- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good day, I have a parallel program based on the MKL library. Recently, I have got access to a 28 core machine with two Intel Xeon E5-2690 processors with 256 Gbytes RAM. Soon I have noticed that my program execution time depends on the number of threads quite unexpectedly. It grows with number of threads increasing starting from 14 threads.
Then I have done some simple parallel scalability tests presented in the attached main.cpp and got the following interesting results (number of threads against wall time):
gesv, inversion of a matrix of linear size 45'000
2 12:12.40
3 12:09.93
4 6:16.89
5 6:19.99
6 4:16.09
8 3:11.99
10 2:36.16
12 2:11.92
15 2:07.66
18 1:36.31
23 1:24.16
27 1:18.03
gesv_multipl, 3'000'000 inversions of a matrix of linear size 100
2 5:18.72
3 5:14.52
4 5:13.01
5 5:14.08
6 5:18.92
8 5:29.00
10 6:05.00
12 6:09.86
15 13:48.54
18 12:50.62
23 6:30.92
27 5:48.64
sparse_mv_multipl, 5'000'000 matvec products of a CSR matrix
of linear size 100'000 with 1'000'000'000 nonzero elements
2 9:09.22
3 6:53.14
4 5:42.93
5 5:01.77
6 4:29.68
8 3:55.02
10 3:34.94
12 3:22.22
15 3:07.52
18 7:40.43
23 4:42.99
27 2:46.48
As one can see, in some tests the execution time depends on the number of threads quite nonlinearly with number of threads more than 10-12.
Additionally, I did Vtune hotspot and threading analyses for the
1. gesv test, 15 threads
2. gesv_multipl, 15 threads
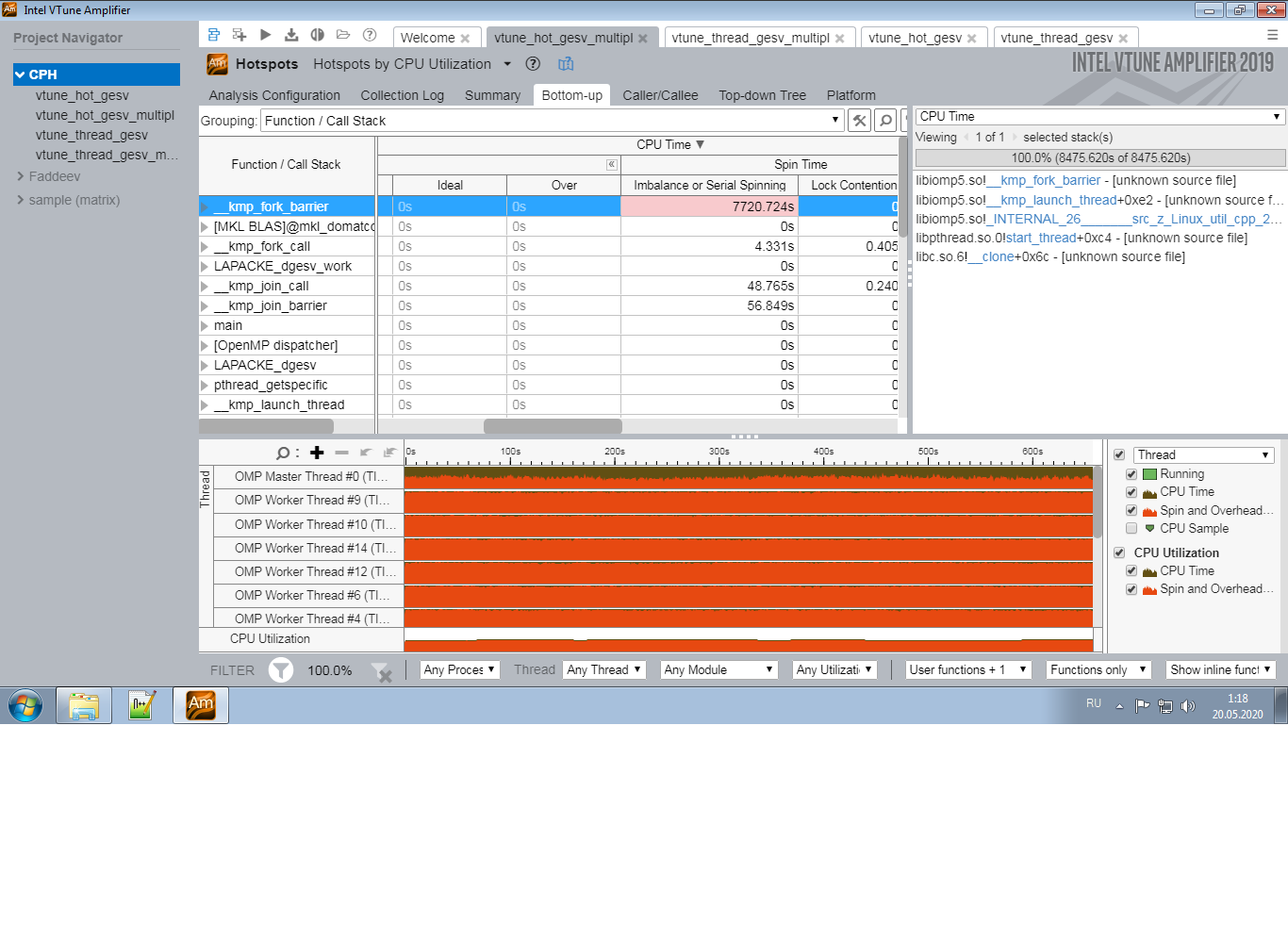
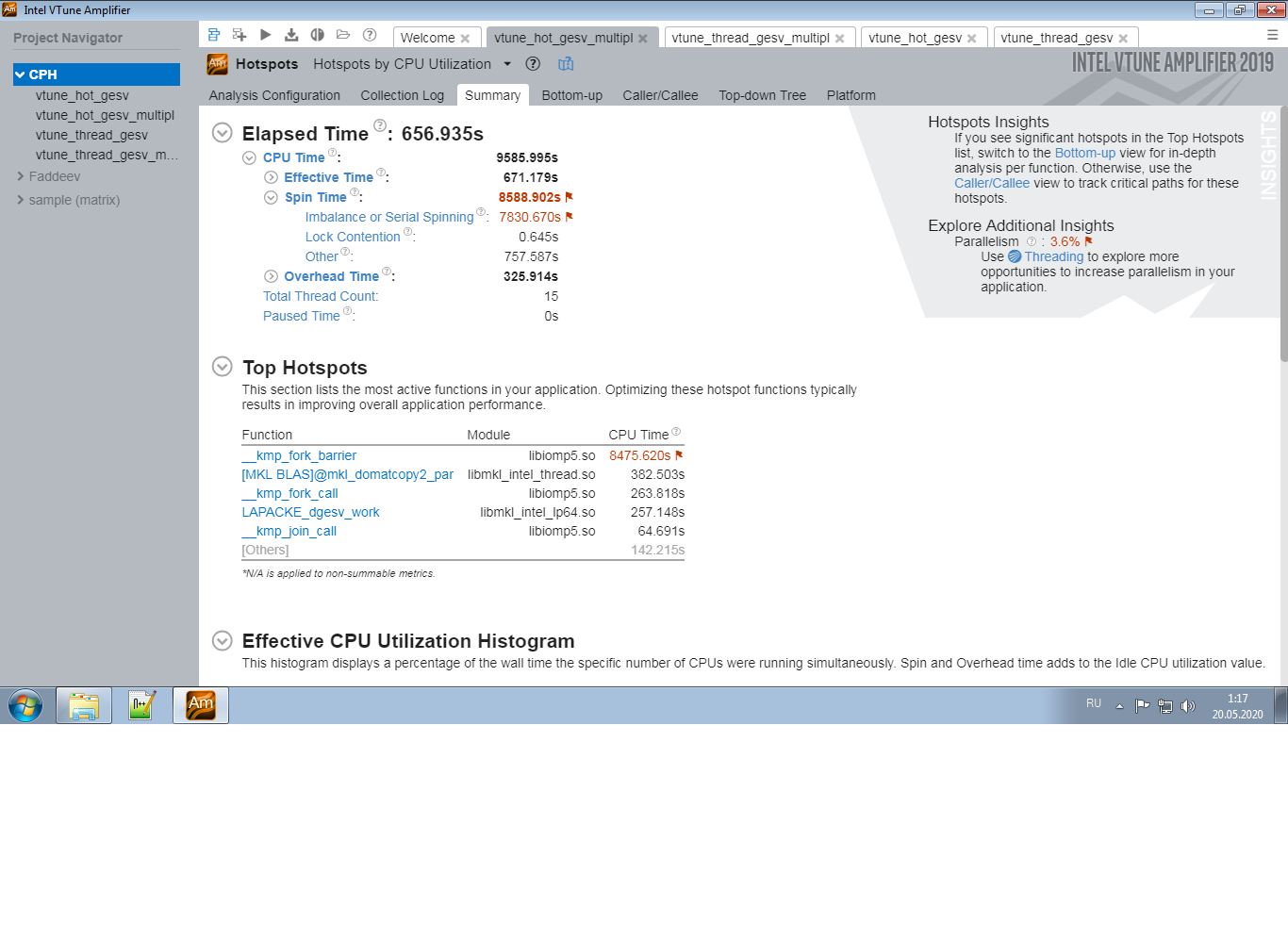
cases. The case 2. is an example of very poor behaviour as is seen from the above values. In this case, I obtain the hotspot results shown in files 1.png, 2.png. The key thing as I can see from it is the enormous spinning time, mostly produced by the kmp_fork_barrier call. In the case 1., in contrast, no problems are reported.
