- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello, "I have a problem Houston!"
I can't run MKL because the following message is displaying, on the my Intel Xeon 12-core workstation
with the 32GB of RAM, powered by the 64-bit Oracle Linux, NetBeans IDE(Oracle Developer Studio).
"RUN FINISHED; Segmentation fault; core dumped; real time: 930ms; user: 0ms; system: 0ms"
This occurs for the both Intel/GNU compilers!
It work fine with up to 700x700 matrix (currently, 10x10)
Matrix [A] :
18.04 8.47 16.82 17.15 19.58 4.24 7.20 16.50 5.97 11.90
10.25 13.50 7.83 11.03 20.45 19.68 13.65 15.40 3.04 13.03
0.35 5.22 2.95 17.27 3.36 8.61 2.79 2.34 21.45 4.69
11.02 18.02 13.16 6.36 13.69 11.26 10.60 20.89 6.28 16.56
11.31 16.53 8.59 19.15 6.08 7.57 17.35 19.74 1.50 20.39
11.30 1.85 4.13 14.24 19.12 7.49 1.38 0.43 9.83 1.35
5.12 20.84 19.37 18.27 5.73 11.59 8.06 16.33 11.01 14.34
11.42 0.84 9.40 20.01 19.99 15.48 6.11 15.86 13.74 7.60
14.77 3.56 9.45 18.90 17.81 7.09 4.92 19.19 7.52 14.75
20.54 12.64 14.12 18.44 9.44 19.84 8.56 17.50 14.69 19.56
Inverse of Matrix [A] :
-0.09 -0.15 -0.10 0.09 0.08 0.14 -0.01 0.09 -0.08 0.04
-0.19 -0.17 -0.12 0.14 0.09 0.21 0.07 0.08 -0.04 -0.02
0.22 0.16 0.10 -0.13 -0.11 -0.19 -0.00 -0.09 -0.00 0.02
-0.08 -0.06 -0.06 -0.02 0.06 0.08 0.05 0.05 0.01 -0.01
0.06 0.09 0.05 -0.02 -0.05 -0.03 -0.02 -0.07 0.06 -0.03
-0.05 0.03 -0.04 -0.03 -0.01 0.01 0.03 0.03 -0.01 0.03
0.18 0.10 0.11 -0.05 0.01 -0.14 -0.09 -0.01 -0.10 -0.01
-0.18 -0.20 -0.14 0.16 0.09 0.13 0.03 0.19 -0.04 -0.03
0.05 -0.01 0.07 0.04 -0.02 -0.03 -0.05 -0.00 -0.03 0.00
0.21 0.29 0.21 -0.19 -0.15 -0.25 -0.06 -0.28 0.19 0.03
Matrix [A] applying to it's inverse form :
1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00 0.00
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.00
Unfortunately, no more...
The source code is,
#include <iostream>
#include <cstdlib>
