- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Hi All,
I'm evaluating the performance (this time not MKL6 vs MKL11) of MKL11 with 1 thread versus 4 threads.
The 4 thread version seems to be slower. Furthermore, the 4 thread implementation has a huge number of outliners. Does anyone have any explanations, why?
Below the source (float and double are similar), I shortened it for better overview.
Main function:
int _tmain(int argc, _TCHAR* argv[])
{
int threads = 4; //or 1
mkl_set_num_threads(threads);SetPriorityClass(GetCurrentProcess(), HIGH_PRIORITY_CLASS ); // Set a process priority to 'High'
TEST FUNCTION HERE
SetPriorityClass( GetCurrentProcess(), NORMAL_PRIORITY_CLASS ); // Restore the process priority to 'Norma'l
}
TEST FUNCTION
DFTI_DESCRIPTOR_HANDLE hand;
cxdTimeLoops.alloc(loops);
// FLOAT
k=0;
for (exp=exp_start;exp<=exp_stop;exp++)
{
Nfft = (unsigned int) pow(2.0,exp);
myRndNumber = 1; //seed
for (i=0;i<Nfft;i++) //get pseudo random signal
{
myRndNumber = NextRand32(myRndNumber);
cxfTimesig = ((float) myRndNumber / UINT_MAX)*2-1;
cxfTimeaxis = ((float) i + 1.0) / fs;
}
hand = 0;
status = DftiCreateDescriptor(&hand, DFTI_SINGLE, DFTI_REAL, 1, Nfft);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiCommitDescriptor(hand);
for (i=0;i<loops;i++)
{
hpfcTimer.Start(); //start timer for single execution
status = DftiComputeForward(hand, cxfTimesig.ptr(), cxfFreqsig.ptr());
cxdTimeLoops = hpfcTimer.Time();
}
DftiFreeDescriptor(&hand);
dTimeMax = 0;
dTimeMin = cxdTimeLoops[0];
dTimeAvg = 0;
for (i=0;i<loops;i++)
{
dTimeAvg += cxdTimeLoops;
dTimeMax = max(cxdTimeLoops,dTimeMax);
dTimeMin = min(cxdTimeLoops,dTimeMin);
}
dTimeAvg /= (double) loops;
k++;
}
// DOUBLE
k=0;
for (exp=exp_start;exp<=exp_stop;exp++)
{
Nfft = (unsigned int) pow(2.0,exp);
cxdFreqsig.alloc(Nfft);
cxdTimesig.alloc(Nfft);
cxdTimeaxis.alloc(Nfft);
myRndNumber = 1; //seed
for (i=0;i<Nfft;i++) //get pseudo random signal
{
myRndNumber = NextRand32(myRndNumber);
cxdTimesig = ((double) myRndNumber / UINT_MAX)*2-1;
cxdTimeaxis = ((double) i + 1.0) / fs;
}
hand = 0;
status = DftiCreateDescriptor(&hand, DFTI_DOUBLE, DFTI_REAL, 1, Nfft);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiCommitDescriptor(hand);
for (i=0;i<loops;i++)
{
hpfcTimer.Start(); //start timer for single execution
status = DftiComputeForward(hand, cxdTimesig.ptr(), cxdFreqsig.ptr());
cxdTimeLoops = hpfcTimer.Time();
}
DftiFreeDescriptor(&hand);
dTimeMax = 0;
dTimeMin = cxdTimeLoops[0];
dTimeAvg = 0;
for (i=0;i<loops;i++)
{
dTimeAvg += cxdTimeLoops;
dTimeMax = max(cxdTimeLoops,dTimeMax);
dTimeMin = min(cxdTimeLoops,dTimeMin);
}
dTimeAvg /= (double) loops;
k++;
}
}
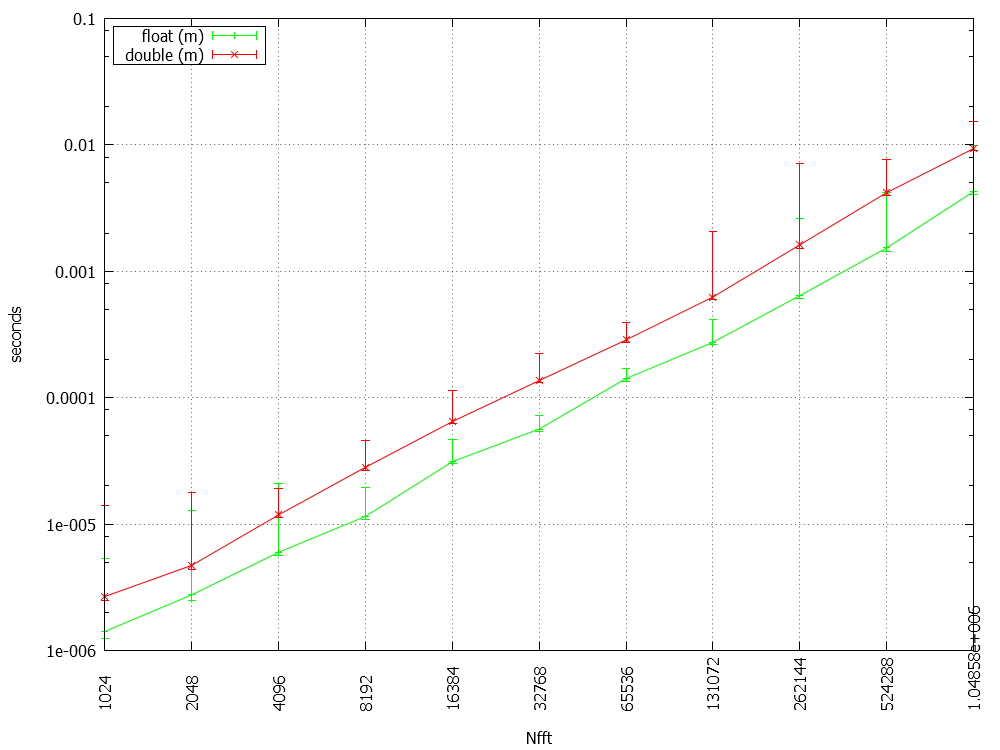
dTimeAvg is plottet versus Nfft for float and double. I'm attaching the individual plots with min/max for visualizing the outliners.
