- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We updated from version 13.1 of the compiler to 15.0.2.179 for a large CFD FORTRAN code and started having cases of the solver hanging: sitting in memory with 0% CPU used. Here are the observations so far:
1. happens only on Windows.
2. running on a single thread works fine.
3. the executable runs for a while before it hangs. restarting the solver from an intermediate time runs fine.
4. for the cases we have so far, it hangs in different parts of the code, but for a given case it always hangs at the same location.
Here is a code snippet where it happens in one of the cases. This is a sub-section of a large subroutine. This code is invoked several million times before the solver hangs:
c Here we are adding a column to the Hessenburg matrix (hmatrix)
do kk=1,igfy
hmatrix(kk,igfy)=zero
do n=1,numthrds
flp_lcl(1,n)=hmatrix(kk,igfy)
enddo
c
do nbl=1,nblcks
! divide the loop between threads
call load_bal(0,ijklim(nbl,1),nijkpr(nbl)) ! NBL is a global variable, comes from a module
!$omp parallel do schedule(static,1)
!$omp& private(n,nn,ijk)
do n=1,numthrds ! loop over threads
do nn=klo(n),khi(n)
ijk=ijkpr(nn)
flp_lcl(1,n)=flp_lcl(1,n)+vvect(ijk,igfyp1)*vvect(ijk,kk)
enddo
! PUTTING A PRINT STATEMENT HERE PRINTS ALL THREADS.
enddo ! THIS IS THE LINE WHERE IT HANGS.
enddo
Could this have been resolved in version 15.4 or 16.0 of the compiler?
Thank you for any help you can provide.
Michael
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Would it help to declare flp_lcl as shared ?
I would use:
!$omp parallel do & !$omp& schedule (static,1) & !$omp& shared (kk, numthrds, klo, khi, ijkpr, flp_lcl, vvect, igfyp1) & !$omp& private (n, nn, ijk) do n = 1,numthrds ! loop over threads do nn = klo(n),khi(n) ijk = ijkpr(nn) flp_lcl(1,n) = flp_lcl(1,n) + vvect(ijk,igfyp1) * vvect(ijk,kk) end do ! PUTTING A PRINT STATEMENT HERE PRINTS ALL THREADS. end do ! THIS IS THE LINE WHERE IT HANGS. !$omp end parallel do
John
( your example mixes fixed and free format ?)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi John,
Thanks for the quick response.
Isn't FLP_LCL shared by default? I failed to mention that we use the approach of arrays of size (1:numthrds) to do the reductions, instead of using OpenMP contructs for that. We've been doing this for years, so i have faith in it :-). The first index is to space the 'n' access by at least a cache line to reduce unnecessary cache updates.
I am trying now explicit 'shared' pragma placements. Also, i am replacing KK in that loop, which is an outside DO loop iteration that includes the OpenMP loop, with a local variable just for the OpenMP loop. Maybe it will make it easier for the compiler to process it.
You are right about the mix of fixed and free format. The original code is actually using fixed format, i just modified it here to be more compact. Sorry about it.
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again, John.
I tried your suggestion - same result. Hangs at the same location. Am going to version 15.0.4 of the compiler now.
Michael
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try a variation to see what is happening:
!$omp parallel & !$omp& shared (kk, numthrds, klo, khi, ijkpr, flp_lcl, vvect, igfyp1) & !$omp& private (n, nn, ijk) print *,omp_get_thread_num() !$omp do & !$omp& schedule (static,1) & do n = 1,numthrds ! loop over threads do nn = klo(n),khi(n) ijk = ijkpr(nn) flp_lcl(1,n) = flp_lcl(1,n) + vvect(ijk,igfyp1) * vvect(ijk,kk) end do end do ! THIS IS THE LINE WHERE IT HANGS. !$omp end do print *,omp_get_thread_num() !$omp end parallel
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You might also want to verify numthrds is what you expect.
