- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
i have an image of 1.5GB which i would like to scale down by Super interpolation, on Intel(R) Xeon(R) CPU E5-2460 v3 @ 2.66Ghz (2 processors) 32 cores and memory of 128 GB.
Using Intel 2019 and 2020, i see that the more threads i use, the slower it takes to scale down using Super interpolation. While testing it on ippiu8-5.2.dll (i don't which Intel it is...) i get faster performance when i use more threads. The problem doesn't exist for Cubic interpolation. It works as expected.
The sample below shows the performance time to scale down image of 1.5GB with Super interpolation by factor of 0.27 using different number of threads. Each case was tested 3 times:
Using Intel 2019 and 2020:
threads = 4, time=842 ms, threads = 4, time=670 ms, threads = 4, time=655 ms
threads = 8, time=718 ms, threads = 8, time=718 ms, threads = 8, time=749 ms
threads = 16, time=967 ms, threads = 16, time=920 ms, threads = 16, time=921 ms
threads = 24, time=1201 ms, threads = 24, time=1092 ms, threads = 24, time=1170 ms
.Using old version of Intel (ippu8-5.2.dll):
threads = 4, time=1092 ms, threads = 4, time=1123 ms, threads = 4, time=1092 ms
threads = 8, time=577 ms, threads = 8, time=562 ms, threads = 8, time=562 ms
threads = 16, time=375 ms, threads = 16, time=375 ms, threads = 16, time=374 ms
threads = 24, time=249 ms, threads = 24, time=249 ms, threads = 24, time=265 ms
Any solution to get better results when using more threads in Intel 2019 and 2020 for Resize Super Interpolation?
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, the internal threading has been removed from this function ( partially because the API has been changed since v5.2) and you try to take the IPP Threading Layer which allows making the external threading for ippiResizeSuper*.* functions.
Please check the existing examples show how to make such calls from the ipproot\examples\components\interfaces\tl\tl\ippi\ folder.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Gennady,
thanks for your reply.
I haven't checked the link you sent me below yet, but please note that using cubic interpolation works as expected. See below time performance according to number of threads for Cubic interpolation:
image size=1.51 GB
yScale=0.27 (scale down by 3.70) Intel Version=2019
threads = 4, time=577 ms
threads = 8, time=312 ms
threads = 16, time=343 ms
threads = 24, time=250 ms
The performance time is faster when you have more threads.
Could it be that internal threading model is different between Cubic and Super (ippiResizeCubic and ippiResizeSuper)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Yes, there is some inconsistency that we have with these functions. The cubic case is threaded, the supersampling - not and into the current version of IPP, there is only one choice to scale this solution by using the Threading Layer or in other words, by threaded this call externally.
In the case, if you like to see the internal threading of this function- please open the Feature Request issue into Intel Online Service Center which is the official support channel.
Gennady
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gennady,
we might misunderstood each other.
Currently, i parallel the the resize . Each thread gets its own roi in the image to scale down. Same code runs for Cubic interpolation and for Super interpolation. Meaning, i thread the code externally.
(for example, if i have 4 threads then i divide the image to for 4 parts. if image is 1000 rows then each thread will run on 250 rows, one for rows 1-250, second for 251-500, and etc...).
However, the more threads i run the faster i get for Cubic and slower for Super.
Running same threads model as described above for ippi 5-2 works as expected.
You wrote that "The cubic case is threaded, the supersampling - not..." - do you mean that ippiResize for Cubic internally parallel the scale down although i parallel the scale down externally? If yes, it means if i run external 4 threads in Cubic mode then actually more threads are running, doesn't it?
And ippiResize for Super doesn't have the internal parallel mechanism of scale down?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dudi,
Could you give us the reproducer to check the behavior?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gennady,
i uploaded test sample that shows the problem. The test application ask which Intel to use 5.2 or 2019 and scale down the image. You can set number of threads for example 4;8;16;24 and the test will scale down and measure the time for 4 threads, then 8 threads and etc...
The test application remembers the values of the parameters that you ran before, it displays them in brackets, so you can just press Enter to keep the values you want to use.
The application uses parallel_for and divide the image to parts so each thread works on this own part in the image.
Note please to scale down 24bit color image with size 1.5GB . Scale down please with a float number like 0.27. You can see that if you scale down by by integer value (for example 0.25 which is sclae down by 4 or 0.4 for scale down by 2) you get different time performance.
You can can see that using Intel 2019 is slower for Super interpolation for float value (like 0.27) to scale-down as long number of threads increases, whereas it works better in Intel 5.2.
The test application upload as well Intel binary files of 5.2 and 2019. They are located in x64\Debug and x64\release folder.
Download the sample. You can run the executable or compile it as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dudi,
thanks, we will check the problem on our side and keep this thread inform with updates.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Please note that i checked it on Intel(R) Xeon(R) CPU E5-2460 v3 @ 2.66Ghz (2 processors) 32 cores and memory of 128 GB. Don't forget to check it on big images like 1.5GB.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dudi,
Thanks for the information, we are looking into your example.
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dudi,
One of characteristics of the Super Sampling Resize algorithm implemented in the latest IPP versions is that it requires additional memory which amount depends on 1 / GCD (SRC HEIGHT, DST HEIGHT). Unfortunately, in your case GCD for almost each piece is 1 that requires about the same total amount of additional memory as original image. This is preventing effective parallelism. We suggest you not to divide your image into sub-images and process each one as separate image but initialize Resize for the whole image and apply it to sub-images. You can find example of such approach in IPP documentation, “Resizing a Tiled Image with One Prior Initialization”. This may significantly reduce amount of additionally required memory and improve effectiveness of parallelism. In attachment you can find this approach applied to your reproducer.
