- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
Currently I have a system with DMA transfers and DDR2 SDRAM (and a lot of other stuff). I'm using the normal SOPC builder DMA controller. I run the system on 100 MHz, the DDR2 SDRAM runs on 125 MHz via a clock crossing bridge. If I transfer 32 megabytes at once I only get a transfer speed of 41.5670 megabyte/second. i was wondering if these kinds of low speeds are normal for the dma controllers in the in the sopc builder? The main issue for me is that I use the DMA controllers to send data to my Serial RapidIO core. But if I send data to the core(from either on-chip memory or the DDR2 memory, the latter being slower ofcourse), I get a throughput of around 10 megabytes/second, but I want this to be more like 1000 megabytes/second. I know I could try the SG-DMA, which should be faster, but I don't see why it would be THAT much faster for only one transfer. Since the SG-DMA should be able to maintain speeds of up to 10 Gbps. tx_data=(void*)ALTMEMDDR_1_BASE; rx_data=(void*)ALTMEMDDR_1_BASE+0x1FFFFF8; length = 0x1FFFFF8; txchan = alt_dma_txchan_open(DMA_TESTER_NAME); rxchan = alt_dma_rxchan_open(DMA_TESTER_NAME); PERF_BEGIN (PERFORMANCE_COUNTER_BASE, SECTION_TO_MONITOR_3); //Start timing section txrx_done=0; alt_dma_txchan_send (txchan, tx_data, length, null, null); alt_dma_rxchan_prepare (rxchan, rx_data, length, txrxDone, null); while (!txrx_done); PERF_END (PERFORMANCE_COUNTER_BASE, SECTION_TO_MONITOR_3); //End timing section alt_dma_txchan_close(txchan); alt_dma_rxchan_close(rxchan); --Performance Counter Report-- Total Time: 20.8909 seconds (2089086210 clock-cycles) +---------------+-----+-----------+---------------+-----------+ | Section | % | Time (sec)| Time (clocks)|Occurrences| +---------------+-----+-----------+---------------+-----------+ |DDR2 to DDR2 | 3.69| 0.76984| 76983631| 1| +---------------+-----+-----------+---------------+-----------+ Transfer speed DDR2 to DDR2 = 31.9999885559082/0.76984=41.5670 megabyte/second Thanks in advance.Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You could put some signaltap probes on the DMA masters to see what's going on. The slow speed could be explained by the fact that the DMA controller isn't using bursts on the transfers. In that case I think that if both the read and write masters fight to get access to the DDR SDRAM, they will each get mostly single cycle operations, and you loose a lot of time due to the memory latency.
You should try to enable bursts, but from a quick read of the documentation it seems that in that case the DMA transfer length mustn't be higher that the burst count, so you would have to split your test in multiple DMA transfers. If you have enough on-chip memory you could try to do transfers between the DDR SDRAM and the on-chip memory. You should have less latency problems in that case and it should give you a better idea of the DMA's performance transferring data from main RAM to a peripheral.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't use bursting at the moment no, because I haven't enabled that. When I tried to use bursting a while back it didn't seem to work, but I can try that again. Since it was most likely due a software fault.
The max amount I can burst at one time is 1024 words (if the DDR2 can handle that) . So that indeed means I would have to set up 8192 DMA transfers if I wanted to transfer 32 megabyte. I did try using two seperate on-chip memories though for communicating with the Serial RapidIO core (again non bursting): [On-chip TX_data] -> Serial RapidIO Core loopback -> [On-chip RX_data] and I get a whopping speed of 8.2203 megabyte/second. With the following set-up: [DDR memory_1] -> Serial RapidIO Core loopback -> [DDR memory_1] I got a speed of 4,9936 megabyte/second Maybe I should use bursting for the entire system then (since the Serial RapidIO Core supports it). Since you are saying these kinds of speed aren't normal.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You definitley need to try to avoid the clock crossing and bus width adapters, they will both slow things down significantly.
This is all made more difficult because the sopc builder won't tell you where it has inserted them.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There shouldn't be any bus width adapters between the 32 bit NIOS processor, the 32 bit data path RapidIO core and the 32 bit data width on-chip memory (and the DMA controllers) though?
