- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have written a fluid mechanics code in Fortran 90 and have been using
Intel's vtune amplifier to explore the performance of the code and ways
to improve the optimization. I have two versions of the code, each
exploring a different way to decompose the spatial domain, but both
codes perform the same computations.
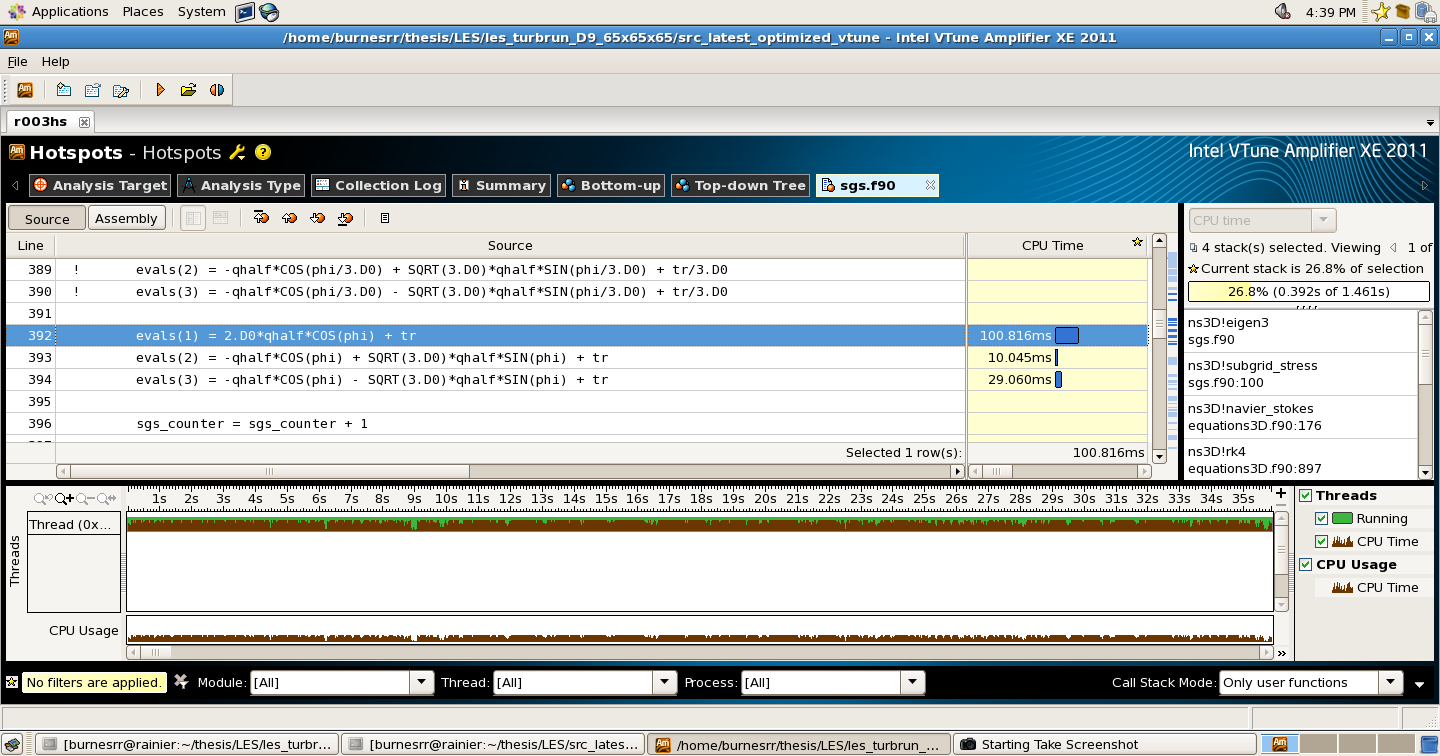
I am finding that in one version of the code I am taking a very large performance hit on one line of code that incorporates a cosine calculation. Both versions of the code execute this particular line of code approximately 4.3 million times during the simulation. In one version of the code, 46.47 seconds are accumulated executing this line and in the other version, 100.8 milli-seconds are accumulated executing this line of code. Please note that these numbers are for a single-processor calculation - no domain decomposition is present in the calculations presented here.
I have included two screenshots from vtune, showing the line of code in-question from each version of the code. For those who don't want to download the png screenshots the code line is:
evals(1) = 2.D0*qhalf*COS(phi) + tr
The version of the Intel Fortran Linux compiler I am using is:
Intel Fortran Compiler XE for applications running on IA-32, Version 12.0.2.137 Build 20110112
The compiler flags I am using for both versions of the code are:
-fast -g -c -opt-report 3 -opt-report-file ns3D.opt -vec-report3 -fno-inline -I/opt/intel/lib/ia32/libimf.so
I would greatly appreciate any insight that can be given to understand why such a large performance difference exists in these two cases and also what I can do to change the substantial performance hit I am taking in the code version that spends so much time executing this one line of code.
Sincerely,
Rick
I am finding that in one version of the code I am taking a very large performance hit on one line of code that incorporates a cosine calculation. Both versions of the code execute this particular line of code approximately 4.3 million times during the simulation. In one version of the code, 46.47 seconds are accumulated executing this line and in the other version, 100.8 milli-seconds are accumulated executing this line of code. Please note that these numbers are for a single-processor calculation - no domain decomposition is present in the calculations presented here.
I have included two screenshots from vtune, showing the line of code in-question from each version of the code. For those who don't want to download the png screenshots the code line is:
evals(1) = 2.D0*qhalf*COS(phi) + tr
The version of the Intel Fortran Linux compiler I am using is:
Intel Fortran Compiler XE for applications running on IA-32, Version 12.0.2.137 Build 20110112
The compiler flags I am using for both versions of the code are:
-fast -g -c -opt-report 3 -opt-report-file ns3D.opt -vec-report3 -fno-inline -I/opt/intel/lib/ia32/libimf.so
I would greatly appreciate any insight that can be given to understand why such a large performance difference exists in these two cases and also what I can do to change the substantial performance hit I am taking in the code version that spends so much time executing this one line of code.
Sincerely,
Rick
{kind=link}
{kind=link}
Link Copied
2 Replies
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What are the variable types in your statement:
evals(1) = 2.D0*qhalf*COS(phi) + tr
Are you mixing REAL(4) and REAL(8) variable types?
Jim Dempsey
evals(1) = 2.D0*qhalf*COS(phi) + tr
Are you mixing REAL(4) and REAL(8) variable types?
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Without seeing the actual code, there is insufficient information. If I had to guess based on what you have told us, I'd posit that in the 100ms case the compiler decided to optimize away the calculation and perhaps the entire loop. I would suggest enabling the optimization reports and seeing what is reported for the section of code in question.
Reply
Topic Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page