- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Windows 10
IDE
Visual Studio 19
Compiler
Intel(R) oneAPI DPC++ compiler
Toolkit
oneAPI Base Toolkit version 2021.1
Problem
- Random call instructions are generated in critical loops when using parallel_for.
- No loop optimization is applied when using single_task.
Example program,
#include <CL/sycl.hpp>
#include <iostream>
namespace {
__declspec(noinline) void add(
float const* a, size_t a_stride,
float const* b, size_t b_stride,
float* c, size_t c_stride,
size_t w, size_t h
) {
for (size_t y = 0; y < h; ++y) {
for (size_t x = 0; x < w; ++x) {
c[y * c_stride + x] = a[y * a_stride + x] + b[y * b_stride + x];
}
}
}
__declspec(noinline) void add_single_task(
sycl::queue& q,
float const* a, size_t a_stride,
float const* b, size_t b_stride,
float* c, size_t c_stride,
size_t w, size_t h
) {
auto e = q.submit([&](sycl::handler& cgh) {
cgh.single_task([=]() {
for (size_t y = 0; y < h; ++y) {
for (size_t x = 0; x < w; ++x) {
c[y * c_stride + x] = a[y * a_stride + x] + b[y * b_stride + x];
}
}
});
});
e.wait_and_throw();
}
__declspec(noinline) void add_parallel_for(
sycl::queue& q,
float const* a, size_t a_stride,
float const* b, size_t b_stride,
float* c, size_t c_stride,
size_t w, size_t h
) {
auto e = q.submit([&](sycl::handler& cgh) {
cgh.parallel_for(sycl::range<2>(h, w), [=](sycl::id<2> index) {
auto y = index[0];
auto x = index[1];
c[y * c_stride + x] = a[y * a_stride + x] + b[y * b_stride + x];
});
});
e.wait_and_throw();
}
sycl::queue get_queue() {
// Note:
// Initialization of a queue is very slow.
// Hence, we'll be caching it.
static auto q = sycl::queue(sycl::cpu_selector());
return q;
}
} // namespace
int main(int argc, char* argv[]) {
try {
auto q = get_queue();
}
catch (std::exception const& e) {
std::cout << "Queue initialization failed with " << e.what() << '\n';
return -1;
}
try {
constexpr auto w = size_t(1024);
constexpr auto h = size_t(1024);
auto a = std::vector<float>(w * h, 1);
auto b = std::vector<float>(w * h, 2);
auto c = std::vector<float>(w * h);
auto q = get_queue();
for (size_t i = 0; i < 30; ++i) {
add(a.data(), w, b.data(), w, c.data(), w, w, h);
add_single_task(q, a.data(), w, b.data(), w, c.data(), w, w, h);
add_parallel_for(q, a.data(), w, b.data(), w, c.data(), w, w, h);
}
}
catch (std::exception const& e) {
std::cout << "Add failed with " << e.what() << '\n';
return -1;
}
return 0;
}
Intel Advisor reports,
- add_parallel_for,
- call tree,
- assembly, - add_single_task,
- source insights,



Are those call instructions necessary and is there a way to request the AOT/JIT compiler to not generate them? And for single_task, shouldn't optimization be applied as well (was simply interested to see how it fare against the host compiler optimization, add)?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for sharing!
/Zi tells the compiler to generate full debugging information and call instructions are generated when it enabled. Without this option, there are no callq instructions. Please, note that /Zi is not recommended to use in the release code. So, this is not a bug.
Also, please, note that O0-O3 options are also supported by dpcpp \ icx compilers as well.
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for reaching out to us!
We are escalating this thread to the Subject Matter Expert(SME) who will guide you further.
Have a Good day
Thanks & Regards
Goutham
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I reproduced the second issue (No loop optimization is applied when using single_task). Since this is a missed performance opportunity, I suppose it might be escalated as a feature request. I am presently investigating it and will get back to you shortly with an update.
However, I wasn't able to reproduce callq inside add_parallel_for. Could you please share the compiler options you used? Which compiler driver, dpcpp or icx\icpx, did you use?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Using default settings on release mode in Visual Studio.
/O2 which should translate to -O3 by clang-cl.
Was reproducible in,
-
Intel(R) Core(TM) i5-7300HQ
-
Intel(R) Xeon(R) Gold 6230N
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
If it's still not reproducible, try removing the add inside main, leaving only add_single_task and add_parallel_for.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
No, it is not reproducible, even with O3. Could you please share a compiler command line and other steps to reproduce?
What do you mean by 'which should translate to -O3 by clang-cl'?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Steps:
- Create a new project, select Empty Project.
- Change Platform Toolset from Visual Studio 2019 (v142) to Intel(R) oneAPI DPC++ Compiler.
- Change x86 to x64 and Debug to Release.
- Paste the script and build.
* DPC++ Console Application template project should work too (without having to go through steps 1 and 2).
For reference, these are the arguments passed to the compiler.
/O2 /Zi /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /WX- /MD /EHsc /W1 /nologo /Fo"x64\Release\"
As to "which should translate to -O3 by clang-cl", as seen above, I'm using /O2 which is a msvc option, not a gcc/clang option. However, clang-cl should translate it to -O3.
I have also attached a zipped file which contains the project and executable along with Intel Advisor's report.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for sharing!
/Zi tells the compiler to generate full debugging information and call instructions are generated when it enabled. Without this option, there are no callq instructions. Please, note that /Zi is not recommended to use in the release code. So, this is not a bug.
Also, please, note that O0-O3 options are also supported by dpcpp \ icx compilers as well.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Yes, that works.
And the generated assembly is much much better, see attached image.
Finally, is there any way to use intel loop directives FPGA loop directives for a CPU/GPU kernel, like [[intel::invdep]]?
Using the same example, c[y * c_stride + x] = a[y * a_stride + x] + b[y * b_stride + x], I believe the optimizer detects possible memory aliasing here (y * stride), and disables other loop transformations, like loop unrolling, permutation, tiling, etc.
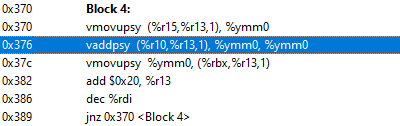{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi,
Thanks for the confirmation!
As this issue has been resolved, we will no longer respond to this thread.
If you require any additional assistance from Intel, please start a new thread.
Any further interaction in this thread will be considered community only.
Have a Good day.
Thanks & Regards
Goutham
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page