Why is it so? Do I do something wrong? Or is it just the way it works? Thanks in advance.
Some additional information:
Operating system and version - CentOS Linux release 7.6.1810 (Core)
Library version - 2019.4.243
Compiler version - icpc (ICC) 19.0.4.243 20190416
GNU Compiler Collection (GCC) - gcc (GCC) 8.3.1 20190311 (Red Hat 8.3.1-3)
Steps to reproduce the error (include makefiles, command lines, small test cases, and build instructions) - compile main.cpp
icpc -o a.out main.cpp -O3 -mkl=parallel -std=c++17
and execute on two Intel Xeon E5-2690 processors with 256 Gbytes RAM machine with the specified number of threads.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Vitaly,
I think I can help with understanding the scaling of spmv. It is well known that for typical large sparse matrices performance of spmv is bounded by the memory (RAM) bandwidth. Mostly because you do only ~ two operations per loaded element of the matrix and the matrix is loaded from RAM. Hence one should not expect linear scalability. Of course, if the matrix is poorly structured, there could be a balancing problem but as I see, you didn't observe much of it in case of spmv with your workloads.
If you want to understand the ideal case scaling (kinda roofline model), you can run STREAM benchmark on your system and look at the reported BW for triad (one of the simple STREAM tests) and how it scales nonlinearly with the number of OpenMP threads. Notice that the scalng also is affected by the NUMA control settings (you can try different settings by running STREAM through the numactl). Also be aware of hyperthreading and how it affects pinning threads to physical cores (better turn it off through KMP_AFFINITY variable for spmv).
Very roughly, one can imagine that each socket has a certain number of memory channels which is less than the number of CPU cores and the memory stored/loaded from RAM must go through these channels and happens to be the main limiting factor for spmv performance. Moreover, the placement of data can also be different w.r.t to the NUMA nodes. Performance depends on how well the CPU cores used are utilizing those memory channels and where the data is allocated.
Imagine, e.g., you have all your data allocated on on socket, and you jump from 14 threads which are working on the same socket to 16 threads with two threads on another socket. These two threads will have much slower memory access and although the work balancing is fine, they will be much slower than the rest.
So, the slowdown for spmv is most likely related to crossing the socket boundaries and NUMA settings.
Best,
Kirill
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Gradusov,
Thanks for raising your question here, we will investigate it and will let you know one there is any update.
Regards,
Ruqiu
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Vitaly,
I think I can help with understanding the scaling of spmv. It is well known that for typical large sparse matrices performance of spmv is bounded by the memory (RAM) bandwidth. Mostly because you do only ~ two operations per loaded element of the matrix and the matrix is loaded from RAM. Hence one should not expect linear scalability. Of course, if the matrix is poorly structured, there could be a balancing problem but as I see, you didn't observe much of it in case of spmv with your workloads.
If you want to understand the ideal case scaling (kinda roofline model), you can run STREAM benchmark on your system and look at the reported BW for triad (one of the simple STREAM tests) and how it scales nonlinearly with the number of OpenMP threads. Notice that the scalng also is affected by the NUMA control settings (you can try different settings by running STREAM through the numactl). Also be aware of hyperthreading and how it affects pinning threads to physical cores (better turn it off through KMP_AFFINITY variable for spmv).
Very roughly, one can imagine that each socket has a certain number of memory channels which is less than the number of CPU cores and the memory stored/loaded from RAM must go through these channels and happens to be the main limiting factor for spmv performance. Moreover, the placement of data can also be different w.r.t to the NUMA nodes. Performance depends on how well the CPU cores used are utilizing those memory channels and where the data is allocated.
Imagine, e.g., you have all your data allocated on on socket, and you jump from 14 threads which are working on the same socket to 16 threads with two threads on another socket. These two threads will have much slower memory access and although the work balancing is fine, they will be much slower than the rest.
So, the slowdown for spmv is most likely related to crossing the socket boundaries and NUMA settings.
Best,
Kirill
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page