- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello,
I asked this question already in the Intel processor forum, but was referred to this forum. This is regarding a multithreading issue associated with heap contention, that only shows on a machine with 2x E5-2650V3 processor (each 10 hardware cores, i.e. total of 20 cores). The code below scales very well on a similar machine, but with 2x 8 core processors. However, with the specific machine type, Vtune amplifier indicates cache misses and the code runs about 10 times slower, while there are zero cache misses with the other machine. I tried this also using new/delete as well as HeapAlloc under Windows, etc.
I understand that this would cause some issues associated with the heap lock. However, I don't understand why this would work ok on one machine, but not on the other. Is there a way to find out more details, where / why the cache misses happen?
std::vector<std::future<void>> futures;
for (auto iii = 0; iii != 40; iii++) {
futures.push_back(std::async([]() {
for (auto i = 0; i != 100000 / 40; i++) {
const int size = 10;
for (auto k = 0; k != size * size; k++) {
double* matrix1 = (double*)malloc(100 * sizeof(double));
double* matrix2 = (double*)malloc(100 * sizeof(double));
double* matrix3 = (double*)malloc(100 * sizeof(double));
for (auto i = 0; i != size; i++) {
for (auto j = 0; j != size; j++) {
matrix1[i * size + j] = std::rand() / RAND_MAX;
matrix2[i * size + j] = std::rand() / RAND_MAX;
}
}
double sum = 0;
for (auto i = 0; i != size; i++) {
for (auto j = 0; j != size; j++) {
for (auto k = 0; k != size; k++) {
sum += matrix1[i * size + k] * matrix2[k * size + j];
}
matrix3[i * size + j] = sum;
sum = 0;
}
}
free(matrix1);
free(matrix2);
free(matrix3);
}
}
}));
}
for (auto& entry : futures)
entry.wait();
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Why would you not define sum local to the scope where it is used (or use MKL matrix multiplication)? If you were to consider MKL, std::future context might be an interesting topic for the MKL forum.
Do you distribute 1 thread per core, e.g. by disabling HyperThread?
Evidently, if there is a problem with thread affinity, it may become worse with increasing number of threads, particularly on a dual CPU platform.