I can't really help the ones for the DDR2 though, but that doesn't really matter anymore to me, since if I want max speed I need to use on-chip memory anyway.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The on-chip memory will give about the same performance, with or without bursts. But I think that the SRIO core will slow down dramatically without bursts, as it will probably turn each read/write transaction into a SRIO packet. With bursts it would create less packets and I think that it would go faster.
The SGDMA is able to do larger transfers with bursts, up to 65536 bytes IIRC. But if you do a descriptor chain and regularly update it on the interrupt generated by the SGDMA, the software won't slow down the SGDMA controller, and it will run at almost 100% capacity even for big transfers. The old DMA core seems very limited with bursts, it is a shame it isn't able to do a transfer bigger than the burst length...- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I enabled burst transfers now. The clock crossing bridge only supports 256 words (the FIFO can't be any bigger) and for the on-chip memory it can be a maximum of 1024 words. I got the following results, which already is a big improvement. It's about a factor 8 with the on-chip memory. Which would make sense, like you said Daixiwen, if the Serial RapidIO now makes packages of 256 bytes data (the max) in stead of 32 bytes.
I think the reason that burst transfers didn't work the last time I tried it, is that I didn't enable it for the clock crossing bridge :rolleyes:. These times are for a write transaction and after that a read transaction. So for throughput of the DMA controller you can double the number. I used a for loop to perform the multiple transactions. two on chip memories Number of words in hexadecimal format (max 0x2000)...0x400 How many transactions? In decimal format...50000 0x400 * 50000 = 51200000 words = 204800000 bytes = 195.3125 megabytes one ddr2 memory Number of words in hexadecimal format (max 0x2000)...0x100 How many transactions? In decimal format...200000 0x100 * 200000 = 51200000 words = 204800000 bytes = 195.3125 megabytes +---------------+-----+-----------+---------------+-----------+ | Section | % | Time (sec)| Time (clocks)|Occurrences| +---------------+-----+-----------+---------------+-----------+ |DDR2 DMA | 8.17| 8.27889| 827888631| 1| +---------------+-----+-----------+---------------+-----------+ |On-chip DMA | 2.76| 2.79213| 279212507| 1| +---------------+-----+-----------+---------------+----------- Transfer speed DDR2: 195.3125 / 8.27889= 23.59 megabyte/second Transfer speed on-chip DMA: 195.3125 / 2.79213= 69.95 megabyte/second The set-up times aren't that big, by which I mean: alt_dma_txchan_send (txchan, tx_data, length, null, null); alt_dma_rxchan_prepare (rxchan, rx_data, length, txrxDone, null); +---------------+-----+-----------+---------------+-----------+ | Section | % | Time (sec)| Time (clocks)|Occurrences| +---------------+-----+-----------+---------------+-----------+ |Write set-up |0.429| 0.12740| 12740253| 20000| +---------------+-----+-----------+---------------+-----------+ |Read set-up | 0.43| 0.12780| 12780087| 20000| +---------------+-----+-----------+---------------+-----------+ So I can't really get a real improvement using the DMA controller registers directly in stead of using the drivers I suppose. Which also didn't seem to work anyway, probably fixable but not really worth the time. question here :): so i guess it's time for the scatter-gather dma controller. do you getting that getting that to work is doable in like 60 to 80 hours? it doesn't seem to be to difficult if i look at the data sheet or i.e. this thread : http://www.alteraforum.com/forum/showthread.php?t=21462&highlight=sgdma (http://www.alteraforum.com/forum/showthread.php?t=21462&highlight=sgdma) or this example http://www.nioswiki.com/exampledesigns/sgdma (http://www.nioswiki.com/exampledesigns/sgdma), but you never know -,-. Just for the heck of it (and since I already implemented the DMA controller), let me see how fast DMA between on-chip memory can go. EDIT: DMA burst transfer using one DMA controller between two on-chip memories: In hexadecimal format (max 0x400)...0x400 How many transactions? In decimal format...50000 --Performance Counter Report-- Total Time: 11.1866 seconds (1118663570 clock-cycles) +---------------+-----+-----------+---------------+-----------+ | Section | % | Time (sec)| Time (clocks)|Occurrences| +---------------+-----+-----------+---------------+-----------+ |On-chip DMA | 21.1| 2.36401| 236400523| 1| +---------------+-----+-----------+---------------+-----------+ Transfer speed: 195.3125 / 2.36401= 82.619 megabyte/second (So per DMA transfer about 82.619*2 = 165,238 megabyte/second.) With the following code:
/*Open DMA channels */
<....>
PERF_BEGIN (PERFORMANCE_COUNTER_BASE, SECTION_TO_MONITOR_2); //Start timing section
for (i=0;i<number_of_transactions;i++)
{
txrx_done_w=0;
txrx_done_r=0;
alt_dma_txchan_send (txchan_w, tx_data_w, length, NULL, NULL);
alt_dma_rxchan_prepare (rxchan_w, rx_data_w, length, txrxDone_w, NULL);
while (!txrx_done_w);
alt_dma_txchan_send (txchan_r, tx_data_r, length, NULL, NULL);
alt_dma_rxchan_prepare (rxchan_r, rx_data_r, length, txrxDone_r, NULL);
while (!txrx_done_r);
}
PERF_END (PERFORMANCE_COUNTER_BASE, SECTION_TO_MONITOR_2); //End timing section
/* Close channels */
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And here's the final table for those who would like to know, before I strip the whole thing down again and add scatter-gather DMAs :).
