- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Deat Intel developers,
I'm using AVX whit Intel 15.0.1 compiler. I need to load some float shifted by one in order to do some AVX operations:
sample = traces.r + traces .r[j+1];
At the moment, I do two distinct AVX load:
intr_1= _mm256_load_ps(&traces.r ); intr_2= _mm256_load_ps(&traces .r[j+1]);
In this way, I calculate sample in two distinct vectorized phase, first part for J and second part for J+1. It works, but it is quiet slow. In fact, using the second load, I load seven elements I already have and just one new element. So, maybe I can do a sort of load, and left shift and finally a second load of one elements. What is the best strategy? Thanks in advance.
- Tags:
- Parallel Computing
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Your method with unaligned loads is probably satisfactory for current CPU architecture (Haswell or newer). For Sandy Bridge, unaligned load will be intolerably slow, so you may want to consider permitting your compiler to choose the method, if you don't like to write in _mm128 loads to be combined by _mm256_insertf128_ps. AVX2 permutes appear better suited to your suggestion about shifts, but then you shouldn't be seeing such poor performance of unaligned load.
Ivy Bridge was designed specifically to alleviate the penalty incurred by unaligned mm256 loads.
The question seems more topical for https://software.intel.com/en-us/forums/intel-isa-extensions, but there is limited appeal in struggling with low level intrinsics code to optimize for an old ISA. After all, there is "moderncode" in the title of this forum.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Tim,
I'm using Sandy Bridge andy my load are aligned (traces is 32 bytes aligned by using mm_malloc). But I've noted no differences between aligned or unaligned load.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If traces
_mm256_load_ps(&traces
_mm256_load_ps(&traces
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It is almost always better to reload the data than to use the permute functions, even with the cache-line-crossing and page-crossing penalties on Sandy Bridge. It is possible to make the page-crossing cases run faster by using permute, but it is a lot of effort to generate special versions for all possible alignments.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
With avx load, performance varies with data alignment but not whether aligned or unaligned intrinsic is issued. mm128 loads may not lose performance with misalignment.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
jimdempseyatthecove wrote:
If traces
.r[0] is aligned to 32-bytes, then _mm256_load_ps(&traces
.r[0]) is aligned load of r[0], r[1],... r[7] and
_mm256_load_ps(&traces.r[1]) is unaligned, a split load of r[1],... r[7] and then r[8]. Jim Dempsey
Hi Jim, this is true, in fact, I do a manual unroll of step 8:
for(j,........, j+=8) {
_mm256_load_ps(&traces.r)
_mm256_load_ps(&traces.r[j+1])
}
I have for each iteration one load aligned and one not. How can I do to have all load aligned?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I think it would be more productive for you and the responders to see a larger picture of what you are trying to do.
From the little of what you have shown, you last post contains too little of what you are trying to do for any of us to offer productive advice. We do not see the outputs. IOW, are you producing a vector, one element shorter than the input where each output elements has each element the sum of the adjacent input vector? Or are you intending to perform a sum reduction (sum of all elements in the input vector)? Or something entirely different. If the first case, is the output vector the input vector, if so, can this be made to different output vector?
To answer your question, sketch out what you are asking:
cache lines |0123456789ABCDEF|0123456789ABCDEF|0123456789ABCDEF|... j=0 _mm256 01234567 | | j+1 _mm256 01234567 | | j=8 _mm256 01234567| | j+1 _mm256 0123456|7 | j=16 _mm256 |01234567 | j+1 _mm256 | 01234567 | ...
Where | is the cache line interval. When mod(j,16)==0 then j+1 is within the same cache line as j, however, when mod(j,16)==8, then j+1 will cross cache line.
Good advice for the narrow scope is likely to provide bad advice for the larger scope.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Jim,
thanks for the explanations. I post more source code to explain better my goal:
for(n = *begin_ntrace; n < *end_ntrace; n++) {
r_idx = tt;
i_idx1 = (int)r_idx;
i_idx2 = i_idx1 + dms;
for(j = i_idx1, k = 0; j < i_idx2; j++, k++) {
sample.r = traces.r + traces.r[j+1];
sample.i = traces.i + traces.i[j+1];
num.r += sample.r;
num.i += sample.i;
}
}
where appears j and j+1 memory access.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Sorry, I misread the posted code as nested loops, seemingly implying a sum reduction. I'm concerned about writing source code with multiple variables in the for() field not only due to this possibility of misreading, but also an account of needing to always read compiler reports to see the effect. If you happen to be compiling in 32-bit mode, it's of utmost importance that the compiler combine multiple pointer references into a single indexing register with offsets. A confirmation of vectorization would be sufficient to indicate this has happened, but use of simd intrinsics may obscure it.
