- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The design is compiled with Quartus 16.0 for CYCLONE V SOC with
transceivers
I follow the PCS initialization scheme suggested in the TSE user
manual and have already tried the workaround suggested in
but without success
In some cases the link comes up and data can be exchanged when the
switch is fault tolerant enough however a NW traffic analysis shows
that the autoneg does not complete in this case too.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Dlim,
thanks for your reply, that was much faster than I expected !
I have carefully read the articles, for the first KDB answer I can assure that AUTONEG is enabled on
both sides - the PCS and the switch, so this is not causing the issue.
Regarding the second KDB answer ( incorrect device availability advertized ) I'm not sure if this has
been fixed in the current quartus version. The KDB article is dated from 2012 - I have compiled my
design with Quartus 16.0 and also tried 16.1 both without fixing the problem. Is there something
like a list of release notes where I can see which issues have been fixed and which are still open ?
All the best!
Andre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi dlim,
thanks for getting back to me.
I will try to upgrade the design to the latest Quartus Version and see what happens,
further I have checked the link without autonegotiation. When I disable AUTONEG
in the PCS and the switch port my board is connected to I can estalish a connection
and exchange data, so this problem seems to be only related to the autoneg process
but not the data exchange itself.
Best regards,
Andre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dlim,
meanwhile I have also compliled the design with QUARTUS 18.1 i.e. the latest prime version that is
available ( the lite edition ). I have checked the version register of the PCS core and found that it has
been changed from 0x1000 to 0x1201 so the IP core is a newer version however the autoneg does
not work either. Only thing that makes the 1000Base-X link work properly is disabling the autoneg
on both sides ( i.e. PCS and switch ) of the connection.
Best regards,
Andre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
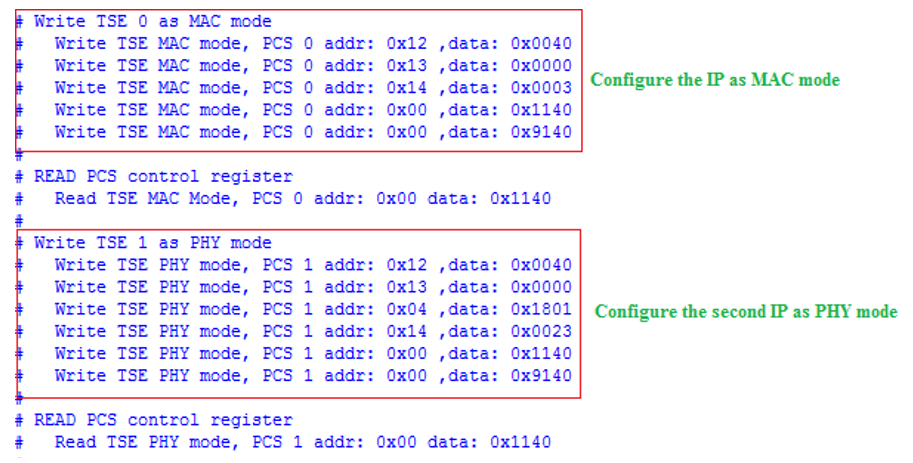
HI Andre,
The other possibility that I can think off that may affect TSE auto-nego functionality is whether user configure all the required register setting correctly.
Have you cross check your TSE design register setting vs the TSE reference design link that I shared with you earlier ?
Attached are some of the register setting that's related to TSE auto-negotiation feature. KIndly review to ensure you set them correctly.
Thanks.
Regards,
dlim
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dlim,
sorry I forgot to tell you that I'm not using the TSE MAC but have connected the PCS/PMA to a
CYCLONE V SOC HPS MAC using an appropriate bridging system - of course data between the
clock domains is properly synchronized using FIFO units. As far as I understand the MAC itself
is not involved in the AUTONEG process, this is solely carried out by the PCS/PMA. I'm using
this configuration also in SGMII mode, means the SGMII bridge is enabled. In the SGMII mode
autonegotiation between PCS and the PHY device is carried out properly. However in 1000Base-X
mode the AUTONEG is never carried out properly even whith those switches that connect to
the PCS I can see that AUTONEG process in 1000 Base-X mode is multiply repeated and
the sniffing device that listens on the optical connection shows messages like 'malformed packets'.