You should see each thread number twice. If one of them does not print out twice, verify that do nn= has valid ranges. A very large index range without subscript checking could be walking over non-mapped virtual memory (may take a long time to error out).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Will give it a shot, Jim, thank you.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Per Jim's suggestion, i added the print statements to the DO loop (the variable cycle is used to reduce the amount of output). It print the thread id, then the loop iteration, than a tag: 'a' at the beginning of the loop, 'b' - at the end.
!$omp parallel do schedule(static,1)
!$omp& private(n,nn,ijk)
!$omp& shared(kk_loc,igfyp1,klo,khi,ijkpr,dmx_lcl,vvect,numthrds)
do n=1,numthrds ! MRB
if(cycle.gt.370000) print *,omp_get_thread_num(),n,'a'
do nn=klo(n),khi(n)
ijk=ijkpr(nn)
dmx_lcl(1,n)=dmx_lcl(1,n)
& +vvect(ijk,igfyp1)*vvect(ijk,kk_loc)
enddo
if(cycle.gt.370000) print *,omp_get_thread_num(),n,'b'
enddo
enddo
the result for the last three time the loop is executed is:
0 1 a
1 2 a
2 3 a
3 4 a
0 1 b
1 2 b
2 3 b
3 4 b
0 1 a
3 4 a
2 3 a
1 2 a
0 1 b
3 4 b
2 3 b
1 2 b
3 4 a
2 3 a
0 1 a
1 2 a
3 4 b
2 3 b
0 1 b
1 2 b
After the last line is hangs. I also tried 15.0.4 and 13.1 compilers to the same result. There's gotta be something wrong with this code, but i can't figure it out!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
While you still have some hair left, try inserting some asserts:
if(n > ubound(klo)) print "(n > ubound(klo))" if(n > ubound(khi)) print "(n > ubound(khi))" do nn=klo(n),khi(n) if(nn < lbound(ijkpr)) print "(nn < lbound(ijkpr))" if(nn > ubound(ijkpr)) print "(nn > ubound(ijkpr))" ijk=ijkpr(nn) if(n > ubound(dmx_lcl,dim=2)) print "(n > ubound(dmx_lcl,dim=2))" if(ijk < lbound(vvect, dim=1)) print "(ijk < lbound(vvect, dim=1))" if(ijk > ubound(vvect, dim=1)) print "(ijk > ubound(vvect, dim=1))" if(igfyp1 < lbound(vvect, dim=2)) print "(igfyp1 < lbound(vvect, dim=2))" if(igfyp1 > ubound(vvect, dim=2)) print "(igfyp1 > ubound(vvect, dim=2))" if(kk_loc < lbound(vvect, dim=2)) print "(kk_loc < lbound(vvect, dim=2))" if(kk_loc > ubound(vvect, dim=2)) print "(kk_loc > ubound(vvect, dim=2))" dmx_lcl(1,n)=dmx_lcl(1,n)+vvect(ijk,igfyp1)*vvect(ijk,kk_loc) enddo
Bounds checking should have caught this.
Note, if this is a Windows app (IOW not a console app), then the console error dump window may appear underneath the Window of the application *** or be a NULL bit bucket ***.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
By the way, I usually have a subroutine named DOSTOP that I call with the error message. I can then place a single break point in the DOSTOP routine to catch any call, then step out to investigate the cause.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
on it!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Update so far.
