I am doing an OpenCL project of vector multiplication of VecA (M * 1) and VecB (1 * N) which produces a matrix MatC (M * N). I want to use a fan-out design which can support a 2-D processing engine array. Can I go like this to infer fan-our? :
https://alteraforum.com/forum/attachment.php?attachmentid=14222&stc=1 __kernel void matMult() { ...... # pragma unroll for(int x = 0; x < M; x++) {# pragma unroll for(int y = 0; y < N; y++) { MatC[x][y] += VecA[x] * VecB[y]; } } ...... } Any advice would be much appreciated!!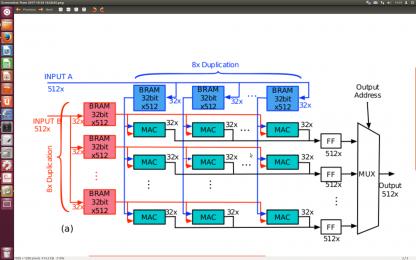{kind=link}
链接已复制
You can achieve this type of systolic array design using the autorun kernel type and num_compute_units (Section 2.3 and 2.4 of Intel FPGA SDK for OpenCL Programming Guide). However, I would expect the same thing to be also achievable in a single kernel using loop unrolling, where the local memory buffers are automatically replicated by the compiler.
Hi, I tried the systolic array and it takes massive amount of BRAM and registesr (mostly for control overhead) which causes my design to be severely memory-bounded. But if I do the fan-out design, the way I unroll the loop cannot work out, it produces wrong output in hardware run. Do you have any idea how the loops should be unrolled?
--- Quote Start --- There are some small code snippets in Altera's documents in the sections I mentioned above, but other than that, I do not know of any other public code showing the systolic array design. --- Quote End --- Intel's FPGA systolic array example is a controlled material(using public code may not able to get best performance as not optimized for FPGA), and in the event user wish to have a copy that need to contact Altera representative separately. Regards, CloseCL (This message was posted on behalf of Intel Corporation)