- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
We are currently developing a distributed version of our c++ finite element program. We planned to use the Intel Direct Sparse Solver for Cluster but it seems we can't reach good scalability with our settings. The matrix is assumed non symmetric and built in the DCSR format.
The test case used is a simple thermal diffusion problem on a square grid. Different sizes of problem, ranging from 1M to 25M DOF, have been tested with many combinations of MPI processes and OpenMP threads (usually with 1 MPI process by node or by socket). Memory allocated at factorization phase is scaling down but we observed small speed-up on running time.
Actually, we observed these behaviors:
- Symbolic factorization benefits from more MPI processes but is not affected by threads.
- Factorization scales with number of OpenMP threads and sometimes with MPI.
- Most of the time, results shows no significant gain on solving phase for both parallelization.
I must be doing something wrong but i can't seem to find the solution to the problem.
Thanks a lot for any advice
The following iparm variables are used:
iparm(0) = 1;
iparm(1) = 10;
iparm(7) = 2;
iparm(9) = 13;
iparm(10) = 1;
iparm(12) = 1;
iparm(34) = 1;
iparm(39) = 2;
iparm(40,41) = first and last line of local matrix
The code is compiled with 2017 Intel compiler and Intel MPI. Compilation flags used are : -03 -qopenmp -mkl=parallel and
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Emond. what version of MKL do you use? is that MKL 2017 or 2019?
if you want to use Direct Solvers for Clusters, you need to link with some of mpi based libs, using mkl=parallel option will allow to link with SMP version of Intel Pardiso. Please refer to the MKL Linker Adviser to see how to link when you need to use Direct Solver for Cluster.
nevertheless, what scalability result do you observe?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am using MKL 2017
To link with mpi and mkl libs, I use these linking flags :
-lmkl -lmkl_intel_lp64 -lmkl_core -lmkl_blacs_intelmpi_lp64 -mkl_scalapack_lp64 -lpthread -lm -ldl -lmpi
I just realized its not exactly the same as the MKL linker adviser. I will check if it changes anything.
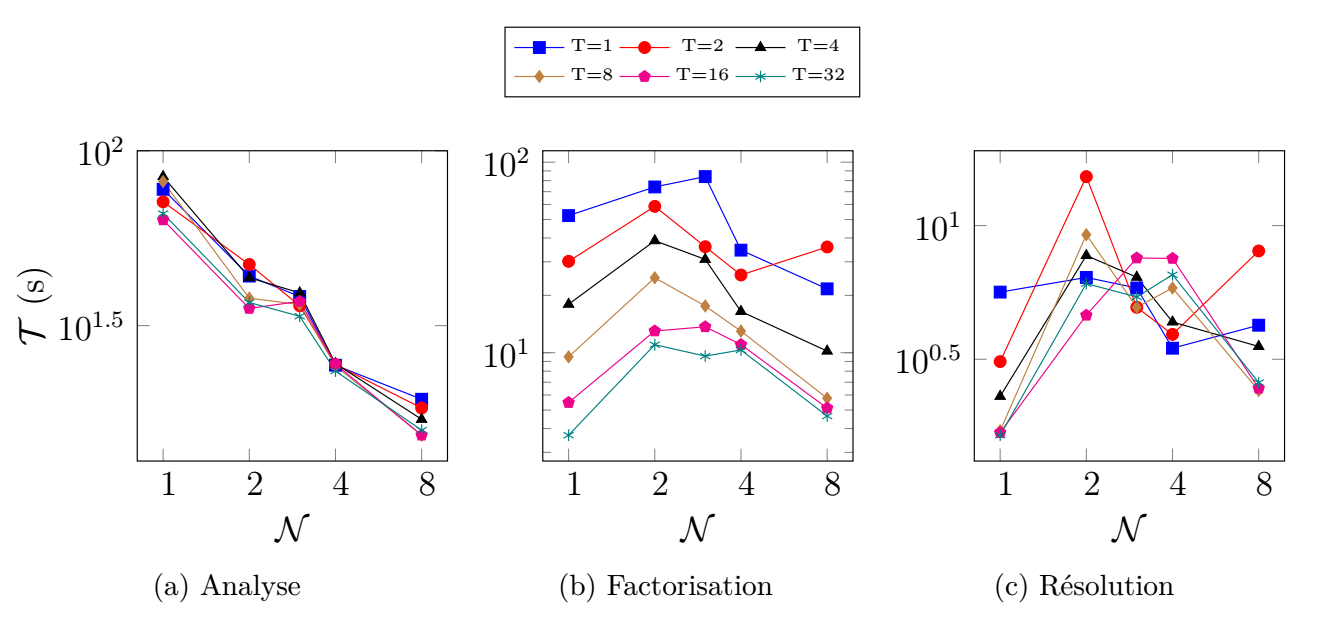
The attached figure shows our typical running times of a 6.5M DOF problem for analysis, factorization and solving phases. N & T are respectively the number of nodes (1 process per nodes) and threads per nodes.
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
It seems linking options were not the probleme because same issues still occurs with the exact same options taken from linker advisor.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could we ask you to try the latest MKL 2019 and check if the scalability problem will be the similar? or please give us the reproducer with these input data to check the problem on our side. thanks Gennady
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I noticed this post is about a year old and wonder what was the outcome. I have just submitted a help request ticket on a similar issue with 2019 version MKL. I am not seen any monotonicity in scaling neither by MPI nor OMP (except MPI=1). See attached report. The solver itself blends perfectly with our code and I am keeping my fingers crossed.
Thanks
Endel
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page