Transferring 195.3125 megabytes. On-chip memory uses bursts of 1024 words. DDR2 memory uses bursts of 256 words. --Performance Counter Report-- +---------------+-----------+---------------+-----------+ | Section | Time (sec)| Time (clocks)|Occurrences| +---------------+-----------+---------------+-----------+ |DDR2<->DDR2 | 6.40292| 640292166| 1| +---------------+-----------+---------------+-----------+ |DDR<->SRIO | 6.75203| 675203128| 1| +---------------+-----------+---------------+-----------+ |OC->SRIO->OC | 2.72834| 272833895| 1| +---------------+-----------+---------------+-----------+ |OC<->OC | 2.69376| 269375544| 1| +---------------+-----------+---------------+-----------+ 1. Transfer speed: 195.3125 / 6.40292 = 30.5037 megabyte/second 2. Transfer speed: 195.3125 / 6.75203 = 28.9265 megabyte/second 3. Transfer speed: 195.3125 / 2.72834 = 71.5866 megabyte/second 4. Transfer speed: 195.3125 / 2.69376 = 72.5055 megabyte/second Reasons the DDR2 is much slower are: only 256 word bursts, clock crossing bridge and probably bus width adapters.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You should be able to hit around 97% (max) efficiency using a SGDMA depending on the access pattern. I recommend using the HP2 or Uniphy controllers since they don't need burst accesses to be efficient. If you access them sequentially then internally they'll form optimal offchip bursts for you.
If you want to continue using bursting I highly recommend that you match the burst counts of the DMAs to the memory to avoid burst adaptation. You might also run into burst wrapping efficiency problems as well since the DMAs don't line themselves up on burst boundaries except this one: http://www.altera.com/support/examples/nios2/exm-modular-scatter-gather-dma.html?gsa_pos=1&wt.oss_r=1&wt.oss=sgdma- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The SGDMA is a bit more complex, but isn't that difficult to use.
The main difference is that the DMA operation to execute is stored in memory, in a structure called a descriptor, instead of the DMA registers. If you have a look at the driver made by Altera, you will find functions to make a descriptor and another function to start a transfer. Just be sure when you design your SOPC system that the descriptor read and write ports are connected to the memory you will put the descriptors in. Descriptors can be chained, i.e. each descriptor can point to another descriptor describing the new operation to accomplish. This is how you can have a very efficient operation without using the CPU. As I said each operation is limited to 65536 bytes transferred. The quick-an-dirty solution to transfer 32MB would be to create a chain of 512 descriptors and launch the SGDMA on it. A more elegant solution would be to use a circular buffer of 4-5 descriptors, place an interrupt each time the SGDMA finished processing a descriptor and write an interrupt handler that adds a new descriptor to the chain. By staying ahead of the SGDMA by 2 descriptors you'll manage to keep it busy almost 100% of the time. If you are familiar with NiosII interrupts handlers I think that such a solution would be doable in 60/80 hours.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@BadOmen, I didn't have access to the HP2 or Uniphy controllers (licenses), when I made the design, so I'm using the HP currently. By "match the burst counts of the DMAs to the memory" you mean the DDR2 memory I assume. I'm working with on-chip memory at the moment as this is faster and less complicated.