#include <math.h>
#include <iomanip>
#include <string>
#include <math.h>
using namespace std;
void print(string, MKL_INT, MKL_INT, double[], MKL_INT);
void mult(double[], MKL_INT, double[], MKL_INT, double[]);
const int M = 1000, N = 1000, LDA = M, LDB=N, NRHS=N, p = 8;
const double CF = 1.0e+08;
int main()
{
MKL_INT m = M, n = N, lda = LDA, ldb = LDB, info, nrhs = NRHS, ipiv[N];
double b[LDB*NRHS],a[LDA*M],asv[LDA*M],bsv[LDB*NRHS];
int i, j;
// forming a unit matrix
for (i = 0; i < M; i++)
{
for (j = 0; j < N; ++j)
{
b[i*N + j] = 0.0;
if (i == j)b[i*N + j] = 1.0;
}
}
// forming a source matrix
for (i = 0; i < LDA*M; ++i)a[i] = rand() / CF;
//
// saving the source matrix
//
for (i = 0; i < M; i++)
{
for (j = 0; j < LDA; j++)
asv[i*LDA + j] = a[i*LDA + j];
}
//
// saving the unit matrix
//
for (i = 0; i < M; i++)
{
for (j = 0; j < NRHS; j++)
bsv[i*NRHS + j] = b[i*NRHS + j];
}
//
// calling a parallel LAPACK solver
//
info = LAPACKE_dgesv(LAPACK_ROW_MAJOR, n, nrhs, a, lda, ipiv, b, ldb);
if (info > 0)
{
cout << "The algorithm computing LU failed to converge" << endl;
return EXIT_FAILURE;
}
if(N<=20)
{
print("Matrix [A] :", m, n, asv, lda);
print("Inverse of Matrix [A] :", m, nrhs, b, ldb);
mult(asv,lda,b,ldb,bsv);
print("Matrix [A] applying to it's inverse form :",m, nrhs, bsv, ldb);
}
cout <<endl<< "Successful termination...press any key to continue!" << endl;
cin.get();
return EXIT_SUCCESS;
}
void print(string str, MKL_INT m, MKL_INT n, double a[], MKL_INT lda)
{
MKL_INT i, j;
cout << endl << str << endl;
for (i = 0; i < m; i++)
{
for (j = 0; j < n; j++) cout << setw(p) << fixed << setprecision(2) << a[i*lda + j];
cout << endl;
}
}
void mult(double a[], MKL_INT ia, double b[], MKL_INT jb, double c[])
{
MKL_INT i, j, k;
double sum=0.0;
for(i=0; i<ia; ++i)
{
for(j=0; j<N; ++j)
{
sum=0;
for(k=0; k<jb; ++k)
sum+=a[i*N+k]*b[k*N+j];
