- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
The following piece of code (extracted from real application and modified to reproduce the issue with minimum amounts of code)
runs approx 3x slower compiled with ifort 18.0.2 comparing to 14.0.1.
program cmp
parameter (NITER = 1000000)
parameter (NDIM = 100)
integer skeys(NDIM)
integer pkeys(NDIM)
integer i, cmpcnt
skeys = 0
pkeys = 1
cmpcnt = 0
do i = 1 , NITER
ikey = 1
icnt = 1
do while (ikey .le. NDIM .and. icnt .le. NDIM)
if (skeys(icnt) .gt. pkeys(ikey)) then
ikey = ikey + 1
else
icnt = icnt + 1
endif
enddo
cmpcnt = cmpcnt + ikey / icnt
enddo
print *, cmpcnt
end program
The same flags was used to compile both versions:
-qopt-report-file=vecreport -qopt-report=5 -O3
The assembly generated for the inner loop in the two cases:
14.0.1 (fast)
..B1.7: # Preds ..B1.8 ..B1.6 ..B1.10
..LN41:
.loc 1 25 is_stmt 1
movl -4+cmp_$SKEYS.0.1(,%rdi,4), %edx #25.18
..LN42:
cmpl -4+cmp_$PKEYS.0.1(,%rax,4), %edx #25.30
..LN43:
jle ..B1.10 # Prob 50% #25.30
..LN44:
# LOE rax rcx rbx rdi r13 r14 r15 esi r12d
..B1.8: # Preds ..B1.7
..LN45:
.loc 1 26 is_stmt 1
incq %rax #26.17
..LN46:
.loc 1 24 is_stmt 1
cmpq $100, %rax #24.27
..LN47:
jle ..B1.7 # Prob 99% #24.27
..LN48:
jmp ..B1.12 # Prob 100% #24.27
..LN49:
# LOE rax rcx rbx rdi r13 r14 r15 esi r12d
..B1.10: # Preds ..B1.7
..LN50:
.loc 1 28 is_stmt 1
incq %rdi #28.16
..LN51:
.loc 1 24 is_stmt 1
cmpq $100, %rdi #24.48
..LN52:
jle ..B1.7 # Prob 99% #24.48
..LN53:
# LOE rax rcx rbx rdi r13 r14 r15 esi r12d
..B1.12: # Preds ..B1.10 ..B1.8
18.0.2 (slow)
..B1.7: # Preds ..B1.6 ..B1.8
# Execution count [4.97e+07]
..LN44:
.loc 1 25 is_stmt 1
movl -4+cmp_$SKEYS.0.1(,%rdi,4), %r8d #25.14
..LN45:
.loc 1 26 is_stmt 1
lea 1(%rax), %rdx #26.17
..LN46:
.loc 1 25 is_stmt 1
movl -4+cmp_$PKEYS.0.1(,%rax,4), %r9d #25.14
..LN47:
.loc 1 26 is_stmt 1
cmpl %r9d, %r8d #26.17
..LN48:
.loc 1 28 is_stmt 1
lea 1(%rdi), %r10 #28.16
..LN49:
.loc 1 26 is_stmt 1
cmovg %rdx, %rax #26.17
..LN50:
.loc 1 28 is_stmt 1
cmovle %r10, %rdi #28.16
..LN51:
.loc 1 24 is_stmt 1
cmpq $100, %rax #24.27
..LN52:
jg ..B1.10 # Prob 1% #24.27
..LN53:
# LOE rax rcx rbx rdi r13 r14 r15 esi r12d
..B1.8: # Preds ..B1.7
# Execution count [4.93e+07]
..L13:
..LN54:
..LN55:
cmpq $100, %rdi #24.48
..LN56:
jle ..B1.7 # Prob 99% #24.48
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the time I worked at Intel, it was well known that Intel CPUs, beginning with P4, performed poorly with those conditional move instructions. For that reason, ifort would avoid them. From before the design of your CPU, the Loop Stream Detector could capture code even with a few branches like yours, and execute efficiently. I don't know whether the latest CPUs changed this preference for avoiding the conditional moves.
The lea instructions always were slow, and there is a clear dependency between that and the conditional move 2 instructions later. You might be able to get partial confirmation from VTune or Advisor that this is a problem. If so, and you have at least -O1 set, this seems like a code generation bug.
At -O0 (the default with -g or -debug options), such slow code is expected. It's something of a dilemma, the -O0 code is designed to avoid apparent discrepancies between original source code and order of execution, to avoid annoying unexpected jumps. There is an option -debug-inline-debug-info which I find important for debugging and performance profiling with -O2 or higher set.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
While you are awaiting a fix to the performance issue, you might try this code modification:
program cmp parameter (NITER = 1000000) parameter (NDIM = 100) integer skeys(NDIM) integer pkeys(NDIM) integer i, cmpcnt, foo skeys = 0 pkeys = 1 cmpcnt = 0 do i = 1 , NITER ikey = 1 icnt = 1 do while (ikey .le. NDIM .and. icnt .le. NDIM) foo = iand( (skeys(icnt) .gt. pkeys(ikey)), 1) ikey = ikey + foo icnt = icnt + 1 - foo enddo cmpcnt = cmpcnt + ikey / icnt enddo print *, cmpcnt end program
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Preferably you would have turned off the non-standard extension Jim suggests. A standard compliant way to do the same thing:
foo = merge(1, 0, skeys(icnt) > pkeys(ikey))
This should limit the code to one conditional move per loop iteration.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thank you for your comments. I have tried both the merge and the iend solution. The generated assembly is the same in both cases.