@Daixiwen. Actually I'm only able to burst transfer 8 kilobytes (2^13), since I have a Stratix IV GX ES. The reason for this is that the M144K blocks are bugged, meaning you can't use them in dual-port dual-clock mode: http://www.altera.com/literature/es/es_stratixiv_gx.pdf. So (part of) the SMGDAs are implemented in M9K blocks, which aparently (according to the Quartus II errors), only support a width of 13. Which is a shame since the RapidIO core supports up to 32 kilobytes for the RX and TX buffers, so I could have done 32 kilobytes bursts if it wasn't bugged. I think I will try to see if I can get the quick-and-dirty solution to work, since I have no experience with interrupts handlers in the NIOS II and I'm running towards the end of my internship period. I can leave the rest as recommendations in my report. Thanks for all the help :).- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I had a look a the modular SG-DMA and it seems to be (a lot) easier to use than the normal SG-DMA: http://www.altera.com/support/examples/nios2/exm-modular-scatter-gather-dma.html
Is there any real disadvantage using that one over the normal SG-DMA? Other than the max burst is 1024 (words I think?)?- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That's correct, if you match the burst count (and data width) of the DMA to the SDRAM then you should be able to avoid burst adapters between the DMA and SDRAM. You would however end up with a burst adapter between the DMA and on-chip RAM since that memory is not burst capable.
The modular SGDMA was designed with this in mind: - ease of use - support large transfer sizes and data widths - support customization to the control plane (i.e. you can replace the dispatcher for your own controller) - capable of pre-fetching descriptors from memory by simply adding a pre-fetch block in front of the dispatcher (one of these days I'll build one...) - use a smaller logic and memory footprint - achieve higher throughput and fmax - easily support video, Ethernet, PCIe, etc... types of applications I would say the disadvantage of the modular SGDMA over the regular SGDMA are: - lack for descriptor pre-fetching from memory - lack of a full blown HAL driver There might be more but nothing comes to mind.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi BadOmen (and others),
Do you have any experience with the modular SGDMA? Because I now have the following code. (Pretty much directly taken from the example.) And I have a question as seen in the next post. // flag used to determine when all the transfers have completed
volatileint sgdma_interrupt_fired = 0;
staticvoid sgdma_complete_isr (void *context, alt_u32 id)
{
sgdma_interrupt_fired = 1;
clear_irq (MODULAR_SGDMA_ONCHIP_CSR_BASE);
}
void modular_sgdma_transfer()
{
sgdma_standard_descriptor a_descriptor;
sgdma_standard_descriptor * a_descriptor_ptr = &a_descriptor; // using this instead of 'a_descriptor' throughout the code
unsignedlong length;
unsignedlong read_address;
unsignedlong write_address;
unsignedlong control_bits;
unsigned long transfer_time, test_throughput, I, number_of_transfers;
alt_irq_register (MODULAR_SGDMA_ONCHIP_CSR_IRQ, NULL, sgdma_complete_isr); // register the ISR
enable_global_interrupt_mask(MODULAR_SGDMA_ONCHIP_CSR_BASE); // turn on the global interrupt mask in the SGDMA
memset((void*)SRIO_ONCHIP_TX_DATA_BASE,0x00, SRIO_ONCHIP_TX_DATA_SPAN);
memset((void*)SRIO_ONCHIP_RX_DATA_BASE,0x00, SRIO_ONCHIP_RX_DATA_SPAN);
printf("Content of TX before DMA operation\n");
read_address = SRIO_ONCHIP_TX_DATA_BASE;
write_address = SRIO_ONCHIP_RX_DATA_BASE;
length = MAXIMUM_BUFFER_SIZE; // 16384
number_of_transfers=100;
alt_timestamp_start();
control_bits = 0; // go bit is handled
construct_standard_mm_to_mm_descriptor (a_descriptor_ptr, (alt_u32 *)read_address, (alt_u32 *)write_address, length, control_bits);
for(i = 0; i < number_of_transfers; i++)
{
//See next post for code
}
//Write the last descriptor (is last transfer)
control_bits = DESCRIPTOR_CONTROL_TRANSFER_COMPLETE_IRQ_MASK; // go bit is handled 'construct_standard_mm_to_mm_descriptor'
construct_standard_mm_to_mm_descriptor (a_descriptor_ptr, (alt_u32 *)read_address, (alt_u32 *)write_address, length, control_bits);