Obviously some end devices ( switches ) are tolerant enough to deal with this and some are not.
In the latter case I can see that the end device simply does not accept the initial autoneg sequence
( /C/ with dev_availability set to 0x00 ).
When the AUTONEG is turned off on both sides, the 1000Base-X works properly.
If there is a way to debug this via JTAG/Signal Tap connection I will try this next, maybe
this video gives some information.
https://www.youtube.com/watch?v=LKMNAmFLtEg
Best regards,
Andre
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Andre,
Thanks for sharing the debug video. Yup, that's indeed helpful and hopefully you are following the debug checklist accordingly.
Your understanding is also correct that auto-negotiation is handled at TSE PCS level and not in MAC.
- I presume you are using TSE IP with "1000 BASE-X/SGMII PCS only" setting option.
As you mentioned SGMII mode Auto-nego is working correctly and issue only impact 1000 BASE X mode, I believed there shouldn't be issue with your board system and most likely should be TSE register setting issue.
Just wonder have you cross check your TSE IP setting in 1000 BASE X mode ? Attached is TSE setting screenshot from the youtube video and I previously also screenshot the register address location to you. SGMII mode is using different setting from 1000 BASE X mode.
I would only advise to look into Auto-negotiation operation signal_tap after you verify all register setting is correct first. I can see that the video did taught user on how to signal_tap the signals accordingly
Thanks.
Regards,
dlim
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also, don't confused auto-negotiation PHY mode and MAC mode with actual TSE MAC design block.
there are two auto-negotiation setting - PHY mode and MAC mode
PHY mode = the speed and duplex mode of Intel FPGA and external device will be resolved based on the value set in the dev_ability register. Meaning PHY mode is for advertise the link speed and duplex mode to the link partner
MAC mode is wait for the link speed and duplex mode from link partner and then resolve based on the link_partner ability register.
Thanks.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi dlim,
my design is in a CYCLONE V SOC, the PCS/PMA block is used to connect the HPS Ethernet MAC ( not the TSE MAC ) to
a fibre or copper SFP. Connections are made using appropriate clock bridges. When a connection can be established
the data exchanges works fine even at high rates so I do not think the problem is here. I have identified the problem
exists only in 1000Base-X mode when autoneg is enabled on both sides. In some cases this connection may work
depending on how tolerant the switch handles autoneg, in some it does not. THE PCS/PMA block is configured to
operate in MAC mode but actually this only applies to SGMII which is causing no problems.
I follow the initialization schemes given in the Manual. Further I have tried all the Erratas I could find about this.
When I disable AUTONEG on both sides the connection can be established without problems in 1000Base-X mode
( 1000Base-T is not affected anyway as it is using SGMII ). I have compiled the design with the latest quartus lite
version 18.1 lite and tried again but the result is the same. Of course I have deleted all the databased and generated
the IP cores with the latest version to rule out there's some old data used in the new compilation then.
Further I have sniffed into the data sent coming out of the 8b10b encoder and sent to the transceiver without finding
abnormal data transmitted. Please see attachment for a screen shot - autoneg sequence starts with /C/ 0x00 as required.
We're abbout to procure a Network tester that allows sniffing the data on the fibre lines and tracking the autoneg process,
I'll get back to you when we have done this. For the time beeing I'll disable the autoneg in 1000Base-X mode and set
the link to fixed speed as a workaround. Of course it would be nice to find out what is really going wrong here.
How shall we proceed, shall we close this case and shall I ask to re-open it when I'm able to do deeper debugging ?
Thanks for for your kind support and for beeing patient with us!
Best regards,
Andre
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
HI Andre,
Thanks for providing more info. Hopefully you are able to proceed with your project development using the fix speed workaround method.
Yup, it never looks good to keep the case idle for too long. I can close this forum case first.
Once you gather enough debug info, then you can always file new case in this Intel forum again in future.
Thanks.
Regards,
dlim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi dlim,
OK, thanks again for your support!
Please close this case for now.
All the best,
Andre
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page