- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
I followed the official instructions and successfully get the IR model of YOLOv3. The code I used to generate the IR is exactly the same as the official instructions.
Then I used the Town Centre Video as the benchmark to evaluate the performance of IR model. However, I found that the classification score given by IR model seems to worse than .pb model.
The first image is the result given by IR model and the second is by .pb model. Though two models have similar performance in detecting objects, the classification score given by IR model is apparently worse.
As both models use the same precision (FP32), I assume that the result should be exactly the same without any deviation. And I also check the output of region layer with the same input image, and the outputs of both models differ. Therefore, I wonder, theoretically, is that the case? Is there any loss during conversion?
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear li, kevin
3 different Yolo V3 scores for the same model and same input is definitely strange.
First, are you using OpenVino 2019R2.01 ? It's the latest and greatest OpenVino version and many improvements/bug fixes have been made so it's worth upgrading to.
Second, are you using our Yolo V3 sample for detection ?
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Shubha,
Thanks for your reply!
1. For the first question, yes, I am using 2019R2.01.
2. For the second question, I have done some modification from the Yolo V3 sample. The main difference is just that I added a line of code to convert BGR to RGB as I don't use the --reverse_input_channels following the official instructions. And I have made sure that the input is exactly the same except that the shape is different (NCHW for openvino and NHWC for .pb model).
Here are some updates:
As what I compared for the two models are the reorg layers, I conjure that it could be the problem of output nodes defined in the model optimizer. I find another way to convert the pb model from here by directly specifying the output and input instead using the yolov3.json.
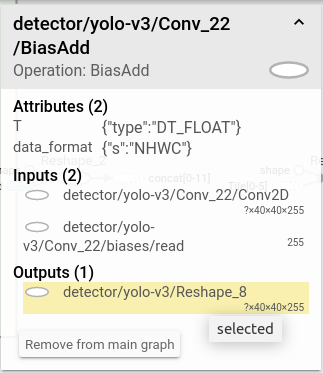
Originally, the IR model converted from the official guide using yolov3.json uses entry points ('detector/yolo-v3/Reshape, detector/yolo-v3/Reshape, detector/yolo-v3/Reshape') to specify the output nodes if I have a correct understanding. And I found that the output s from inference are "detector/yolo-v3/Conv_6/BiasAdd/YoloRegion,detector/yolo-v3/Conv_14/BiasAdd/YoloRegion,detector/yolo-v3/Conv_22/BiasAdd/YoloRegion" which are precedent nodes of the entry points. These are the nodes I compared for the two models.
However, If I specify the output nodes directly, the outputs are wired.
I first tried to specify "detector/yolo-v3/Conv_6/BiasAdd , ..., ..." as output nodes, but the actual outputs given by the inference engine are "detector/yolo-v3/Conv_6/Conv2D, ..., ..." which are the precedent nodes of "BiasAdd". So I assume the inference engine would always give outputs the precedent nodes. However, when I specified 'detector/yolo-v3/Reshape, ... , ...' as the output nodes, the names of the output layer given by inference engine are exactly the nodes I specify rather than precedent nodes and what's more, the shape of the output is [1,4800,85] which is the shape of next nodes(For clarity, please refer to the attachments for the typology). Besides, I also check all layers in the openvino net and found that 'BiasAdd' nodes are missing so I think they may be fused by openvino.
Could you please explain to me why there are these problems? And how to specify the output node correctly? Thank you so much!
Attached are the nodes information and you can also access the tensorboard log with the following link:
https://drive.google.com/open?id=18X6Yde562MznFMv_TakHl6ReikrFkR9-
Thanks!
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear li, kevin,
First of all, leaving off --reverse_input_channels shouldn't be a big deal if you've dealt with it accordingly (as you seem to have).
Model Optimizer Subgraph Replacement is the reason for those *.json files under deployment_tools\model_optimizer\extensions\front\tf (including yolo_v3.json) and it is an extremely complicated topic. By avoiding usage of yolo_v3.json and using model cutting directly by doing --input and --output, you may be creating an improperly constructed model, or, a model which OpenVino doesn't support.
If you really want to understand stuff in detail, I encourage you to step through model optimizer code and find out for yourself. To be honest, I don't know myself the answers to your questions but I could find out by stepping through the code when I run the MO command through the PyCharm debugger. This is the beauty of OpenVino, Model Optimizer, Inference Engine and even the plugins - unlike our competitors, it's 100% open source !
The easiest way to do this is as follows:
1) Download and install The Community Edition of PyCharm
2) Open up a Cmd Shell and execute bin\setupvars.bat (or *.sh if you are Linux)
3) Find out where the PyCharm exe lives. For me it lives here:
C:\Program Files\JetBrains\PyCharm Community Edition 2018.2.4\bin\pycharm.exe
4) Invoke the Pycharm exe from the shell in step 2
5) configure PyCharm to execute your Mo Command on your model, then step through the code
I guess my primary question though, is why are you going through all this trouble and why not use the verified instructions for Yolo v3 which are known to work ?
Thanks,
Shubha
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Shubha,
Thanks for your reply.
As I mentioned in the beginning, I did follow the verified instructions of Yolo v3 and successfully use the converted IR model to do inference. And I also used pycharm debugger to check the reorg layers. That's why I found the problem.
I tested the converted model and compared performance with the original model, and I found that though the converted model is good, it always gives different classification scores from the original model. Therefore, I uses pycharm debugger to check the value of reorg layer and found that the reorg layers are different. I double-checked it by regenerating the IR model with the original model (the model in the verified instructions) and still found the same results. The only difference is that I use 320 as image size rather than 416 in the verified instructions.
I even tried to compare the reorg layer from the verified model with the other frozen model from this repository , and found that they have the same value of reorg layer.
Therefore, there may be something wrong with either the IR model or the way I do inference. Then I found that the yolov3 detection sample does not convert the BRG to RGB so I did that. As a result, the performance of the inference improve a lot and is comparable to the original model. But the reorg layers are still different.
I will continue to check the inference process and update.
Thanks,
Haoming
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear li, kevin
A hah ! That's how you got so smart about Model Optimizer. Isn't it great though that you can step through the code with the Pycharm Debugger to figure out what is going on ? But seriously, I'm super glad that you did this. The code tells the full story doesn't it ?
OK, so per your statement,
. The only difference is that I use 320 as image size rather than 416 in the verified instructions.
Did you realize that convert_weights_pb.py assumes an image size of 416x416 ? Maybe that is the root of your problem. See this line:
tf.app.flags.DEFINE_integer(
'size', 416, 'Image size')
All you should do is -add --size 320 to the python3 convert_weights_pb.py command which the Model Optimizer Yolo Doc suggests.
Hope it helps,
Shubha
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page