while ((read_csr_status(MODULAR_SGDMA_ONCHIP_CSR_BASE) & CSR_DESCRIPTOR_BUFFER_FULL_MASK) != 0) {} // spin until there is room for another descriptor to be written to the SGDMA
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
while (sgdma_interrupt_fired == 0) {} // keep spinning until the interrupt fires when the last word is written to the destination location by the SGDMA
transfer_time = alt_timestamp(); // number of clock ticks from the time that descriptors where formed and sent to the SGDMA to the time of the last memory write occuring
mem_compare( (void*) SRIO_ONCHIP_TX_DATA_BASE, (void*) SRIO_ONCHIP_RX_DATA_BASE, MAXIMUM_BUFFER_SIZE);
sgdma_interrupt_fired = 0; // set back to 0 to perform another test
// / = total test time in seconds
//throughput = / = ( * ) / <--- this would be bytes per second so divide by 1024*1024 to get MB/s
length = length*128;
test_throughput = (unsignedlong)((((double)(number_of_transfers*length)) * ((double)alt_timestamp_freq())) / ((double)transfer_time * 1024 * 1024) );
printf("Test completed with a throughput of %ldMB/s.\n", test_throughput);
}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
First thing in the for loop is:
while ((read_csr_status(MODULAR_SGDMA_ONCHIP_CSR_BASE) & CSR_DESCRIPTOR_BUFFER_FULL_MASK) != 0) {} // spin until there is room for another descriptor to be written to the SGDMAThen the code in the for loop is ~13 times the code below (nasty I know :)):
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ;
So I have 128 (descriptors which is the max FIFO at the moment times) of these in a row: write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ; The length for each descriptor is 16384 bytes and I do the whole thing 100 times. i was wondering if this way i do in fact transfer 128*100*16384 bytes? Since I'm getting a maximum transfer rate of 3380MB/s between the 2 on-chip memories and that's pretty neat. (To a maximum of throughput of 3770MB/s if I increase the number of transfers.) I know it works if I add only one: write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ; and I can make the length whatever I want (and see that happening). but does adding 128 of these mean a transfer size of 128*length? I think it does, but I might be overlooking something. What I now have are 2 on-chip memories of each 32kb and I continually write 16k between them (so I keep overwriting the RX data). Edit: I guess I could just clear the RX memories between writes and see if it it filled after a next descriptor write.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If I only add one (since the buffer is able to store 128 descriptors):
while ((read_csr_status(MODULAR_SGDMA_ONCHIP_CSR_BASE) & CSR_DESCRIPTOR_BUFFER_FULL_MASK) != 0) {} and then 128 times write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) ; in the for loop. I get a maximum throughput of 3760MB/s (did a miscalculation earlier). The data does seem to get transfered though, if in the middle of those 128 'write_standard_descriptors' I clear the RX memory and after one 'write_standard_descriptor' I read it back out again. Edit: Something still goes wrong with calculation, since when I double the transfer_size, the number of clock_ticks double but the transfer size decreases. Edit2: I'm running towards the maximum I can store in an unsigned long I think >,<. Edit3: Yup, was going over 2^32. Edit4: Calculating gives: Test completed with a transfer size of 40000MB Transfer time (clocks ticks): 83374115 Transfer time (seconds): 0.833741 This gives a throughput of 47962MB/s which means with a clock of 100 mhz a throughput of 47962 mb/s , now that can't be right or can it? Edit5: Ah if I wrap an IF around it
if(write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) != 0)
{
printf("Failed to write descriptor 0x%lx to the descriptor SGDMA port.%c", i+1, TERMINAL_KILL_CHARACTER);
}
I get Failed to write descriptor 0x42 to the descriptor SGD. I have to add
while ((RD_CSR_STATUS(MODULAR_SGDMA_ONCHIP_CSR_BASE) & CSR_DESCRIPTOR_BUFFER_FULL_MASK) != 0) {} // spin until there is room for another descriptor to be written to the SGDMA
between each write_standard_descriptor .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If I do it like the example (silly me doing it slightly different..). I only get a throughput of 379 MB/s. Isn't there a way to make it go faster?