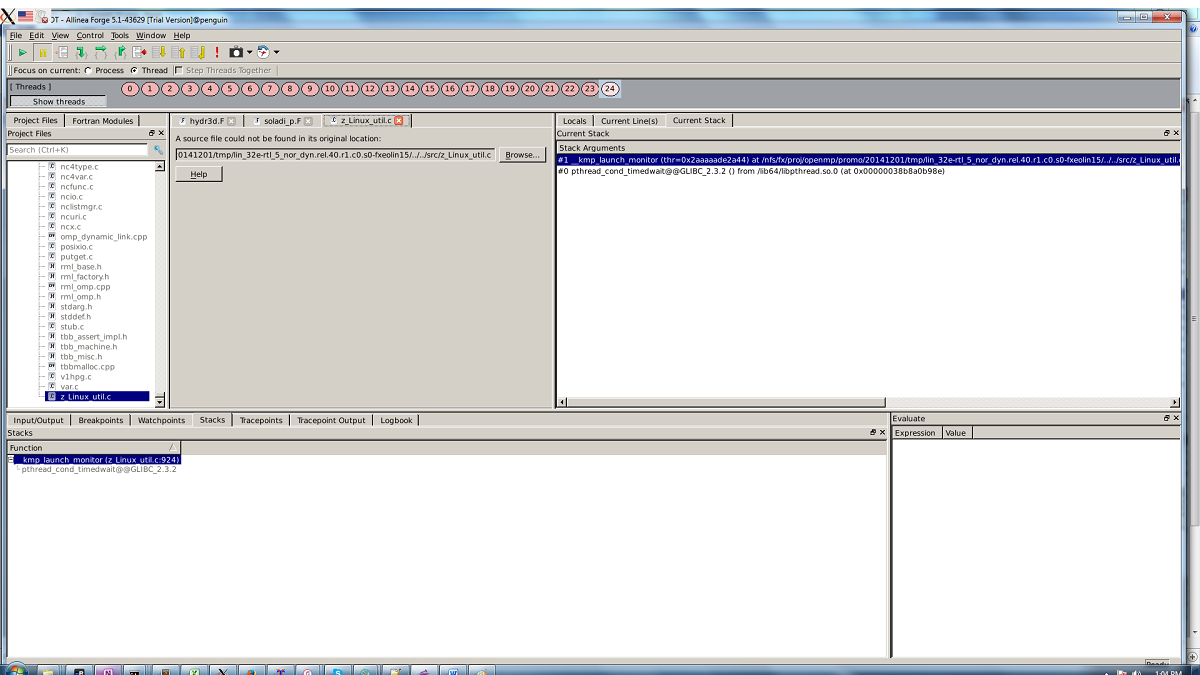
Ran the solver on Linux through Allinea's DDT debugger. The traceback information at the point of hanging is in the image below.
Updated to the 16.0 version of Intel's compiler. The problem started working on Linux, but still hangs on Windows. Looks like the problem may be in the dynamic libiomp5 library. I can't believe no one else is having such problems. Could some please help with any pointers?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
There is a separate thread on the forum that is exhibiting a hang situation. I have posted a response to that thread, where a long time ago when I wrote my threading toolkit, that I experienced a similar situation where the pthread_cond_wait would experience a race condition with pthread_cond_signal (or at least seemed so). This happened rarely and only under a stress test. After a couple of weeks of trying to resolve this I replaced the pthread_cond_wait with a pthread_cond_timedwait. Then on the rare condition where the race condition occurred, the timeout would occur and the code would retest the wait condition (resume if satisfied, timedwait again if not). In that case and I suspect your case, the root of the cause is not with OpenMP but rather within the underlying pthread library. Caution, this is only a supposition on my part, none the less, the fact that pthread_cond_wait hanging and pthread_cond_timedwait, followed by timeout, followed by retest condition succeeding (not necessarily the condition variable but an independent variable set to indicate the pthread_cond_signal had been called), was a very strong indication that something is amiss within the pthread library.
I know that this does not solve your issue. Perhaps this information will provide a lead (or red herring) for the Intel support folks.
In your screen shot you show the stack of the main thread. Where are all the other threads sitting? (inside the parallel region or outside and in an idle thread holding spot)
Also, your screenshot shows 25 threads. While one may be an internal OpenMP watchdog thread or helper thread, is there anything else we need to know (for example are you running nested parallel regions or this region called from within an OMP Task).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you, Jim, I just found that thread. In fact, AGG on that threads works with me.
We are not running nested parallel regions and not calling this region from an OMP task. The simulation is running on 24 threads. I assume 0 refers to the main process and 1-24 to the spawned threads.
