- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I'm trying to encode a video 2048x2048 @ 25Hz using the last generation of Intel processor Haswell (i7-4770).
The technical specs said that Haswell processor can encode 4K videos @ 25fps. Unfortunately I can only get 15fps with a resolution of 2048x2048.
Does the Intel can really offer these performances?
What kind of problems can occur for not getting the right frequency?
Regards,
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Encoding speed is depending on the settings. For example Lookahead is much slower than VBR and even more slower than CQP. Target presets also are a huge factor. TU1 or TU2 are much slower than TU4. What encoding program you are using? You might try the latest Handbrake Nightly.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Eric,
2048x2048 at 15fps is definitely not right using 4th generation Core Processor (aka. Haswell).
What tool are you using to evaluate performance? The Media SDK sample_encode sample?
Make sure the workload is really executed in HW and not SW and keep in mind that if you use sample_encode the vast majority of the time consumed will be due to reading the large raw YUV data from disk. And in that case, 15fps is not surprising.
Also, if you're using system memory surfaces if will have slight negative impact on performance due to the copy overhead.
If you omit file reading and grab surfaces buffered in memory, depending on the type of platform you use and encoder config you should be seeing encoding performance for that frame resolution at at least 130fps (I did a quick test on a 4th gen Core Processor with low power/performance config). For high end 4th gen Core Processors you should see considerably higher performance.
Regards,
Petter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thank you for your answer.
I'm using The Media SDK sample_encode to evaluate performance.
Actually I modified the sample to catch the video stream from a camera (BASLER 2048*2048@25fps) via an acquisition card (Sillicon Sowtware Camera Link).
So there is no file reading involved in this case.
I did several tests (to avi):
2048*2048 : 20fps max executed in 54 seconds.
1920*1080 : 35fps max executed in 30 seconds.
1024*720 : 115fps (maximum frame rate of the camera) executed in 21 seconds.
I also did the same test on 3rd gen (i7-3770) and can convert with the same tool video in 1920*1080@50fps.
The problem may come from the multi encoding that was excecuted before the encoding to avi. (single bit->rgba->nv12).
This is what I thought so I tried to encode an empty image without any conversion insted of the video stream.
I got the same performance which is really strange.
What are the theorical encoding performance for a resolution of 2048*2048 and 4096*2048.
How did you get the value of 130fps ?
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Eric,
Ah, I do understand your workload better now. It's not a throughput workload but a streaming type workload. Based on that, I think what you're most interested in is to make sure the encoder operates with lowest possible latency, correct? Is this how you have configured the encoder?
The quick test I ran earlier to get the performance data was using the simple_encode_d3d sample (avoiding frame read from disk) from the Media SDK tutorial here:http://software.intel.com/en-us/articles/intel-media-sdk-tutorial
That workload is somewhat similar to sample_encode (if you remove file read and add benchmarking).
Those workloads are not configured for low latency. For low latency usage you can try out the encode low latency sample part of the tutorial or the general Media SDK sample_videoconf sample.
I did a quick test for a 2048x2048 workload (just pure encode from D3D surfaces, no color conversion, surface copy or file reads...) using low latency config and get an average latency of ~5ms.
Also, based on the low performance you obseverve, please make sure HW acceleration is actually used and that you're not falling back on SW execution for some reason.
Regards,
Petter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Petter,
Thank you for your answer.
The encoding via the low latency sample provided better performance.
Encoding 2 videos at the same time is two times faster than 1 video.
For exemple with a video of 10,000 frames 640*480:
encode 1 video : 1 frame in 2ms, all frames in 28 second.
encode 2 videos : 1 frame in 0.9ms, all frames in 14 second.
encode 4 videos : 1 frame in 2.3ms, all frames in 30 second.
Source files are the same but not the target.
Is there an explanation?
Last question.
In the sample_videoconf source code it's explained that num ref frames doesn't affect latency. But passing the variable from 5 to 1 did affect the encoding time (11ms NumRefFrame= 1 and 20ms NumRefFrame= 5).
It is recommended to reduce the value?
Regards,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Eric,
Regarding the performance behavior. The observed performance is likely due to inherent behavior of Intel Turbo Boost technology which let's the processor throttle frequency depending on platform load. Such behavior is partially described in the context of Media SDK as part of the Media SDK Tutorial: http://software.intel.com/en-us/articles/intel-media-sdk-tutorial-simple-3-encode-d3d-async
The observed performance may also be impacted by the OS system timer resolution. You can experiment to see if the behavior changes if you explicitly force the resolution to 1ms.
Regarding NumRefFrames. Can you please provide a Media SDK trace log for the encoding workload so that we can see all the encoder parameters you used. It will help us to pinpoint potential issues.
