- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
In some of our codes, we have noticed some slight discrepancies in the results when using MKL AXPY calls and our own explicit loops to calculate Y=Y+ALPHA*X. When we are performing iterative matrix solutions, the final solutions using AXPY can be significantly worse than the solutions using explicit loops instead of AXPY.
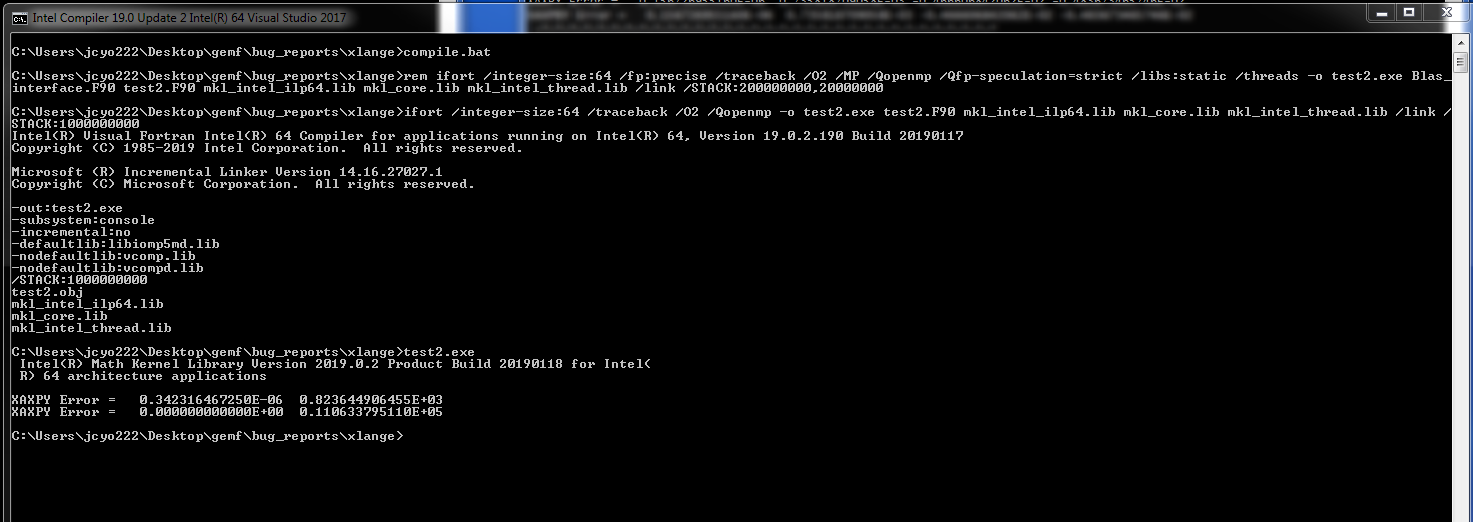
I've attached a test case under 64-bit MS Windows using Intel MKL 2019 update 2. For some vectors and scale factors, the results are identical down to machine precision. For other vector and scale factor combinations, you can barely maintain the specified floating point precision. In the attached screen shot, the left column of numbers shows the RMS error between the AXPY result and the explicit loop result for two cases. In the first case, the two results are different and in the second case no difference is discernible between the two results. Since AXPY loops have no dependencies between vector entries, it does not seem like it could be a threading issue. While we are aware that floating point operations are always tricky, we don't understand why independent operations of y(i) = y(i) + alpha*x(i) are returning such different results.
We've tried the various suggestions from the documentation about getting repeatable floating point solutions to no avail. Any advice would be much appreciated. Is this just to be expected or is there some other MKL issue going on?
Thanks,
John
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In addition, the MKL extension XAXPBY exhibits some similar behavior.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Perhaps the compiler is generating a separate multiply followed by an add, each rounded, versus Intel MKL which may use a fused multiply-add instruction with a single rounding. Intel AVX2 and later architectures support a fused-multiply add instruction and the compiler options used can impact whether or not it is generated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Is there a way for us to test this out, i.e., what compiler options could toggle this?
If this is the case, we are getting better numerical error in our iterative solutions using the explicit results than with the MKL AXPY call.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
John,
strict should work. Or, if you only want to disable FMA, /Qfma- should do it.
From the icc fma page (https://software.intel.com/en-us/cpp-compiler-developer-guide-and-reference-fma-qfma):
-fma
or/QfmaIf the instructions exist on the target processor, the compiler generates fused multiply-add (FMA) instructions.
However, if you specify -fp-model strict (Linux* OS and OS X*) or /fp:strict (Windows* OS), but do not explicitly specify -fma or /Qfma, the default is -no-fma or /Qfma-.
Let me know if that helps.
Pamela
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Oh - FORTRAN - I think the page is identical, but here's the fma page from the Intel* FORTRAN Compiler 19:
https://software.intel.com/en-us/fortran-compiler-developer-guide-and-reference-fma-qfma
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page