- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Colleagues,
In an effort to solve stack space problems, which occur on some machines and for some large projects, I set the compiler flag so that all temp arrays are on the heap. The recompiled coded now executes, but is ~10 times slower (really!). I've raked through old posts to this forum and found a couple of (old) references that speak of the (expensive) need to create temporary arrays when calling routines.
But I don't think that applies; virtually all routines used in this code have calling parameters that are references to allocatable arrays that have already been allocated in the calling program. So, as I understand, it, temporary arrays are NOT required for these calls. And, setting the runtime "Check for Actual Arguments Using Temporary Storage" shows only the call to a cross product routine defined in the Module for the main program and routines.. To be sure, there are temporary arrays inside the called routines, but it isn't clear why placing them on the Heap would slow things down so much.
These calls are typically inside loops that have been threaded using OpenMP.
Any insights, information, ideas?
David
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You're correct that passing an allocatable array will not result in a temp being created.
If the routine with the temp arrays is small and called very often, the allocation and deallocation of the temps could be noticeable. There is also usually an extra data copy or two with any temp. Before you spend any more time on this, run the program under VTune Amplifier and see where the time is actually being spent.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In cases where your application is multi-threaded, and the problem some procedures have excessive delays due to heap management, consider making the temporary arrays threadprivate and where necessary allocatable (with per-thread allocation).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steve,
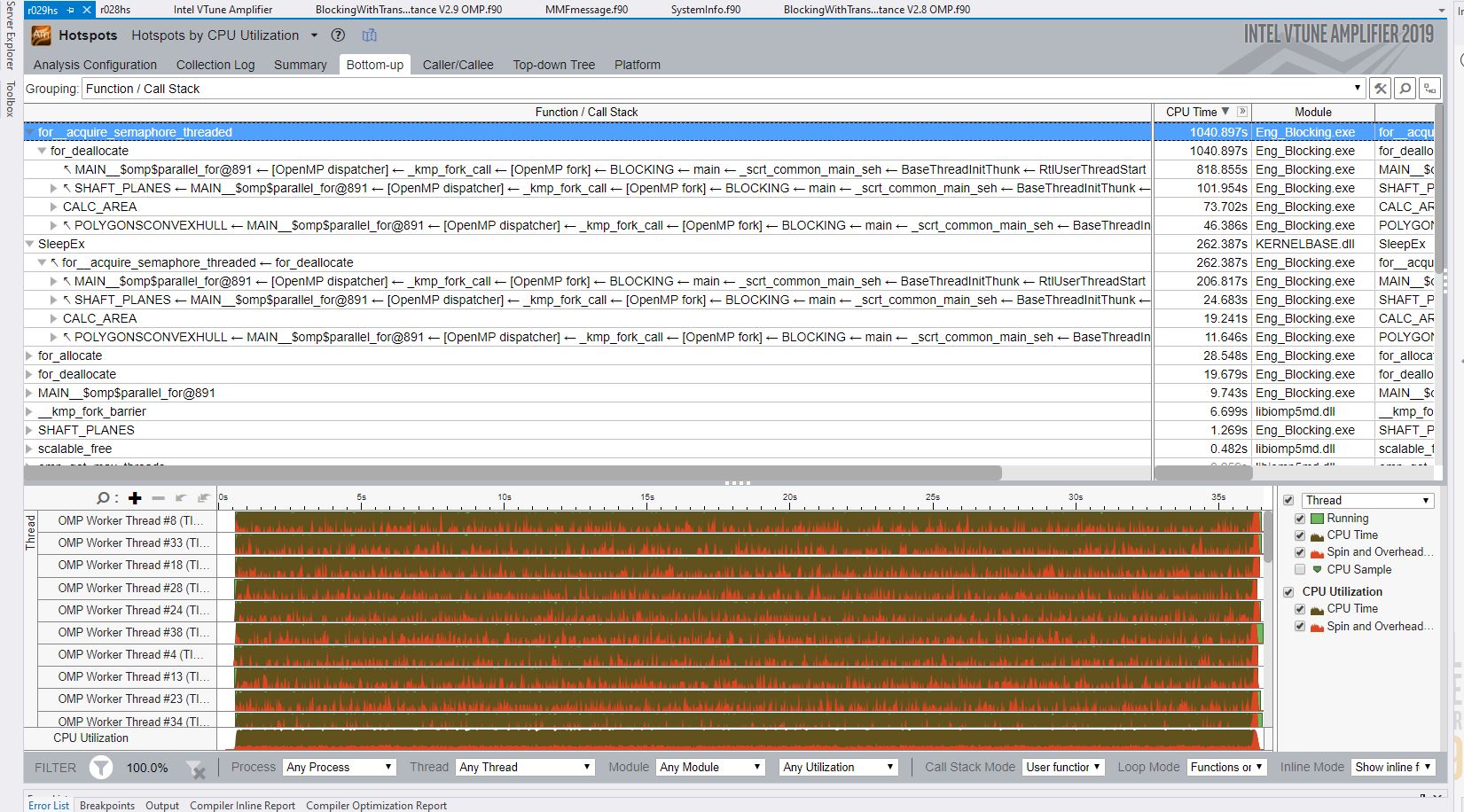
VTune is very revealing (in a way). The results are shown in the attached screen capture JPGs. The difference in execution times (No Heap, Heap) is startling. In the Heap case, "for_acquire_semaphore_threaded" consumes most of the time. @891 points to the code line that begins the description of the OpenMP parameters for a loop. Perhaps it is significant that there are many Private variables in this threaded section. I now assume that Heap is causing OpenMP to setup code that behaves quite differently regarding private threaded variables.
The other large amount of time for "for_acquire_semaphore_threaded" is for the following call:
call shaft_planes( verts(1,1,rec), verts(1,1,send), edges(1,1,rec), edges(1,1,send), shaft_plane, num_planes )
I thought that this would be sending addresses to the called routine, and not involve temps that would be placed on the Heap, but something must change when Heap Arrays is invoked.
Though I see where the time is going, I'm no further along in understanding since I don't know what "for_acquire_semaphore_threaded" is doing.
I did find another post on the this forum from back in September of this year, with another member explaining exactly the same phenomenon. There wasn't really a resolution in that case.