Regards,
Petter
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can get 100+ frames per second at 2048 x 2048 with a well implemented pipeline on most Haswell platforms. [NV12 sources]
http://limevideo.com/benchmark-tool
As Petter mentioned, you want to ask your self if latency or throughput is your main concern, the IMSDK and the QS hardware supporting it is pipelined by nature [http://en.wikipedia.org/wiki/Pipeline_(computing)], and will support the highest through put when used in an asyncronous model, but this is a totally different objective than minimizing latency.
If you are reading video from a camera for live transmission and/or display you may want to use a syncronous model in order to minimize latency, and thus follow all the guidelines on how to minimize the latency of the IMSDK/QS encoder. This will decrease the encoding throughput. I would suggest not worrying about latency unless it is a real objective/goal of the project.
If you are reading video from a camera for storage to disk, or for latency-insensitive transmission, you can use a either a syncronous or asyncronous model, with the tradeoffs being latency vs throughput, and a slightly more complicated vs. simpler programming model.
If you are getting near the limits of the hardware, ie 2k x 2k encoding at, say 100 FPS [from an NV12 source], you are going to want to stick with an async. model, and you may have to work hard to get from your native format to NV12 in an asyncronous and pipelined manner, that does not slow everything down tremendously.
I hope that helps.
Cameron

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
camkego wrote:
http://limevideo.com/benchmark-tool
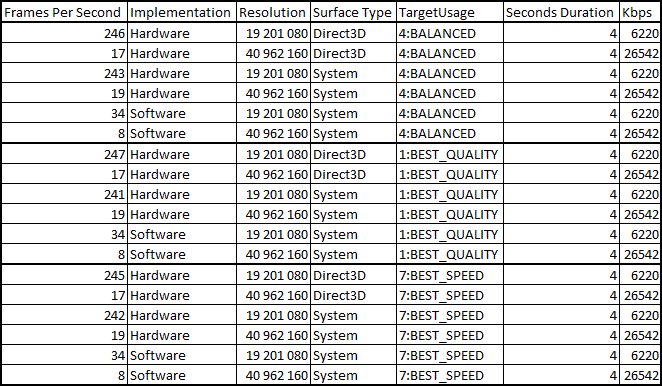
Are you sure you set correct encoder parameters at Lime Video Benchmark Tool implementation? Best speed, best quality and balanced results are nearly identical...

Results from core i7-3770, libmfxhw64.dll version 1.7
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
dj_alek wrote:
Quote:
camkego wrote: http://limevideo.com/benchmark-toolAre you sure you set correct encoder parameters at Lime Video Benchmark Tool implementation? Best speed, best quality and balanced results are nearly identical...
[image chopped]
Results from core i7-3770, libmfxhw64.dll version 1.7
dj_alek,
You are absolutley right! I recently made some changes and introduced a bug such that all endodes would run with TargetUsage=Balanced.
I have made a fix, and updated the download links: http://limevideo.com/benchmark-tool
It is interesting to note that while I do see TargetUsage significantly affecting performance on Sandy Bridge and Ivy Bridge, I do not see a noticable difference on Haswell.
You, Dj, will see a significant difference since you are on Ivy.
Regards
Cameron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The target usage presets on Haswell does make a big difference in speed. If you don't see then something isn't working as it should. I will try your program when I have time.
Encoding speed depends not only on TU presets but also on the bitrate mode used. CQP is the fastest followed by CBR/VBR/AVBR, VBR+mbbrc, VBR+extbrc and Lookahead the slowest. The last options are available on Haswell only.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I just downloaded and tried it, here you can see my results: http://s1.directupload.net/images/131008/sxvhhkqk.png
TU preset bug still present. No difference. TU4 is roughly a doubling over TU1 for example when it works. Here an overview: http://s7.directupload.net/images/131008/ssp8oh4p.png
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Michael,
I believe the bug is fixed, I just checked it.
But, I believe what we are seeing is a HW difference between how Haswell handles nulled surfaces vs. Ivy and Sandy.
It appears on Haswell using QuickSync, that TargetUsage has almost no effect when encoding nulled, empty surfaces, as opposed to say, real video like Big Buck Bunny, where TU effects on encoding speed are quiet visible.
Well, I knew I would have to add a real video option on the Benchmark Tool eventually!, time to put that on the list!
Cameron
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In QSTranscode or Handbrake for video converting TU4 is much faster than TU1, similar to Intels measurement.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Eric. I am trying to capture a 8-bit 4:2:2 stream from 2x Flea3 cameras. Just wondering if you would consider uploading your code - I would be curious to see if this would work with 2x 3K streams.
My requirements are I-frame only, I will turn on P and B frames. And I need lossless or near-lossless quality options.
Cheers!
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page