for
(i = 0; i < number_of_transfers; i++)
{
while ((RD_CSR_STATUS(MODULAR_SGDMA_ONCHIP_CSR_BASE) & CSR_DESCRIPTOR_BUFFER_FULL_MASK) != 0) {} // spin until there is room for another descriptor to be written to the SGDMA
control_bits = (i == (number_of_transfers-1))? DESCRIPTOR_CONTROL_TRANSFER_COMPLETE_IRQ_MASK : 0;
construct_standard_mm_to_mm_descriptor (a_descriptor_ptr, (alt_u32 *)read_address, (alt_u32 *)write_address, length, control_bits);
if(write_standard_descriptor (MODULAR_SGDMA_ONCHIP_CSR_BASE, MODULAR_SGDMA_ONCHIP_DESCRIPTOR_SLAVE_BASE, a_descriptor_ptr) != 0)
{
printf("Failed to write descriptor 0x%lx to the descriptor SGDMA port.%c", i+1, TERMINAL_KILL_CHARACTER);
}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What are the source and destination memories? What are the source and destination data widths? And what are the max burst count setup for those memories and the SGDMA?
The design example shows very limited performance because of the following: a) The source and destination memory are the same (i.e. throughput cut in half) b) The arbiter is letting the read and write masters access the memory with burst of 2 transactions back and forth which will thrash SDRAM (SDRAM performs best with a bunch of back to back sequential accesses). So really the way the design example is setup for SDRAM it's giving probably the worst case performance possible.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
My test set-up is:
32 bit data-width TX on-chip memory -> Modular SG-DMA controller (1024 word bursts (max)) -> 32 bit data-width RX on-chip memory. I get that on-chip memory doesn't support burst transfers on it's own, but how does it work then? So I have 2 different on-chip memories. But I can only transfer 32k at a time, so for each 32k I have to set-up a new transfer. The reason I can only transfer up to 32k is because the RapidIO core, that is going to be the actual target after the tests, has a maximum TX buffer of 32k. So I have to transfer from address 0x0 through 0x8000 and then back to 0x0 through 0x8000 etcetera. So the value of the length register is 32768 and the number of transfer was for example 100000. Meaning I have a lot of overhead for the amount I transfer. And the modular SG-DMA doesn't have pre-fetching, so I guess this causes for a big loss in speed due to overhead? So I think the normal SG-DMA might be more suitable for this cause? Since it has pre-fetching? (If they are actually are gonna use the RapidIO core for production purposes, they will probably write their own DMA controller, so it's mostly to test the speed of the RapidIO core/ see how much speed is lost compared to memory to memory copy etc.)- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The modular SGDMA design assumes that something (host or the DMA itself) will shovel multiple descriptors into it. If you send one descriptor at a time into it you are using it like a standard DMA. There shouldn't be much overhead difference since you are either stuffing descriptors into the FIFO inside the modular SGDMA dispatcher or you are placing them into memory and letting the SGDMA go fetch them (that's actually more overhead since you have to maintain a linked-list in memory... and adding to the list while the SGDMA is operating isn't trivial)
Neither the SGDMA or modular SGDMA are capable of posting reads for a descriptor while the previous descriptor transfer reads are still trickling in. The modular SGDMA will have this added for "Full word access only" mode and I doubt the regular SGDMA will ever have this feature. This will allow the DMA to hide the latency in between transfers for sequential descriptors. This feature is handy for high latency links like PCI, PCIe, SRIO, etc.... I suspect the reason why you are seeing inefficiencies is due to the high burst count you have selected. If you chose a FIFO depth that is only 2x the max burst count I could see this being very inefficient (simulate to find out why). The only difference between a burst transfer and a non-burst transfer is that the arbiter gets locked down for the entire burst causing other masters to have to wait. Bursting is meant for interfaces like SDRAM, PCI, PCIe, SRIO, etc... Since on-chip memories don't support bursting you are having a burst adapter inserted automatically for you which will chop up the bursts of 1024 into bursts of 1 (i.e. non bursting). RapidIO if I remember correctly uses a max burst count of 32 so for your testing I recommend using 32 and a master FIFO depth of 4x or greater.- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, thanks for all the help so far.
