- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, I am using MKL-Pardiso solver to solve a asymmetric sparse matrix. The calculation time for pardiso-solver does not decrease when I increase the threads number. Here are some related information.
1.The computer has 32 cores.
2. I am using OpenMP to do parallel computing. I have set 'call mkl_set_dynamic(0), call mkl_set_num_threads(threads number)'
3. When I increase the threads number (e.g. from 1 to 12), the calculation time for pardiso solver increase a lot instead of decrease. However, the other parts of the code which use OpenMP parallel computing do show a decrease on computational time.
I am really confused. Hope somebody can help me. Thanks a lot.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I know nothing! I did however read at https://www.pardiso-project.org/ "Important: Please note that the Intel MKL version of PARDISO is based on our version from 2006 and that a lot of new features and improvements of PARDISO are not available in the Intel MKL library." Maybe others will comment. Maybe the MKL forum is a better place?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks a lot for your reply. According to the link you posted, it seems pardiso 7.2 got a lot of improvements comparing to mkl_pardiso. I am using a very old version of fortran, will it compatible with pardiso 7.2?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
why are you using a "very old" Fortran when the current OneAPI fortran is Free to use? What version do you have?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is Fortran XE 2013. Our seniors code is based on that version. I just don't want to modify too much.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
IF your are calling MKL from within an OpenMP parallel region, you should be linking with the MKL sequential library.
On the other hand
IF your are calling MKL from a sequential application, you should be linking with the MKL threaded library.
On the other other hand
IF your are calling MKL from the sequential portion of a threaded application, you should be linking with the MKL threaded library .AND. only call from the main thread (same thread always) .AND. set the environment variable KMP_BLOCKTIME=0
Note, IIF your 12 thread OpenMP application is calling MKL threaded library from within an OpenMP parallel region, each of the 12 threads upon call to MKL will instantiate its own thread team of 12 threads. IOW 144 threads will be in play, and performance will be awful.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks a lot. I am calling MKL from the sequential application. However, in the VS2012 Fortran XE2013, there is no MKL threaded library. The attached figure shows the MKL library it has. Does it due to the version? Thank you.
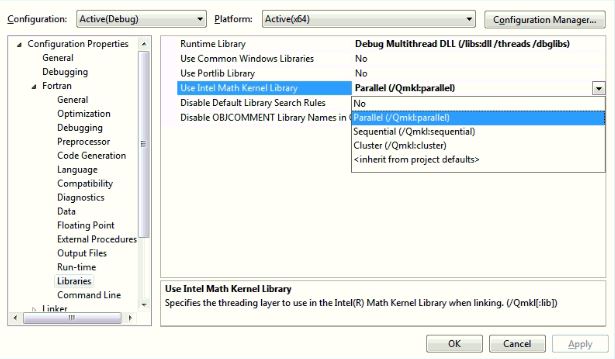{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello!
First, there have been a lot of unsupported claims by PARDISO Project. Second, MKL PARDISO has been developed independently from that project for quite some time already (since 2006) and there were many people who has improved the solver since then at Intel MKL. So while two solvers have a common past, it will not be correct to think that MKL PARDISO has the same performance as PARDISO in 2006.
For the issue you're describing, we need to know more details. It doesn't sound right at all that you see negative scalability.
Can you share the following?
1) iparm settings
2) set msglvl = 1 and share output produced by PARDISO.
or (and I'd prefer this option if it is possible)
3) a small working reproducer which shows how you call PARDISO for one of your matrices (so that we can check performance on our side). So we need a code which shows how you call PARDISO + matrix data
Best,
Kirill
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have run into the same issue with cluster_sparse_solver . The problem has been how I call the program and set the OMP_NUM_THREADS variable. What works for me using InteloneAPI is:
On one machine:
export OMP_NUM_THREADS=number_of_physical cpus
mpirun -np 1 -ppn 1 ./a.out
For multi-node ( replace X with # of nodes
export OMP_NUM_THREADS=number_of_physical cpus
mpirun -np 2 -ppn 1 -hosts host1,host2 ./a.out
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page