As you have mentioned the hope that keeping the duplicate memory references at register level might boost performance, I would like to mention that this seems most likely to work for data in L1 cache, when you might be coming up against the Sandy Bridge limit of 2 128-bit reads and 1 128-bit store to L1 cache per clock cycle. If your data runs are long enough to go to memory, the combining effect of last level cache and read stream buffers should prevent repeated memory references from absorbing memory bandwidth.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
TimP,
This isn't a sum reduction, it is more like a raster (or bin) accumulation. The output isn't a scalar sum, rather it is a vector of sums of vectors (a vector and its +1 neighbor).
What is a representative value for dms? IOW what is a representative trip count for the inner loop?
Do you have a pattern for i_idx1 for each n? IOW is it always a multiple of some number or is it somewhat random?
A major inhibitor of vectorization for the above code is the output array num as being a structure. It would be better if you made two arrays, and accumulated as
for(n = *begin_ntrace; n < *end_ntrace; n++) {
r_idx = tt;
i_idx1 = (int)r_idx;
i_idx2 = i_idx1 + dms;
for(j = i_idx1, k = 0; j < i_idx2; j++, k++) {
num_r += traces.r + traces.r[j+1]; // vector of r to vector of r
num_i += traces.i + traces.i[j+1]; // vector of i to vector of i
}
}
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
And if need be, follow the above with:
for(k=0; k<dms; ++k) {
num.r = num_r;
num.i = num_i;
}
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
jimdempseyatthecove wrote:
TimP,
This isn't a sum reduction, it is more like a raster (or bin) accumulation. The output isn't a scalar sum, rather it is a vector of sums of vectors (a vector and its +1 neighbor).
jimdempseyatthecove wrote:
What is a representative value for dms? IOW what is a representative trip count for the inner loop?
Typical value of dms is from 10 to 30 and around this.
jimdempseyatthecove wrote:
Do you have a pattern for i_idx1 for each n? IOW is it always a multiple of some number or is it somewhat random?
Unfortunately not, no pattern are associated to i_idx1. Typical trip count is about 20. It is very small loop called many and many times inside a function.
jimdempseyatthecove wrote:
A major inhibitor of vectorization for the above code is the output array num as being a structure. It would be better if you made two arrays, and accumulated as
for(n = *begin_ntrace; n < *end_ntrace; n++) { r_idx = tt; i_idx1 = (int)r_idx; i_idx2 = i_idx1 + dms; for(j = i_idx1, k = 0; j < i_idx2; j++, k++) { num_r += traces .r + traces .r[j+1]; // vector of r to vector of r num_i += traces .i + traces .i[j+1]; // vector of i to vector of i } } Jim Dempsey
Thanks Jim, I'll try it.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't have all of the numbers handy, but if I recall correctly the Sandy Bridge core pays a 3 cycle penalty for 256-bit loads that cross a cache line boundary and a 1-cycle penalty for 128-bit loads that cross a cache line boundary. So you definitely don't want 256-bit loads in this case.
It is not obvious to me whether you will be better off with (128-bit loads/stores and 128-bit arithmetic) or with (128-bit loads/stores and 256-bit arithmetic). There will probably not be a lot of difference in this case -- the execution time should be limited by the loads and stores, with plenty of time to fully overlap the arithmetic instruction execution.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
jimdempseyatthecove wrote:
And if need be, follow the above with:
for(k=0; k<dms; ++k) { num.r = num_r ; num .i = num_i ; } Jim Dempsey
Hi Jim,
using your suggestion, code is about 15% faster.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
That is a good start.
Next adventure for you is to run the release code under VTune, not necessarily to find the bottlenecks (at this time). Instead, use Bottom Up listing, find the function, then open the Assembly window.