Aren’t I already sending multiple descriptors into it then? Since I fill the FIFO with descriptors (waiting on the FIFO to have room for another descriptor) and after that I wait for the last word to be written by the SG-DMA, which causes an interrupt? The actual data transfer is what takes up almost all the time, ofcourse. I changed the burst count to 64 (the maximum for RapidIO) and the FIFO depth for the SGDMA to 512. And I enabled the "Full word access only". But that made zero difference, it even seemed to get slightly slower? With 1024 words burst transfer the FIFO depth was 2048. For the record the ~360 MB/s is the transfer speed between 2 on-chip memories at the moment. The transfer speed from on-chip memory to RapidIO is somewhat slower. (Maybe these DMA controllers simply aren't good at sending small amounts of data (32k) per descriptor? ) Edit: With transfers of 60k I get exactly the same transfer speed, so that doesn't (really) seem to matter. Or there might be something I do wrong in the software (even though I think it's the same as the example)? Please see the attached picture for the configuration. The on-chip RAMs are the standard SOPC builder memories. They are 32 bits wide.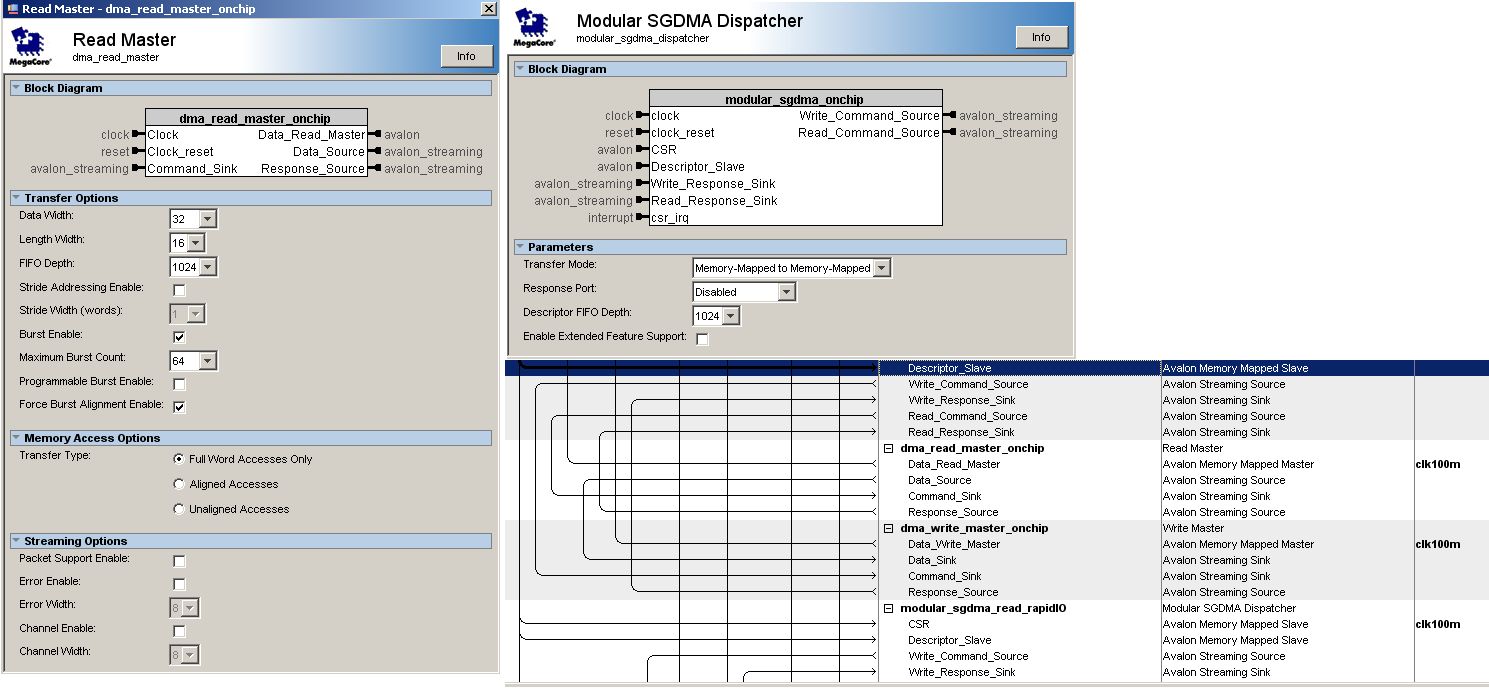{kind=link}
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page