The generated instructions differ slightly depending on the compiler version. The runtimes are almost the same for the two compilers.
See below the assembly generated by the 18.0.2.
..B1.7: # Preds ..B1.6 ..B1.8
# Execution count [5.26e+06]
movslq %r12d, %r12 #31.15
movslq %ebx, %rbx #31.15
xorl %edx, %edx #31.15
movl -4+cmp_$SKEYS.0.1(,%r12,4), %eax #31.15
cmpl -4+cmp_$PKEYS.0.1(,%rbx,4), %eax #31.15
setg %dl #31.15
addl %edx, %ebx #32.15
negl %edx #33.29
lea 1(%r12,%rdx), %r12d #33.27
cmpl $100, %ebx #30.28
jg ..B1.10 # Prob 18% #30.28
# LOE r13 r14 r15 ecx ebx esi edi r12d
..B1.8: # Preds ..B1.7
# Execution count [4.31e+06]
cmpl $100, %r12d #30.49
jle ..B1.7 # Prob 99% #30.49
# LOE r13 r14 r15 ecx ebx esi edi r12d
..B1.10: # Preds ..B1.7 ..B1.8
# Execution count [1.00e+06]
Interestingly this version of the code runs slower than the previous version with the explicit if-else.
Especially for the case where the previous version compiled was compiled with 14.0.1 (the fast code), the slowdown is quite significant, approximately 6x.
Taking into account that this is always a taken branch and the branch prediction is working well I would expect the new code to run slower as we now have more instructions on the critical path?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is odd that the compiler chose to use lea. Seeing that TimP indicated that on some CPUs that lea is slow.
What happens with adding ()'s to
icnt = icnt + (1 - foo)
and using a compiler option that protects parens.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
I have added the parenthesis and compiled with -fprotect-parens. The generated code is the same.
The lea is present in all optimization levels until -O0.
In fact the -O0 compilation seems to run approx 25% faster comparing to -O3 for all cases apart from the original if-else code
from comment #1 compiled with 14.0.2 (that happens not to use lea).
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Alright, plan C:
Try: icnt = icnt + ieor(foo, 1) ! or use the equivalent: jieor, ixor, xor
FWIW, you shouldn't have to go through these hoops, but in the event you need something faster now, it may be worth experimenting.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Thanks, I have tried icnt = icnt + ieor(foo, 1). The lea is now gone.
..B1.7: # Preds ..B1.6 ..B1.8
# Execution count [5.26e+06]
movslq %r12d, %r12 #31.15
movslq %ebx, %rbx #31.15
xorl %edx, %edx #31.15
movl -4+cmp_$SKEYS.0.1(,%r12,4), %eax #31.15
cmpl -4+cmp_$PKEYS.0.1(,%rbx,4), %eax #31.15
setg %dl #31.15
addl %edx, %ebx #32.15
xorl $1, %edx #33.29
addl %edx, %r12d #33.15
cmpl $100, %ebx #30.28
jg ..B1.10 # Prob 18% #30.28
# LOE r13 r14 r15 ecx ebx esi edi r12d
..B1.8: # Preds ..B1.7
# Execution count [4.31e+06]
cmpl $100, %r12d #30.49
jle ..B1.7 # Prob 99% #30.49
# LOE r13 r14 r15 ecx ebx esi edi r12d
..B1.10: # Preds ..B1.7 ..B1.8
# Execution count [1.00e+06]
The code runs approx 15% faster than before. However, this is still far slower (almost 5x) than the code generated by 14.0.1 for the explicit if-else (see the first assembly snippet from my first comment).
I am not particularly interested to make this code fast per se as I can always rearrange the algorithm and get fast code on the 18.0.2.
However I was curious that this seemingly ordinary piece of code from my original post raises two issues, at least for the processor I am using:
a) ifort 18.0.2 generates significantly slower code than 14.0.1 (more than 3x slower)
b) For ifort 18.0.2. the -OO option gives the best performance among all the optimization levels (approx 25% faster)
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>The code runs approx 15% faster than before. However, this is still far slower (almost 5x) than the code generated by 14.0.1 for the explicit if-else (see the first assembly snippet from my first comment).
The 5x difference seems implausible (note, I am not saying this isn't happening).
Questions:
Your sample code has no timing code. How are you doing the timing? How long are the test runs?.