You do not need to fully understand the Assembly instruction syntax. You just need to understand some simple rules:
a) In the source window, highlight the lines of interest (e.g. the for(j= loop in post #11, select/highlight lines 5:8)
b) Locate the highlighted lines in the Assembly window (you may need to sort by source line number by clicking on the "Line" header in the Assembly window).
c) Assess the number of assembly instructions, after a few of these exercizes you will get a feel of "too many" or "about right". One of the issues that can arrise is loop invarient code not getting moved out of the loop. For this loop, you would expect the compiler to locate "num_r", "num_i", "traces.r" and "traces.i" into registers. If you see memory fetches (those with "ptr [...]" then these addresses are not registerized. If the inner loop does not have the array addresses registerized, then you may need to add within the "for(n=" loop, scoped restrict pointers to those arrays, code to use them, VTune and examine Assembly again.
d) While one can use the vectorization report, I prefer to see the Assembly to see if there is "efficient" vectorization. In this case you are looking for the xmm or ymm instructions (xmm is 128 bit, ymm is 256 bit). Note, John McCalpin pointed out that on some CPU's 128 bit can be faster. And more importantly the instructions end in ...ps or ...pd for floating point (packed single, packed double), or are of the form v... or p... for integer.
After you get the instruction count down to "about right", then you can look at the metrics offered by VTune to see if there is something else you can learn. For example, if you are building x32 applications, you have a limited number of registers available. If the for(j= loop runs out of registers, it may have to load the array addresses from memory. In this situation, making two loops, one for r and one for i, may be faster. On x64, the register usage on the for(j= should not be an issue (verify this assumption by looking at the assembly code).
You do not need to the the Assembly checkout for all code, just your few hot spots.
Last note:
It has been my experience that when you manage to wipe out a hot spot (making the loops run multiples of times faster), that you almost always fine a now new hot spot that didn't seem all that important before. Therefore, expect to iterate working away at a series of new hot spots.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
BTW for
for(j = i_idx1, k = 0; j < i_idx2; j++, k++) {
num_r += traces.r + traces.r[j+1]; // vector of r to vector of r
num_i += traces.i + traces.i[j+1]; // vector of i to vector of i
}
You would expect to see 6 "... ptr[...]" instructions (4 reads, 2 writes). Though you may see double this if the compiler unrolled it once (or multiples with higher unroll count).
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
jimdempseyatthecove wrote:
That is a good start.
Next adventure for you is to run the release code under VTune, not necessarily to find the bottlenecks (at this time). Instead, use Bottom Up listing, find the function, then open the Assembly window.
You do not need to fully understand the Assembly instruction syntax. You just need to understand some simple rules:
a) In the source window, highlight the lines of interest (e.g. the for(j= loop in post #11, select/highlight lines 5:8)
b) Locate the highlighted lines in the Assembly window (you may need to sort by source line number by clicking on the "Line" header in the Assembly window).
c) Assess the number of assembly instructions, after a few of these exercizes you will get a feel of "too many" or "about right". One of the issues that can arrise is loop invarient code not getting moved out of the loop. For this loop, you would expect the compiler to locate "num_r", "num_i", "traces.r" and "traces.i" into registers. If you see memory fetches (those with "ptr [...]" then these addresses are not registerized. If the inner loop does not have the array addresses registerized, then you may need to add within the "for(n=" loop, scoped restrict pointers to those arrays, code to use them, VTune and examine Assembly again.
d) While one can use the vectorization report, I prefer to see the Assembly to see if there is "efficient" vectorization. In this case you are looking for the xmm or ymm instructions (xmm is 128 bit, ymm is 256 bit). Note, John McCalpin pointed out that on some CPU's 128 bit can be faster. And more importantly the instructions end in ...ps or ...pd for floating point (packed single, packed double), or are of the form v... or p... for integer.After you get the instruction count down to "about right", then you can look at the metrics offered by VTune to see if there is something else you can learn. For example, if you are building x32 applications, you have a limited number of registers available. If the for(j= loop runs out of registers, it may have to load the array addresses from memory. In this situation, making two loops, one for r and one for i, may be faster. On x64, the register usage on the for(j= should not be an issue (verify this assumption by looking at the assembly code).
You do not need to the the Assembly checkout for all code, just your few hot spots.
Last note:
It has been my experience that when you manage to wipe out a hot spot (making the loops run multiples of times faster), that you almost always fine a now new hot spot that didn't seem all that important before. Therefore, expect to iterate working away at a series of new hot spots.
