- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello everyone!
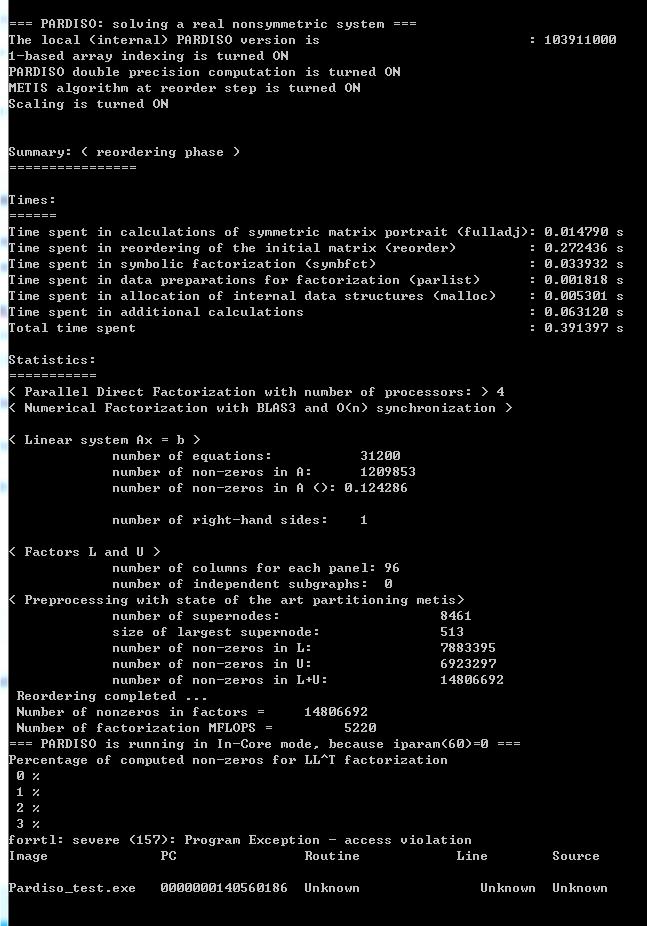
I am a PhD student in Computational Mechanic, and now I am using MKL Pardiso to solve large unsymmetric sparse matrix in my FEM codes. When I want to build a 64bit version application, a fatal error comes out "forrt1: severe(157) Program Exception-Access Violation".
The compiler and library I use are Intel Fortran Compiler and MKL in Intel Composer XE2013, and the IDE is Microsoft Visual Studio 2012.
I use Configuration Manager to change the platform 32bit or 64bit. I link MKL with my code automatically through selecting "Parallel" in Project properties(Fortran->Libraries->Use Intel Math Kernel Library: Parallel).
I directly use the pardiso_symm_f90.f90 file in MKL examples. The confusion I encounter is that when I use original data, like a, ia, ja, b, both 32bit and 64bit application can successfully executed. However, when I use my own data (I input a, ia, ja, b by reading disk files), 32bit application runs successfully with no error. But when I built 64bit application, it gives me the fatal error-Access Violation.
The error window captured picture, the code and relevant data are attached.
Actually, I have gone through almost all the relevant topics about this problem, unfortunately I don't find the solution!
Can anyone help me with this problem? Thanks very much in advance.
Regards,
Eric
Thanks again!
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have resolved this problem by updating my Intel Composer XE 2013 to 2018. So I guess this maybe relevant to the old version of MKL.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
thanks for keeping thread updated.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Gennady F. (Blackbelt) wrote:thanks for keeping thread updated.
Thanks for your comment. Now I have a new problem on Pardiso. Instead of opening a new topic, I write it here. Hope you can give me suggestions.
I want to use Pardiso solver in my nonlinear FEM code. As we know, Pardiso adopts CSR format matrix to calcuate, and it is very efficient. However, converting dense representation of sparse matrix to the CSR matrix is very slow (my stiffness matrix is a size of 50K*50K), even calling the MKL function like mkl_ddnscrs(). So I wonder if there is another way to assembly the global stiffness matrix in CSR format. Another bottleneck is that because of nonlinear problem, the global stiffness matrix needs to be updated each iterative step.
Thanks in advance!
Eric
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Eric,
First, I am surprised to see that you're assembling a matrix from FEM in a dense format. Typically, all FEM software use an element-wise assembly and compute the stiffness matrix already in a sparse format. And CSR is often the format of choice since it is very common. So, I would think about why you're creating a dense matrix in the first place. Which FEM software are you using? If you writing your own, what's the idea behind it?
Second, for converting a dense matrix into a sparse matrix, I'd suggest not using a deprecated mkl_ddnscrs but rather write your own, parallel version of such a conversion routine. You can do it in a straightforward way by splitting your dense matrix by rows between threads (assuming you're using OpenMP) and doing computations in several phases.
Also, how many nonzeros do you have in your matrix? 50k by 50k sparse matrix is considered to be tiny and hence PARDISO should be pretty fast for solving the system.
Third, speaking of improving the performance, you need first to identify if it is really a problem in your case. Is it a bottleneck for solving the problem, e.g. disallowing you to refine the mesh the way you want or someting of that sort? Premature optimization can take a lot of time and lead you away from a less technical part of the problem.
Fourth, there are multiple ways you can be clever when using PARDISO for solving a nonlinear problem. It would help if you proide more details. Does the structure of the matrix remains the same? If not, do you know which part is changing on each step, is it within a fixed subset of a matrix? Do you kniow from the underlying physics who drastically the matrix is changing? Based on the answers, we can recommend options for PARDISO to try.
I hope some of this is useful.
Best,
Kirill
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Voronin, Kirill (Intel) wrote:Hello Eric,
First, I am surprised to see that you're assembling a matrix from FEM in a dense format. Typically, all FEM software use an element-wise assembly and compute the stiffness matrix already in a sparse format. And CSR is often the format of choice since it is very common. So, I would think about why you're creating a dense matrix in the first place. Which FEM software are you using? If you writing your own, what's the idea behind it?
Second, for converting a dense matrix into a sparse matrix, I'd suggest not using a deprecated mkl_ddnscrs but rather write your own, parallel version of such a conversion routine. You can do it in a straightforward way by splitting your dense matrix by rows between threads (assuming you're using OpenMP) and doing computations in several phases.
Also, how many nonzeros do you have in your matrix? 50k by 50k sparse matrix is considered to be tiny and hence PARDISO should be pretty fast for solving the system.
Third, speaking of improving the performance, you need first to identify if it is really a problem in your case. Is it a bottleneck for solving the problem, e.g. disallowing you to refine the mesh the way you want or someting of that sort? Premature optimization can take a lot of time and lead you away from a less technical part of the problem.
Fourth, there are multiple ways you can be clever when using PARDISO for solving a nonlinear problem. It would help if you proide more details. Does the structure of the matrix remains the same? If not, do you know which part is changing on each step, is it within a fixed subset of a matrix? Do you kniow from the underlying physics who drastically the matrix is changing? Based on the answers, we can recommend options for PARDISO to try.
I hope some of this is useful.
Best,
Kirill
Hello Kirill,
Thanks for your detailed comment.
Actually I am new to FEM, and as you said, now I realize it's truly silly to assembly stiffness matrix in a dense format. I will try to directly assembly stiffness matrix in CSR format. Could you give me some suggestions on the efficient and robust algorithm to assembly stiffness matrix in CSR format?
I also determine to use the Arc length method to solve my nonlinear problem, so the symmetry and banded properties of the stiffness matrix can be kept.
Thanks again for your valuable and detailed comment.
Best Regards,
Eric
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page