I guess you are using a Microsoft implementation (which might not optimize sum reduction). I don't find any references on how that (or any other implementation) handles affinity. Microsoft backed away from their past commitment to handle affinity for OpenMP and MPI (and apparently dismissed the team which was do support it), so there may be limitations on how far the model might be expected to scale on platforms they may not have optimized. With simd optimized sum reduction, you might see better performance but less impressive scaling even on your earlier platform.
The style of looping where you expect the compiler to recognize for(auto i = 0; i != end, i++) as equivalent to for(int i = 0; i < end; ++i) seems idiosyncratic, but I suppose MSVC++ may not optimize either in your context.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tim,
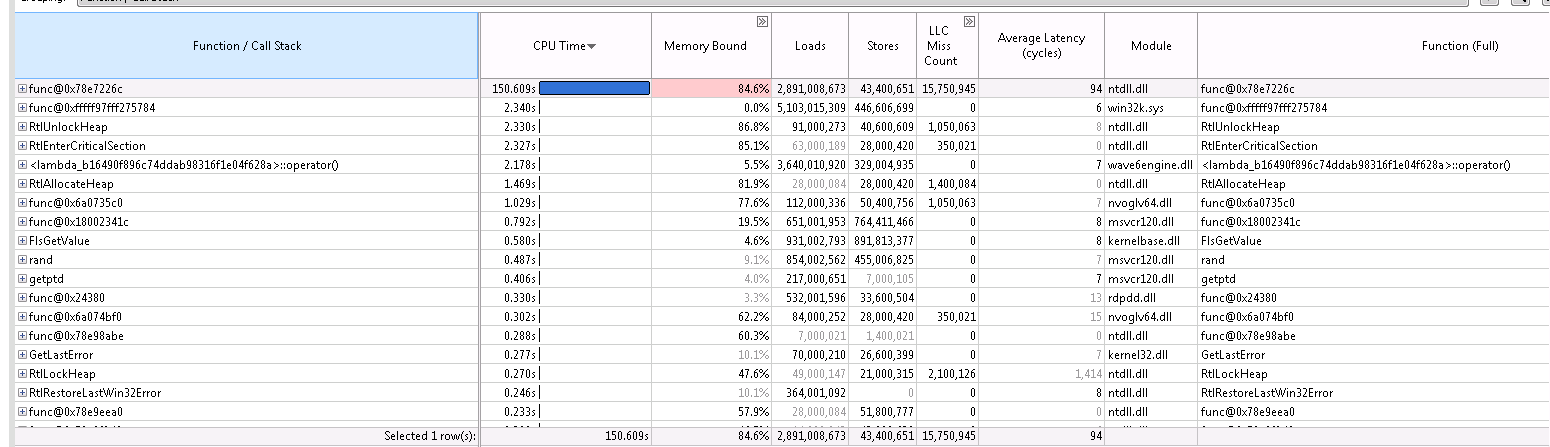
Thanks a lot for the quick reply! The bare implemented matrix matrix product is just a dummy problem for some number crunching to highlight the issue with the heap allocation - also I agree about the sum should be inside the loop .This previously used mkl dgemm, but I wanted to rule out that the issue is in any way associated with anything else than allocation - if I use dgemm it's the same issue. When profiling the problem, most of the time is spent on malloc/free for the case where I get cache misses. For the case without cache misses the std::rand function is the most expensive bit. I also wanted to rule out that the issue is not associated with any other threading libraries (OpenMP, TBB), that's why I use the future. If I create individual C++11 threads, it's the same issue
This is with hyperthreading, but the same issue comes up without hyperthreading.
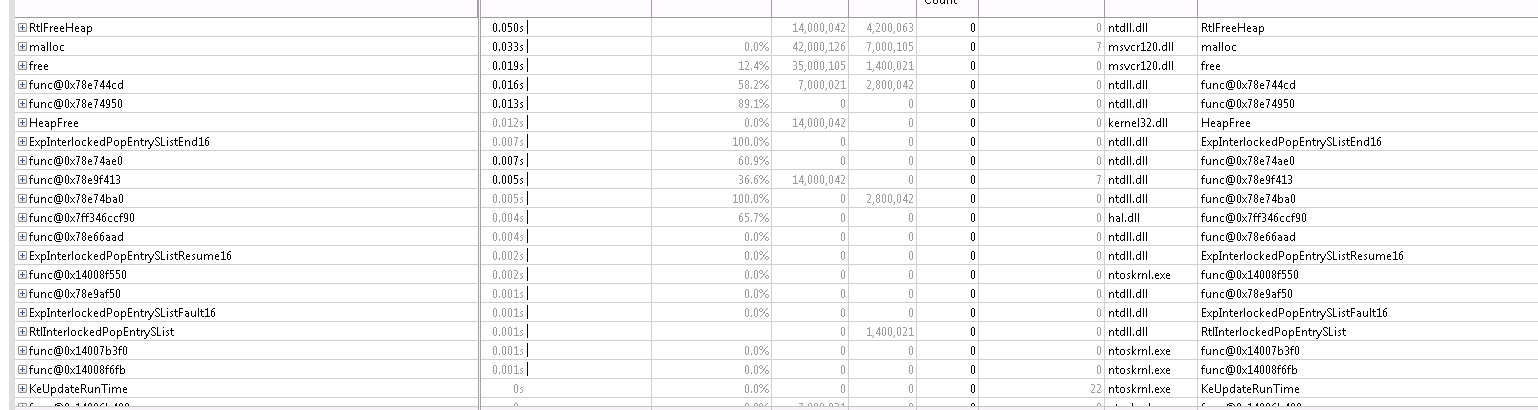
What I noticed is that I see calls to RtlUnlockHeap and RtlEnterCriticalSection for the case where I get cache misses, whereas for the other case I see calls to RtlInterlockedPopEntrySList. I.e. it looks like for one case the heap lock uses classic locks ('critical section') whereas for the other case it uses atomics.
Cheers,
Sascha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page