The run has since been terminated so I can't get more information. We are going to rerun it to reproduce the problem and query DDT more. We just started using DDT and have a meeting with the Allinea guys today to give us more training. I should be able to provide more information later today or tomorrow.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content


- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Here's a summary of what I posted to the other thread:
I reran similar tests on two different Windows systems (Windows 7 and Windows Server 2012 R2).. I was able to reproduce the hang with the version 15 compiler and RTL, but not with 16.0. This for both C and Fortran test cases.
The developers confirmed that the fix that was made to the OpenMP RTL in 16.0 was made for both Linux and Windows. Incidentally, this fix should also be present in the 15.0 update 5 compiler that will be posted very soon.
Please can you tell us more about the environment in which you see a problem with the 16.0 compiler? E.g. exact version of Windows; VS version; static or dynamic linking (I think OpenMP is always linked dynamically on Windows); the OpenMP RTL version as printed out when you set KMP_VERSION=yes; what sort of system you are running on (sockets, cores, threads, microarchitecture, 64 bit)? Better still if you can provide a test case to reproduce the problem.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Michael,
From your two samples, the threads are hanging at an OpenMP barrier. The causes are:
Not all threads of the team entering the barrier. In your examination of threads 0:23, were all at the same barrier?
If not, then is the thread waiting at a different barrier (IOW you have multiple barriers in the region and control flow that permits partial number of team members to reach the barrier, this would be indicated by one or more team members stuck at a different barrier).
Or, you have some other activity that presents a deadlock or other race condition that is inhibiting one or more threads of the team from looping back to the barrier that is observed in the above screenshots (this may be exhibited by one or more threads running at the deadlock).
Or, if one or more threads are outside the do kjsum loop then those threads iterated fewer times than the other threads of the team (meaning kprb+jprf and/or kemx+jemx were not producing the same number of iterations for all team members).
If all the threads are at the same barrier, then this may be the pthread_cond_wait issue
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you, Jim, we will examine the output from each thread from DDT. Just in case, here my yesterday's post on Javier's thread:
Martyn, glad you were able to reproduce the problem. Unfortunately, I cannot easily create a test case for you since the FORTRAN code is massive. Could I try your test case instead?
The 15.0.4 compiler did not work on either Linux (see AGG's post above for the flavor) or Windows.
Setting KMP_VERSION=yes produces the expected result on the Linux machine, where the 16th version works, but does not give any additional output on my Windows machine. We are linking dynamically using /MD and /Qopenmp options. When I type 'which libiomp5md.dll' is gives
C:/Program Files (x86)/IntelSWTools/compilers_and_libraries_2016.0.110/windows/redist/intel64/compiler/libiomp5md.dll
The Windows machine is running 64-bit version of Windows 7 Professional SP 1. OpenMP linked dynamically. The version of libiomp5md.dll is 20150609 (get it by running filever on it), same as on the Linux machine where it works.
The processor is i7-4930 3.4 GHz, one socket, 6 real cores, hyperthreaded (my problem fails both on 12 and 4 threads; have not tried other combinations). Let me know if you need more info.
I also attach an image from the dependency walker to show the dynamic libs the executable (hydr3d.exe) depends on, including the openmp library.

{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Michael,
15.0.4 contains the compiler library bug that Vladimir and I have referred to before. We need to focus on the behavior of the fixed library that is found with the 16.0 compiler. Here's a very simple Fortran reproducer:
program Test
do i = 1, 1100000000
call sub
if(mod(i, 1000000).eq.0) print *, i
enddo
end program Test
subroutine sub
!$omp parallel do
do j = 1, 200
end do
end subroutine sub
Compile with ifort /Qopenmp Test.f90
Here's a C version:
#include<stdio.h>
void Test()
{
#pragma omp parallel for
for(int j=0;j<200;j++)
{
}
}
int main()
{
for (int i=0; i< 1100000000; i++)
{
Test();
if(i%1000000==0) printf("i=%d\n",i);
}
return 0;
}
icl /Qopenmp Test.cpp
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you, Martyn, i will try it.
Jim, according to DDT, all threads 0-23 are at the SAME location.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page