- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have tensorflow SaveModel which I want to inference in openvino. So I convert it to IR Format and I don't get any error. But when I inference my image on the IR model, I get an output of shape [1,8,14,16] while inferencing with original tensorflow model gives me [1,23,27,8] output.
Normally this wouldn't be a serious problem since I could change the shape of resulted numpy array very easily, bit I also get wrong numbers (like instead of numbers ranging from 0-100 for probability, I get 2.24e-7 probability through all my numpy array).
So I suspect there might be something wrong during the optimization phase. Why does my IR model have different output shape? (I do not have access to my tensorflow model or code right now.)
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hesam,
Ya, you are right. The TensorFlow model successfully converted into IR model once the Model Optimizer had met the minimum required arguments. However, some missing arguments might be the reason for getting low accuracy or incorrect output shape.
Please share your command used in Model Optimizer and more information about your model (topology of model, whether the model is image classification or object detection).
If possible, please also share your model with us for further investigation.
Regards,
Peh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for the quick reply,
It turns our the probability numbers are all off because I forced the precision of IR input blob to U8 which was a bad idea. Also I fixed the output shape problem simply by transposing the numpy array and it seems to work.
There just seems to be a tiny problem:
My model is a plate detection and after fixing the previous problems it finds the plates pretty easily while inferencing on CPU. BUT, when I inference it on MYRIAD, The plates are found a bit off. Not too much, just a little. Also, no matter I use a fp16, fp32, float or half data type for my IR model, I always get the same FPS on MYRIAD.
Can this problem be fixed?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hesam,
Glad to know you make it works now.
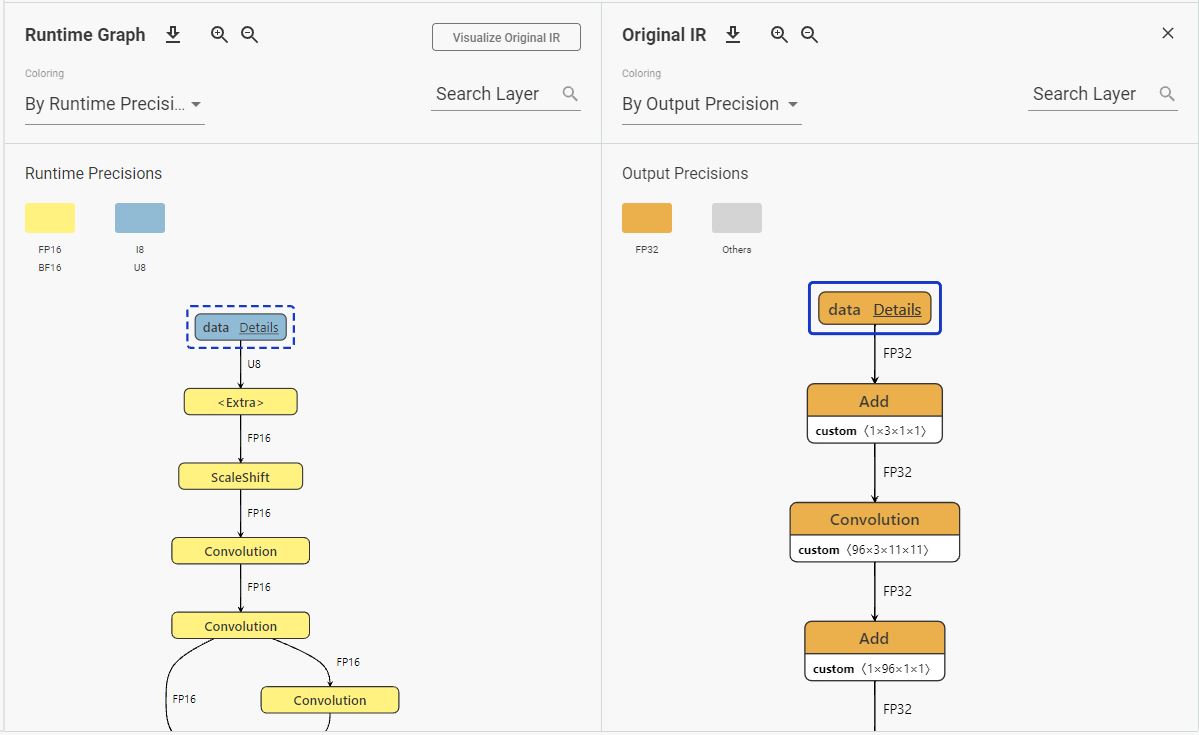
The resulting IR precision of the model, for instance, FP16 or FP32, can affect the performance. Based on the Supported Model Formats, VPU (MYRIAD) plugins only support FP16. Even though CPU supports FP16 model, but it will internally be upscaled to FP32 anyway. You can find this statement under Model Optimizer Knobs Related to Performance. I believe same things go to MYRIAD plugin although I couldn’t find any official statement to support this. Meaning that running FP32 model on MYRIAD is the same as running FP16 model because all the layers of the model are executed by MYRIAD plugin in FP16 format. You can have a look at the attached picture.
To support my findings, I visualized runtime graph in DL Workbench. Although I imported FP16 model and inferred on CPU, all the layers of the model are executed in FP32 format. Same goes to MYRIAD. Although I imported FP32 model and inferred on MYRIAD, all the layers of the model are executed in FP16 format. This would be the reason why you can run with a FP32 model, but the FPS is the same as running with a FP16 model.
Regards,
Peh
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you for the through answer. But I still have this problem that running inference on MYRIAD detects plates a bit off. Even though I tried FP32, FP16, Half, Float. Is the optimizer failing to convert to FP16 precision?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hesam,
Based on the visualization of the runtime graph in DL Workbench, I would say the model precision does not affect the runtime layer precision in CPU and MYRIAD plugin. Meaning that inferencing FP16 model in CPU plugin but it will internally be upscaled to FP32 anyway while inferencing FP32 model in MYRIAD plugin is the same as inferencing FP16 model. Hence, the comparison between CPU and MYRIAD plugin will become the comparison between FP32 and FP16 models. Therefore, inferencing on CPU plugin definitely results in better result.
On a separate note, I would like to share these two workarounds with you, but the results may vary based on the models. Some folk claimed that it worked, while some folk claimed that it did not work for their models. (References: #1551, #1822, #2109 and #2637)
Method 1:
Disable MYRIAD hardware acceleration in the source code.
ie = IECore()
ie.set_config({'MYRIAD_ENABLE_HW_ACCELERATION': 'NO'}, "MYRIAD")
net = ie.read_network(model=model_xml, weights=model_bin)
exec_net = ie.load_network(network=net, device_name="MYRIAD")
Method 2:
Re-generate IR model using the Model Optimizer by specifying the scale value. The scale value should be up to 255.
python mo.py --input_model <model.xml> --scale <value>
Regards,
Peh
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you so much for your help.
Both methods worked fine, though the first one resulted in a decrease of FPS but the second method resulted in a bit of increase since there is no need to devide the input image by 255 any more.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Hesam,
This thread will no longer be monitored since we have provided answers and suggestions. If you need any additional information from Intel, please submit a new question.
Regards,
Peh
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page