Thanks, Marian
{kind=link}
{kind=link}
{kind=link}
링크가 복사됨
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Marian,
can you please give me your machine/processor specifications? Do you observe this in every machine?
- Sridevi
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
@Sridevi: It's an Inten Core i5-2500@3.30 GHz, 8 GB RAM. I've only checked this on this computer.
@Sergey: Would you wrap the priority raising around the for loop like this:
//Set to high priority
for (i=0;i<loops;i++)
{
hpfcTimer.Start(); //start timer for single execution
status = DftiComputeForward(hand, cxfTimesig.ptr(), cxfFreqsig.ptr());
cxdTimeLoops = hpfcTimer.Time();
}//Set to normal priority
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Hi,
You measure FFT performance on powers of two sizes in a range [exp_start, exp_stop] for real-to-complex.
What they are? You know, small sizes have always sequential implementation.
To check that MKL implementation is threaded please set environment KMP_AFFINITY=compact,verbose and be sure you linked with MKL threaded libraries.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Hi,
Setting high-priority may not help and used just for getting performance stability on overloaded machine.
However, you can initialize OMP-threads in your program easily with required priority before using MKL functions:
#pragma omp parallel
{
SetThreadPriority( GetCurrentThread(),THREAD_PRIORITY_HIGHEST);
}
so that MKL will use these theads doing parallel FFTs.
BTW, how many real CPUs are on your machine. And what about HT (hyper-threading)?
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
@Victor:
What they are? You know, small sizes have always sequential implementation.
The FFT length is written in the absissa, so the exponent runs from 10 to 20.
BTW, how many real CPUs are on your machine. And what about HT (hyper-threading)?
Intel Core i5-2500@3.30 GHz, according to this it has no hyper threading
SetThreadPriority( GetCurrentThread(),THREAD_PRIORITY_HIGHEST);
Sadly, that does not change the performance significantly.
@Sergey:
>>SetPriorityClass( GetCurrentProcess(), HIGH_PRIORITY_CLASS );
Did you try to comment that?
Yes, but it sets the priority of the whole process, not threads. So the placement should be irrelevant, correct?
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
@marian
Before running your tests can you measure overall sytem load?I would suggest to do it with xperf tool.There is possibility that your threads are preempted by code which is running at high IRQL(like driver's routines).As it was suggested in other post by Sergey it is recommended to disable some of the unneded windows services and even disable some of the hardware loke network cards.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
@ iliyapolak: Thanks for your comment. If the performance is not good with my system, it is very likely the same on a customer's computer. I agree it could be some driver or something else. But I can't go into details of the root cause here, because I don't know what is on other systems, that I cannot control.
@Sergey, I'll send you a pm.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
>>>I see that in Marian's case a real practical investigation is really needed what is going on with MKL v11. It is clear that performance has degraded compared to older versions of MKL.>>>
As far as it concerns performance of some program/software at the beginning of the investigation you cannot exclude anything.I completely agree with you that any software developer should not care about the IRQL's and driver's routines,but in the case of software performance problems everything must be taken into account even system load.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
@Marian
I was not talking about the other system.Testing your code on another machine is important to understand the root cause.Regarding the problem I believe that sometimes you software performance can degrade because of interference from the OS (it's services) and the other code maybe more priviledged one.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Marian,
The best time observed by the benchmark scales (decreases with the number of threads) but this best time is dominated by instability of measurement.
Here are some tips to stabilize measurements.
- Pin threads to CPU cores using the KMP_AFFINITY environment varibale or the Windows API for thread affinity
- Ensure the benchmark single-threaded; if your use-case is multi-threadedm you may want to look through http://software.intel.com/en-us/articles/different-parallelization-techniques-and-intel-mkl-fft
- Prevent the cache warm-up time from dominating your performance measurement -- either increase the value of the loops variable in your code, or exclude from measurement the first call to DftiComputeForward for each Nfft.
Please let us know if the above tips help.
Thanks,
Evgueni.
- 신규로 표시
- 북마크
- 구독
- 소거
- RSS 피드 구독
- 강조
- 인쇄
- 부적절한 컨텐트 신고
Marian,
The best time observed by the benchmark scales (decreases with the number of threads) but this best time is dominated by instability of measurement.
Here are some tips to stabilize measurements.
- Pin threads to CPU cores using the KMP_AFFINITY environment varibale or the Windows API for thread affinity
- Ensure the benchmark single-threaded; if your use-case is multi-threadedm you may want to look through http://software.intel.com/en-us/articles/different-parallelization-techniques-and-intel-mkl-fft
- Prevent the cache warm-up time from dominating your performance measurement -- either increase the value of the loops variable in your code, or exclude from measurement the first call to DftiComputeForward for each Nfft.
Please let us know if the above tips help.
Thanks,
Evgueni.