Jim Dempsey
Hi Jim
I attach the assembly from VTune. From what I understand, there are some values not registerized so I tried this code by using restrict ponters:
float * restrict num_rp = &num_r[0];
float * restrict num_ip = &num_i[0];
float * restrict traces_rp = &traces.r[i_idx1];
float * restrict traces_ip = &traces.i[i_idx1];
for(j = i_idx1, k = 0; j < i_idx2; j++, k++) {
*num_rp = *num_rp + (1.0f-up_interp)*(*traces_rp) + up_interp*(*(traces_rp+1));
*num_ip = *num_ip + (1.0f-up_interp)*(*traces_ip) + up_interp*(*(traces_ip+1));
num_rp++;
num_ip++;
traces_rp++;
traces_ip++;
}
but I obtained no performance gain.
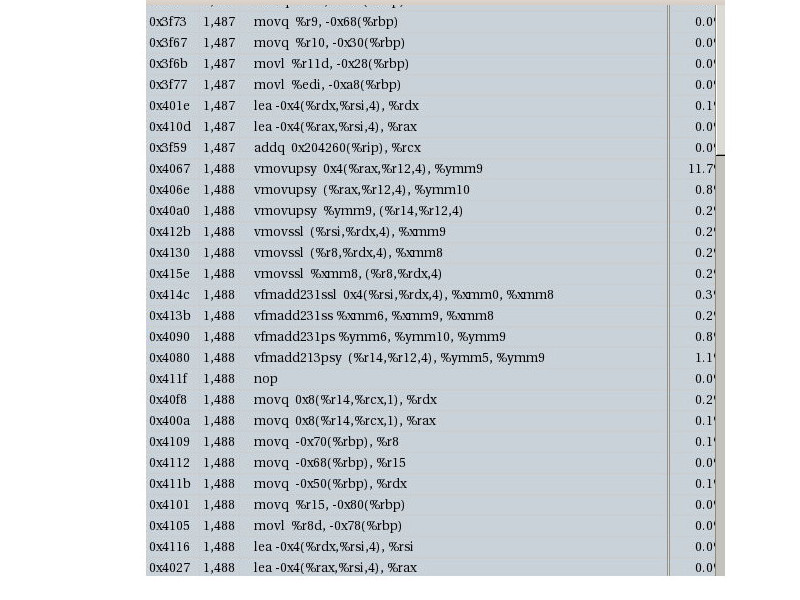{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It's hard to read from your screen shots; I would think that saving asm code and finding the hot loops might be easier. From what I can see, it does seem that the compiler may not have combined your pointers into loop carried register variables; as you appear to need 6 integer or pointer registers, failure to perform such combination would prevent optimization for 32-bit mode, where at most 3 such registers are available. Avoiding this trap appears to be among the advantages, besides readability, of array indexing notation num_rp
Intel C++ has a habit anyway of failing to optimize where there are too many of those post-increments at the bottom of the loop.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
The compiler usually generates much better code using subscripted restrict pointes as opposed to pointer++, besides, incrementing one index register is faster than indexing 4 pointers. Use this:
float * restrict num_rp = &num_r[0]; float * restrict num_ip = &num_i[0]; float * restrict traces_rp = &traces.r[i_idx1]; float * restrict traces_ip = &traces .i[i_idx1]; int i_iter = i_idx2 - i_idx1 + 1; // # iterations // *** use loop control variable and index that is scoped inside the for loop for(int k = 0; k < i_itr; k++) { num_rp = num_rp + (1.0f-up_interp)*(traces_rp ) + up_interp*traces_rp[k+1]; num_ip = num_ip + (1.0f-up_interp)*(traces_ip ) + up_interp*traces_ip[k+1]; }
On 32-bit system, the above should require 4 registers for your float*'s and 1 register each for i_iter and k for a total of 6 GP registers.
If the above does not fully registerize (usually due to the compiler thinking something outside the scope of what shown above is more important) then enclose the above in {...}. Yes, this do would appear to be meaningless, however, the meaning is that the 4 float*'s and the variable i_iter are disposable (not used outside the scope). This can improve register usage, especially on x32 builds.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
FWIW, the IA32 instruction set (as well as Intel64), has the capability of SIB (Scale, Index, Base)
Meaning for traces_rp[k+1] requires only 1 instruction to fetch or store or to use as one of the add/sub/div instructions.
In the above, the instruction would contain "0x04(%rBase, $rIndex, 4)" as either the source or destination of an instruction.
By using the pointer++ (4 times), you are complicating the issue.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page