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vladislav,
thanks for your reply and for the modification you did in my reproduce sample.
I tested it again and i found out still it is far away slower than Intel 5.2.
You can also see from the table below that the modifications you did is not always faster than the code while using Version 1 as argument to the test application.
You can see the processing time for Cubic and Super by number of threads. The title "Intel 2019 after fix" is using the code that you modified.
The test was done on same image of 1.5GB and on the same computer that has 32 cores.
| Super Processing time in ms | |||
| Intel 2019 after fix | Intel 2019 before fix | Intel 5.2 | #threads |
| 905 | 687 | 796 | 4 |
| 734 | 624 | 422 | 8 |
| 780 | 811 | 312 | 16 |
| 827 | 1045 | 218 | 24 |
| Cubic Processing time in ms | |||
| Intel 2019 after fix | Intel 2019 before fix | Intel 5.2 | #threads |
| 218 | 234 | 296 | 4 |
| 218 | 94 | 218 | 8 |
| 234 | 93 | 234 | 16 |
| 156 | 109 | 172 | 24 |
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dudi,
Could you please share the exact dimensions in pixels of original 1.5GB image?
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Width is 23040 pixels and Height is 23504 pixels
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks, Dudi. I'll check this size on our side.
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vladislav,
Do you have any update for me?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dudi,
The problem is that your scheme of splitting image to chunks and scaling ratio not optimal for IPP 2019 SuperSampling algorithm, the more threads you have the more additional memory is required at a time and more stalls happen. Now I'm looking for more optimal scheme to split the image and reduce memory usage. Will notify you on updates.
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the reply.
However, what has been change vs Intel 5.2? Same scheme of splitting image to chunks and scaling ratio is tested for Intel 5.2 and results are by far better than 2019.
Could you please describe what has been change?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The difference between IPP 5.2 and IPP 2019 is that IPP 2019 SuperSampling requires additional memory buffer that gives significant speed up in single-threaded environment. The size of this additional buffer is inversely proportional to GCD (source height, destination height), the more GCD the less memory is needed. In the worst case of GCD=1 the size of this buffer is close to source image chunk under resizing. In your case almost all chunks have GCD=1. I suppose that the more threads you have the more simultaneous read/write accesses to additional buffers (and to source and destination images) are requested but not all requested memory is available in CPU cashes because of size.
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Dudi,
Here is the modified reproducer with new scheme to split the image. Now it splits destination image to 27 rows chunks, source image to 100 rows chunks (for 0.27 ratio) and redistributes chunks uniformly across threads. The benefit of this approach is that one additional buffer is used and it is reused between the chunks within one thread. Here are the additional memory consumptions for original scheme and new scheme:
| num threads | Old scheme (MB) | New scheme (MB) |
| 4 | 1060.11 | 28.57 |
| 8 | 1360.27 | 57.15 |
| 16 | 1673.72 | 114.29 |
| 24 | 1673.91 | 171.44 |
Could you please try this new example?
Best regards,
Vlad V.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Vlad,
thanks for your efforts.
it seems much better and acceptable.
it seems that there is no much processing time difference when number of threads is greater than 8 (see table below). I also added test for 1 thread as well.
Nevertheless, it seems fine. I will do more tests and let you know if i find something weird...

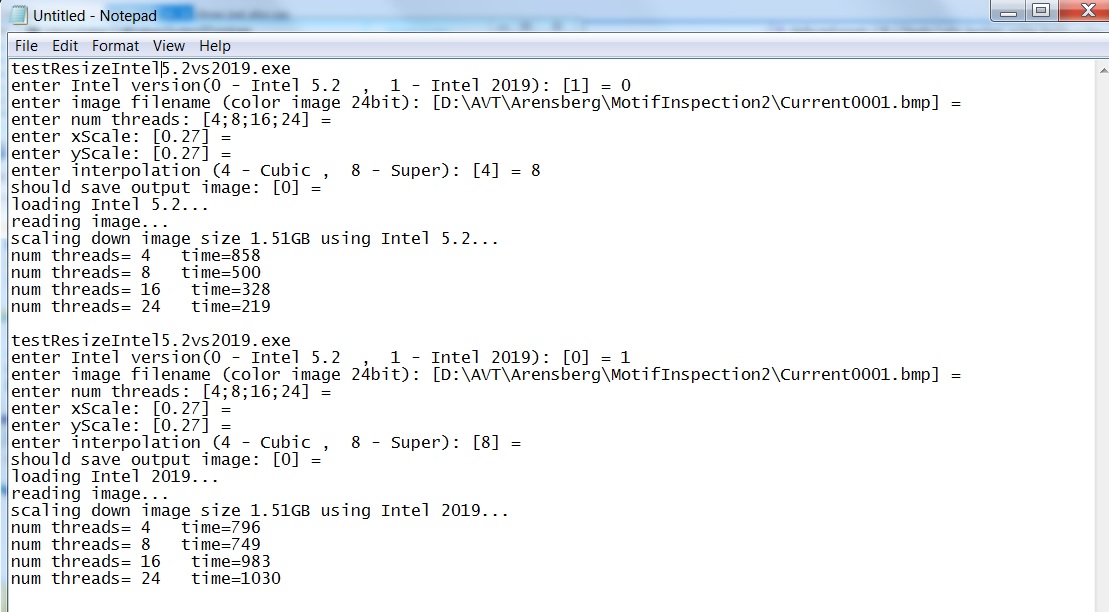{kind=link}
Thanks,
Dudi
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page