] MPI startup(): I_MPI_HYDRA_TOPOLIB=hwloc
[0] MPI startup(): I_MPI_INTERNAL_MEM_POLICY=default
[0] MPI startup(): I_MPI_DEBUG=10
nrep = 1
sendcount = 1000000
recvcount = 1000000
wtime = 0.011
Bandwidth per receiver process = 261.718 MB/s
MPI_Recv latency = 3820.901 us
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had been running a single iteration of the mpi_isend_recv test case for debugging purposes, but recalled that running with more iterations (e.g. 100 iterations) significantly reduces the latency reported. With 100 iterations, using the verbs provider with libfabric 1.15.1 actually gives lower latency than the mlx provider with libfabric 1.13. In both cases Intel MPI 2021.4 was used, but it's not strictly an apples-to-apples comparison because different versions of libfabric are used. But I don't have a version of libfabric 1.15.1 with the mlx provider, and the test hangs with the verbs provider and libfabric 1.13.
Here are the results with the verbs provider and libfabric 1.15.1:
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM_libfabric1.15.1.sh --repetitions 100 --size 1000000
[0] MPI startup(): Intel(R) MPI Library, Version 2021.4 Build 20210831 (id: 758087adf)
[0] MPI startup(): libfabric version: 1.15.1
[0] MPI startup(): libfabric provider: verbs;ofi_rxm
nrep = 100
sendcount = 1000000
recvcount = 1000000
wtime = 0.031
Bandwidth per receiver process = 9744.114 MB/s
MPI_Recv latency = 102.626 us
Here are the results with the mlx provider and libfabric 1.13.0:
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM.sh --repetitions 100 --size 1000000
Intel(R) MPI Library for Linux* OS, Version 2021.4 Build 20210831 (id: 758087adf)
[0] MPI startup(): libfabric version: 1.13.0-impi
[0] MPI startup(): libfabric provider: mlx
nrep = 100
sendcount = 1000000
recvcount = 1000000
wtime = 0.047
Bandwidth per receiver process = 6403.591 MB/s
MPI_Recv latency = 156.162 us
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good news: we noticed that Intel MPI 2021.6 is now available and the mpi_isend_recv test case runs successfully for both the verbs and the mlx provider, and both get similar performance. Interestingly, 2021.6 ships with the same version of libfabric as 2021.5.1 (libfabric 1.13.2rc1-impi), so it's not clear that libfabric was the cause of the segfaults with Intel MPI 2021.5.1. Here's a summary of which combinations of Intel MPI, libfabric, and providers worked and which ones failed:
| Intel MPI version | libfabric version | provider | result |
| 2021.4.0 | 1.13.0-impi | mlx | runs |
| verbs | hangs | ||
| 2021.5.1 | 1.13.2.rc1-impi | mlx | seg fault |
| verbs | segfault | ||
| 2021.6.0 | 1.13.2.rc1-impi | mlx | runs |
| verbs | runs |
With 100 iterations of the test, performance (latency) is similar for the mlx and verbs provider with Intel MPI 2021.6:
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM.sh --repetitions 1 --size 1000000
[0] MPI startup(): Intel(R) MPI Library, Version 2021.6 Build 20220227 (id: 28877f3f32)
[0] MPI startup(): libfabric version: 1.13.2rc1-impi
[0] MPI startup(): max number of MPI_Request per vci: 67108864 (pools: 1)
[0] MPI startup(): libfabric provider: mlx
nrep = 100
sendcount = 1000000
recvcount = 1000000
wtime = 0.039
Bandwidth per receiver process = 7623.593 MB/s
MPI_Recv latency = 131.172 us
perfcomp3:/var/tmp/paulo/mpi_tests # sh launch_mpi_isend_recv_v4_2ppn_BM.sh --repetitions 100 --size 1000000
Intel(R) MPI Library for Linux* OS, Version 2021.6 Build 20220227 (id: 28877f3f32)
[0] MPI startup(): libfabric version: 1.13.2rc1-impi
[0] MPI startup(): max number of MPI_Request per vci: 67108864 (pools: 1)
[0] MPI startup(): libfabric provider: verbs;ofi_rxm
nrep = 100
sendcount = 1000000
recvcount = 1000000
wtime = 0.040
Bandwidth per receiver process = 7443.520 MB/s
MPI_Recv latency = 134.345 us
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Karen,
First, I would like to apologize for the delay in replying. Second, that sounds like great news! I will forward the results of your tests to the engineering team.
If I understood it correctly, the issue has been resolved. Is that correct?
Cheers!
Rafael
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page