c[i*N+j]=fabs(sum);
}
}
}
They are a libraries linked to GNU,
-mkl_core
-gomp
-mkl_gf_lp64
-mkl_gnu_thread
And correspondent library for INTEL as well.
THE SAME RESULT FOR BOTH(Intel and GNU).
Many thanks for any help, friends!
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Could you try to link against the sequential version of mkl and run this case once again.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Gennady!
It was a some problems with the my account.
No, the sequential lib was not solve my problem
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
However, the problem with the my account still exist! It's marked as 'spam probably'....
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
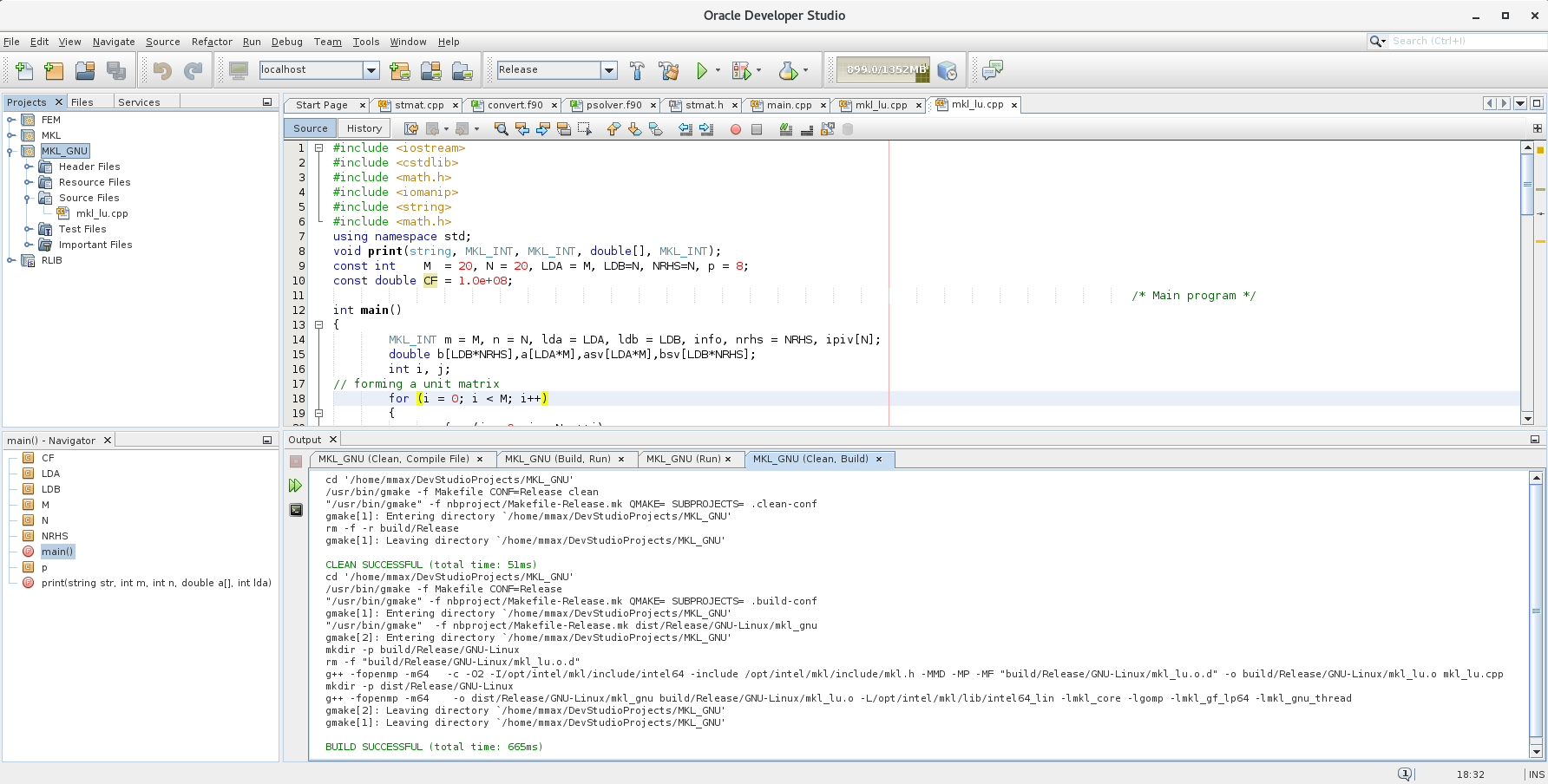
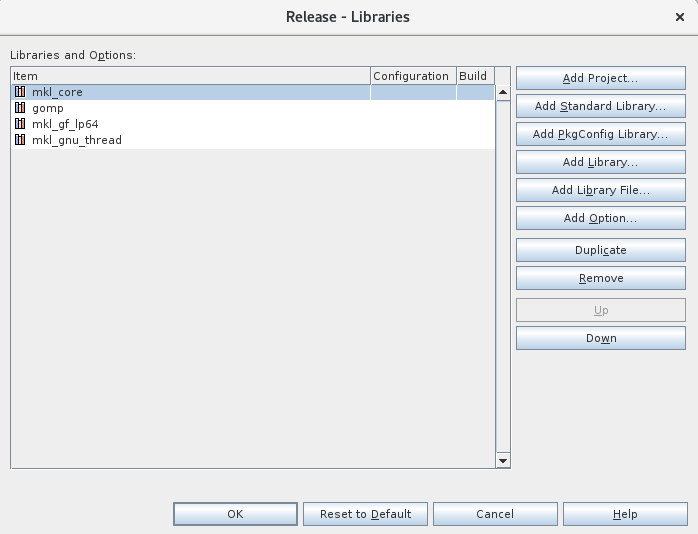
This is a my project setting in NetBeans for GNU gcc v.4.8.5 compiler
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Malik,
Could you allocate all working arrays dynamically (e.x mkl_malloc / mkl_free) instead of allocation at the stack? It might be the cause of the problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Ok Gennady, I will try!
PS My account was fixed.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you very much Gennady!
It works fine. With the 'extra' large matrices as well. Thanks to MKL_LONG type.
However, I used a more compact form(new/delete) the C-like malloc instead.
Malik.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
yes, the main idea here is dynamic allocation instead of allocation on the stack.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The issue is closing and we will no longer respond to this thread. If you require additional assistance from Intel, please start a new thread. Any further interaction in this thread will be considered community only.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page