The 5x difference can occur when:
a) you time the runtime from the command line and the runtime of the test code is so short that the time to load the program swamps the runtime of the timed loop.
b) What you see in the source code, isn't what is run (IOW not run) due to compiler optimizations eliminating the code or precompiling the end result at compile time.
c) data is not naturally aligned (I doubt this is the case)
d) The loop requires more TLB entries than fit in TLB cache (I doubt this is the case)
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
I am using linux time command. The original program runs in half a second, I have added a couple of zeroes in the number of iterations (NITER) to make it run longer. The big difference in the runtimes remains.
code using ieor compiled with 18.0.2
time ./cmp_ieor_18l
0 1 101
30.273u 0.000s 0:30.28 99.9% 0+0k 1576+0io 1pf+0w
code using if-else compiled with 14.0.1
time ./cmp_14l
0 1 101
6.314u 0.000s 0:06.32 99.8% 0+0k 1360+0io 1pf+0w
Have tried to force the alignment to 64-byte using
!dir$ attributes align: 64:: skeys
!dir$ attributes align: 64:: pkeys
but that does not make any difference as far as I can see.
b) What you see in the source code, isn't what is run (IOW not run) due to compiler optimizations eliminating the code or precompiling the end result at compile time.
What I see in the generated assembly though isn't it the one that will finally run?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Can you run VTune on the fast code and on the one without the branches?
?? I think I see the difference:
In the fast code, only the index that is modified (either icnt or ikey) is tested for advancing past limit.
in the slow codes, both icnt and ikey are tested.
This looks like an optimization opportunity lost during version update.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Please see my comment #3 above where I have attached the results of Vtune profiling for the slow and fast codes.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi gn164,
The VTune information in #3 is just the summary. What you need to do to investigate this is to look at the Bottom-Up view, open the source (only source) with the highest counts, then click on the Disassembly (Assembly) button. This will show you an assembler listing inclusive of the counts for each instruction. This is more useful in determining performance bottlenecks.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
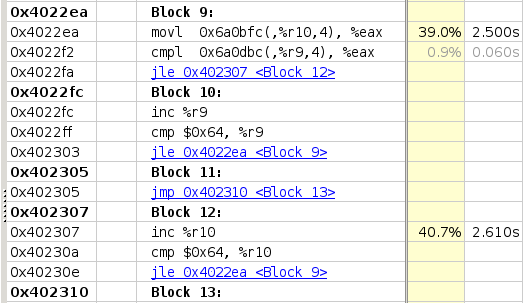
Hi Jim,
Please see attached the vtune profiling on the assembly for the fast and slow codes.
To reiterate:
Fast = Original version using if-else compiled with 14.0.1
Slow = Version using ieor compiled with 18.0.2 (or 14.0.1 it gives the same code)
I think that this confirms that in the fast code, only one index is evaluated whereas in the slow case much more instructions exist on the critical path.
Apart from this though, I also see that in the slow version much more time is spent in that cmpl instruction that I do not understand.
Is there a dependency to the movsxd instruction above?
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This (post #1 code) is definitely a good candidate for the compiler optimization team.
Also, post #16, the slow code is unnecessarily performing sign extension due to ineffective choice/use of ModRM and SIB instruction bytes. Also something for the compiler optimization team to look at.
You might be able to get the performance back with this:
program cmp parameter (NITER = 1000000) parameter (NDIM = 100) integer skeys(NDIM) integer pkeys(NDIM) integer i, cmpcnt skeys = 0 pkeys = 1 cmpcnt = 0 do i = 1 , NITER ikey = 1 icnt = 1 do if (skeys(icnt) .gt. pkeys(ikey)) then ikey = ikey + 1 if(ikey .le. NDIM) cycle else icnt = icnt + 1 if(icnt .le. NDIM) cycle endif exit enddo cmpcnt = cmpcnt + ikey / icnt enddo print *, cmpcnt end program
Note, this may produce similar code to the assembler code in #1.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Also, in the above sample code, performance will differ depending on the initial values of skeys and pkeys (i.e. when the if(skeys... is preponderantly is true as opposed to false).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
Thanks for this. The latest code does bring back the performance and both compilers now generate code similar to the fast assembler code in #1.
Also I can confirm that the performance is better if the branch condition is preponderantly true as opposed to false.
I would be curious why this is the case BTW?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In the true case, the loop has one branch at the cycle.
In the false case, the loop has two branches, one to the else and one at the cycle.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
This untested code might be slightly faster:
program cmp parameter (NITER = 1000000) parameter (NDIM = 100) integer skeys(NDIM) integer pkeys(NDIM) integer i, j, cmpcnt skeys = 0 pkeys = 1 cmpcnt = 0 do i = 1 , NITER ikey = 1 icnt = 1 do do j = 0,NDIM - max(icnt,ikey) if (skeys(icnt) .gt. pkeys(ikey)) then ikey = ikey + 1 cycle endif icnt = icnt + 1 end do if(ikey .gt. NDIM) exit if(icnt .gt. NDIM) exit end do cmpcnt = cmpcnt + ikey / icnt enddo print *, cmpcnt end program
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page