- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
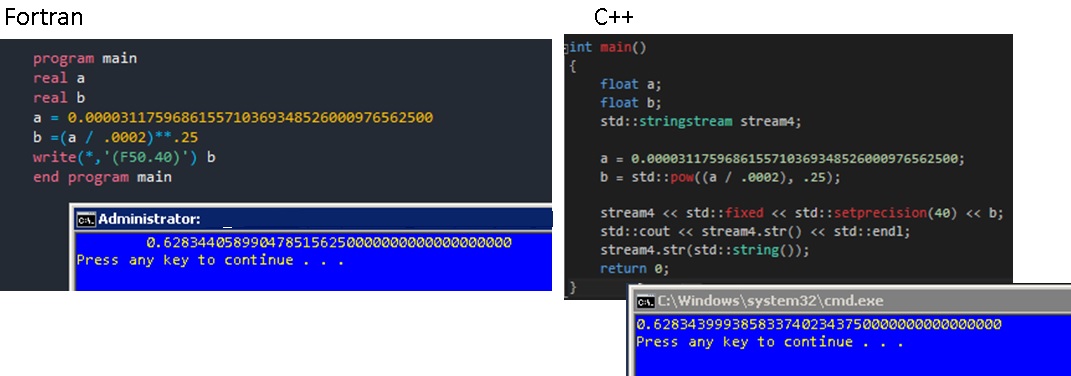
Hello,
I believe that float (and Fortran default real) has 6 digits of precision, so the "a" assignment already loses information. "b" has similar limitation. You notice that the outputs up to 6 digits are pretty close. I recommend you also print "a", to see, if there's a difference even before the power is computed.
Thank you,
--Eugene
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Do you understand that you are doing this computation in single precision, good to only about six decimal places? All those extra digits in the constant are wasted. When I try this in double precision, the Fortran answer you get is closer to the double-precision result than the C answer.
While I might at first suggest that it's the C result that is worse, I think your expectations are unrealistic considering the use of single precision.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If you use the pow() function and constants without suffix f in C, those are typed double. For C float, powf() may be available, but you have no assurance that it doesn't use pow(). As you saw, exponentiation for large or small magnitude arguments may be inaccurate in the low order 4 bits, although the scalar one in ifort may be a little better.
For the case x**.25d0, sqrt(sqrt(x)) should be faster (at least in the non-vectorized case) and more accurate.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear all,
Thank you for all answers.
I know the limits about single precision calculation, but i must to performe the same results in C as i found in Fortran program.
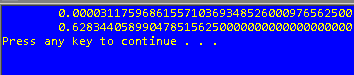
Eugene, when i print out the variable "a" i got the same constante value already informed (you can find in attachments).
Steve and Tim, when i change the fortran code constants to double
program main
real*4 a
real*4 b
a = 0.0000311759686155710369348526000976562500
b =(a / .0002d0)**.25d0
write(*,'(F50.40)') b
end program main
i got the same result as C, but i need in C the same result as Fortran (knowing about the numerical problems). I did the changes in C code to float type but i got the same results as double type.
Best regards.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I believe "real*4" is still equivalent to "float".
You need "real*8" for "double".
Also, you need to add suffix "_8" to your literal constant, otherwise it would still be treated as single precision:
a = 0.0000311759686155710369348526000976562500_8
You would need to add the suffix to all literal floating point constants you use in the code.
(Before I get beaten up for using non-standard way to specify precision, I'd like to point you to this article that describes a standard way to specify precision in Fortran: https://software.intel.com/en-us/blogs/2017/03/27/doctor-fortran-in-it-takes-all-kinds )
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Pugliesi, Raphael wrote:
.. but i need in C the same result as Fortran (knowing about the numerical problems). I did the changes in C code to float type but i got the same results as double type. ..
@Pugliesi, Raphael,
Given the differences between C and Fortran re: how literal constants are treated and consequent potential for mixed-mode arithmetic, can you not employ consistent use of floating-point "double" in both sides of your mixed-language code? You can then achieve the "same" result. See below:
module kinds_m
use, intrinsic :: iso_c_binding, only : WP => c_double
end module
module m
! Work with defined kinds in Fortran
use kinds_m, only : WP
use, intrinsic :: iso_fortran_env, only : output_unit
implicit none
contains
subroutine Fsub() bind(C, name="Fsub")
real(WP) :: a
real(WP) :: b
real(WP), parameter :: D = 0.0002_wp
real(WP), parameter :: E = 0.25_wp
a = 0.0000311759686155710369348526000976562500_wp;
b = (a/D)**E;
write( output_unit, fmt="(g0,g60.40)" ) "b (Fortran): ", b
return
end subroutine Fsub
end module
#include <iostream>
#include <cmath>
using namespace std;
extern "C" {
// Prototype for a Fortran subprogram
void Fsub(void);
}
int main( )
{
double a;
double b;
const double D = 0.0002;
const double E = 0.25;
a = 0.0000311759686155710369348526000976562500;
b = std::pow((a/D), E);
cout.precision(40);
cout << "b (C++): " << fixed << b << endl;
Fsub();
return 0;
}
With the use of Intel Fortran as well as Microsoft C/C++ compiler, the above yields upon execution:
b (C++): 0.6283440254388115153716398708638735115528 b (Fortran): 0.6283440254388115153716398708638735115530
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi, if you want single precision in C/C++ (i.e. float), Tim P. gave the important hint in #4. Default precision in C/C++ is double precision, isn't it. You can modify FortranFan's C/C++ example by swapping to float and adding suffix "f" (without underscore, e.g. http://en.cppreference.com/w/cpp/language/floating_literal). I don't know how C/C++ handles implicit type casting, so one should be careful by using functions as pow().
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page