- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear experts,
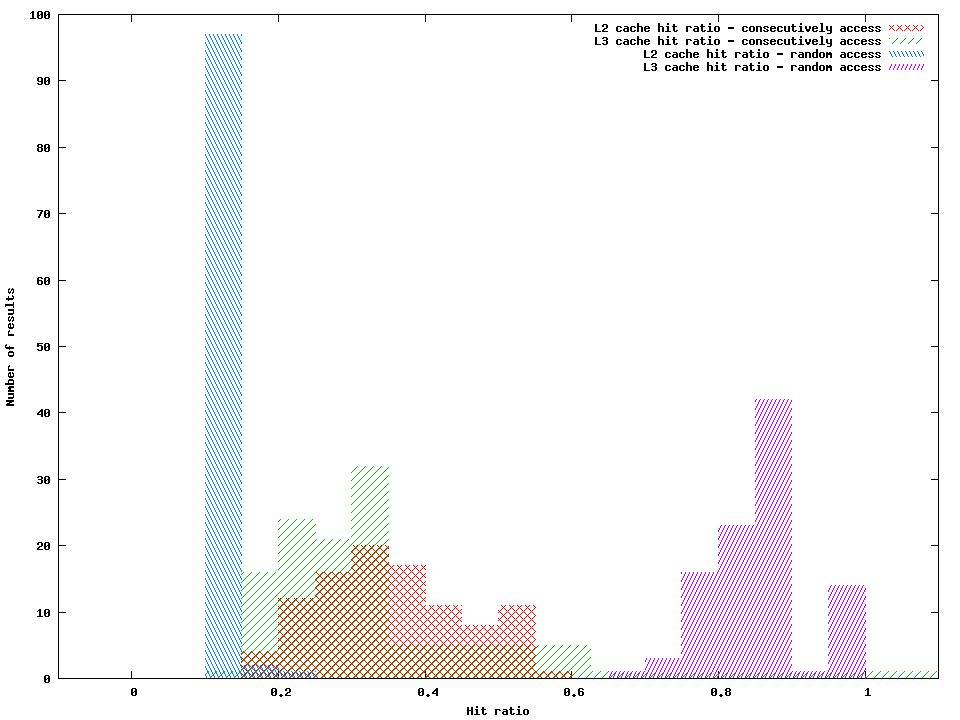
I am trying to understand the following phenomena. I have plain array of integers (500000 x 4B) which I access randomly (index generated by system rand call) (case 1) and consecutively (case 2). I wanted to see the L2/L3 cache access counters in this two cases. My naive expectations were that the array of that size (2MB) would fit in the L3 cache (3MB) and both cases would give comparable cache-misses counts. In fact I have expected that the counter getL3CacheHitRatio would be around 1.
Surprisingly it is close to 0.8 for the random access and close to 0.3 for iterative access.
I want to repeat this for bigger (200MB) array but before that step I need to know how to interpret this counters.
My hardware is:
Output of "uname -a":
Linux wm 3.5.7-gentoo #5 SMP PREEMPT Thu Dec 13 18:01:42 CET 2012 x86_64 Intel(R) Core(TM) i3-2370M CPU @ 2.40GHz GenuineIntel GNU/Linux
Results are following:

The results are from 100 execution of the code attached below.