David
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In a parallel application, the heap allocation routine has to protect its access to the storage pool, and it does this with a semaphore. For some reason this operation is taking a very long time, or there is too much contention for the lock.
Jim is a much better resource for OpenMP-related issues than I am. But maybe you can figure out a way to not have the compiler create a temp? Where is it doing this? It can happen for array expressions and for local arrays of run-time size.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If these temps are automatic these can be determined with the runtime check for array temporary created. Generally the automatic array temporaries are created on the stack as opposed to on heap. They are usually created via
arrayOut = arrayExpression
or
arrayOut = FortranArrayFunction
Where the expression or function cannot easily be seen as using contiguous array (slices) or where the arrayOut is part of the right hand side. These automatic array temporaries (when obtained from heap) can be eliminated in many cases by explicitly using a DO loop.
In the cases where your source code is explicitly creating arrays, consider using the threadprivate technique and then only allocate the threadprivate array on first use or when size needs to be increased.
subroutine foo(args)
real :: args
real, save, allocatable :: localArray(:)
!$omp threadprivate(localArray)
...
if(allocated(localArray)) then
if(size(localArray) .lt. sizeYouWant) then
deallocate(localArray)
allocate(localArray(sizeYouWant))
endif
else
allocate(localArray(sizeYouWant))
endif
...
Something like that. If you have a similar temporary array that can be used (without conflict within a thread) by multiple procedures, then place the threadprivate array in a module.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also, if the size of the local array is larger than required, BUT your code is written where you simply use the array name as opposed to array with subsection, then consider naming the threadprivate variable differently (tpYourLocalArray) and then use:
ASSOCIATE(YourLocalArray => tpYourLocalArray(1:sizeYouWant))
...
END ASSOCIATE
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In my experience, which admittedly is starting to go stale, the "arg_temp_created" warnings are not issued for temps created for expressions or assignments. I saw these only when calling a procedure and, annoyingly, I/O statements.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This is probably dumb, but would the available stack space be easy to use some more from wherever the stack pointer points, whereas a heap transaction for each time a local variable is allocated be more expensive?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Stack allocation is "almost free". The problem is that stack space is limited, especially in a threaded application. If you're getting stack overflows in an OpenMP application you can try setting the environment variable for stack size (OMP_STACKSIZE) before running the program and see if that helps.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page