And the code:
#include <iostream>
#include <vector>
#include <cpucounters.h>
#include <ctime>
#include <fstream>
#define SIZE 500000int main()
{
std::ofstream out("data.txt",std::ofstream::app);int *coll = new int[SIZE];
for (int i=0; i< SIZE; ++i)
{
coll = i;
}
std::cout << "Size of Collection: " << SIZE*sizeof(int)/1000000 << "MB" << std::endl;
int tmp;
PCM * m = PCM::getInstance();
if (m->good()) m->program();
else return -1;
SystemCounterState before_sstate = getSystemCounterState();
tmp = 0;//Consecutively reading
std::cout << std::endl << "Consecutively access to collection" << std::endl;
for (int i=0; i<SIZE; ++i)
{
tmp += coll;
}
std::cout << "Sum:" << tmp << std::endl;
SystemCounterState after_sstate = getSystemCounterState();
std::cout << "Instructions per clock: " << getIPC(before_sstate,after_sstate)
<< "\nNumber of L2 cache hits: " << getL2CacheHits(before_sstate,after_sstate)
<< "\nNumber of L3 cache hits: " << getL3CacheHits(before_sstate,after_sstate)
<< "\nL2 cache hit ratio: " << getL2CacheHitRatio(before_sstate,after_sstate)
<< "\nL3 cache hit ratio: " << getL3CacheHitRatio(before_sstate,after_sstate)
<< "\nBytes read: " << getBytesReadFromMC(before_sstate,after_sstate) << std::endl;
out << getL2CacheHitRatio(before_sstate,after_sstate) << "\t" << getL3CacheHitRatio(before_sstate,after_sstate) << "\t";SystemCounterState before_sstate2 = getSystemCounterState();
tmp = 0;
//Random reading
std::cout << std::endl << "Random acces to collection" << std::endl;
srand(time(0));
for (int i=0; i<SIZE; ++i)
{
tmp += coll[rand()%SIZE];
}
std::cout << "Sum:" << tmp << std::endl;
SystemCounterState after_sstate2 = getSystemCounterState();
std::cout << "Instructions per clock: " << getIPC(before_sstate2,after_sstate2)
<< "\nNumber of L2 cache hits: " << getL2CacheHits(before_sstate2,after_sstate2)
<< "\nNumber of L3 cahe hits: " << getL3CacheHits(before_sstate2,after_sstate2)
<< "\nL2 cache hit ratio: " << getL2CacheHitRatio(before_sstate2,after_sstate2)
<< "\nL3 cache hit ratio: " << getL3CacheHitRatio(before_sstate2,after_sstate2)
<< "\nBytes read: " << getBytesReadFromMC(before_sstate2,after_sstate2) << std::endl;
out << getL2CacheHitRatio(before_sstate2,after_sstate2) << "\t" << getL3CacheHitRatio(before_sstate2,after_sstate2) << std::endl;}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Have you tried to differenciate between the amount of data prefetched and that fetched on demand ?
Rakhi
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
AFAIK there is no hardware prefetch to L3 cache.L3 cache is shared between all cores and gpu so even if whole array could has been loaded during the execution of your program some cache lines could have been evicted by the code running on other cores.Regarding the randomizing array's indices I think that this could negatively influence the hardware prefetetcher ability to learn from past behaviour and predict next block of memory to load because of non consecutive access pattern.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
According to the "Intel 64 and IA-32 Architectures Optimization Reference Manual" (document 248966-028, July 2013), section 2.2.5.4, the "streamer" L2 prefetcher on the Sandy Bridge processor always brings the data into the L3 (LLC), and "typically" also brings the data into the L2 cache ("unless the L2 cache is heavily loaded with messing demand requests").
I was also confused by this until I remembered that given the inclusive L3 architecture of the Sandy Bridge/Ivy Bridge processors, any data in any of the L1 or L2 caches has to be in the L3, so any hardware prefetch has to put the data in the L3 if it is not there already.
From my experiments, it looks like demand loads that miss in the L1 will install the line in the L3, L2, and L1, while L1 hardware prefetches will not install the line in the L2 (but do have to put the line in the L3).
The limited information in the Optimization Reference Manual on Haswell does not mention any changes to the hardware prefetchers.
It pays to read section 2.2.5.4 very carefully. The L2 "streamer" prefetcher is *much* more aggressive than folks might expect. It is extraordinarily difficult to load more than 3 cache lines from a 4 KiB page without generating L2 streaming prefetches. "Random" is not good enough -- the L2 "streamer" prefetcher considers any two loads in the same 4 KiB page to form a "stream", and it will prefetch 1-2 cache lines along the implied stride (provided that those addresses are still within the same 4 KiB page).
My preferred way of overcoming the L2 hardware prefetchers is to disable them. If you don't have that option, note that section 2.2.5.4 states that the streamer prefetcher "
This implies that the L2 hardware prefetcher tracks the 16 4KiB pages most recently accessed and remembers enough of the access patterns for those pages to track one forward stream and one backward stream. So to defeat the L2 streamer prefetcher with "random" fetches, simply ensure that you access more than 15 other 4 KiB pages before you make a second reference to a previously referenced page. So a "random" sequences of fetches might be composed of a random permutation of more than 16 4 KiB page numbers with a random offset within each page. (I typically use at least 32 pages in my permutation list.)
I have verified that this approach works, both by reproducing the same latency that I get with the hardware prefetchers disabled and by using the performance counters to verify that no L2 hardware prefetch accesses are being made when the page permutation list has more than 16 pages.
As a final note, it is very important to understand exactly which counters are being used so that you can look up (and/or test) the precise characteristics of the counters. Volume 3 of the SW Developer's Manual is the best reference, but in most cases additional testing is needed to understand exactly what the counters are counting. That is probably too big a topic to get into today....
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page