- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
I'm evaluating the performance (this time not MKL6 vs MKL11) of MKL11 with 1 thread versus 4 threads.
The 4 thread version seems to be slower. Furthermore, the 4 thread implementation has a huge number of outliners. Does anyone have any explanations, why?
Below the source (float and double are similar), I shortened it for better overview.
Main function:
int _tmain(int argc, _TCHAR* argv[])
{
int threads = 4; //or 1
mkl_set_num_threads(threads);SetPriorityClass(GetCurrentProcess(), HIGH_PRIORITY_CLASS ); // Set a process priority to 'High'
TEST FUNCTION HERE
SetPriorityClass( GetCurrentProcess(), NORMAL_PRIORITY_CLASS ); // Restore the process priority to 'Norma'l
}
TEST FUNCTION
DFTI_DESCRIPTOR_HANDLE hand;
cxdTimeLoops.alloc(loops);
// FLOAT
k=0;
for (exp=exp_start;exp<=exp_stop;exp++)
{
Nfft = (unsigned int) pow(2.0,exp);
myRndNumber = 1; //seed
for (i=0;i<Nfft;i++) //get pseudo random signal
{
myRndNumber = NextRand32(myRndNumber);
cxfTimesig = ((float) myRndNumber / UINT_MAX)*2-1;
cxfTimeaxis = ((float) i + 1.0) / fs;
}
hand = 0;
status = DftiCreateDescriptor(&hand, DFTI_SINGLE, DFTI_REAL, 1, Nfft);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiCommitDescriptor(hand);
for (i=0;i<loops;i++)
{
hpfcTimer.Start(); //start timer for single execution
status = DftiComputeForward(hand, cxfTimesig.ptr(), cxfFreqsig.ptr());
cxdTimeLoops = hpfcTimer.Time();
}
DftiFreeDescriptor(&hand);
dTimeMax = 0;
dTimeMin = cxdTimeLoops[0];
dTimeAvg = 0;
for (i=0;i<loops;i++)
{
dTimeAvg += cxdTimeLoops;
dTimeMax = max(cxdTimeLoops,dTimeMax);
dTimeMin = min(cxdTimeLoops,dTimeMin);
}
dTimeAvg /= (double) loops;
k++;
}
// DOUBLE
k=0;
for (exp=exp_start;exp<=exp_stop;exp++)
{
Nfft = (unsigned int) pow(2.0,exp);
cxdFreqsig.alloc(Nfft);
cxdTimesig.alloc(Nfft);
cxdTimeaxis.alloc(Nfft);
myRndNumber = 1; //seed
for (i=0;i<Nfft;i++) //get pseudo random signal
{
myRndNumber = NextRand32(myRndNumber);
cxdTimesig = ((double) myRndNumber / UINT_MAX)*2-1;
cxdTimeaxis = ((double) i + 1.0) / fs;
}
hand = 0;
status = DftiCreateDescriptor(&hand, DFTI_DOUBLE, DFTI_REAL, 1, Nfft);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiCommitDescriptor(hand);
for (i=0;i<loops;i++)
{
hpfcTimer.Start(); //start timer for single execution
status = DftiComputeForward(hand, cxdTimesig.ptr(), cxdFreqsig.ptr());
cxdTimeLoops = hpfcTimer.Time();
}
DftiFreeDescriptor(&hand);
dTimeMax = 0;
dTimeMin = cxdTimeLoops[0];
dTimeAvg = 0;
for (i=0;i<loops;i++)
{
dTimeAvg += cxdTimeLoops;
dTimeMax = max(cxdTimeLoops,dTimeMax);
dTimeMin = min(cxdTimeLoops,dTimeMin);
}
dTimeAvg /= (double) loops;
k++;
}
}
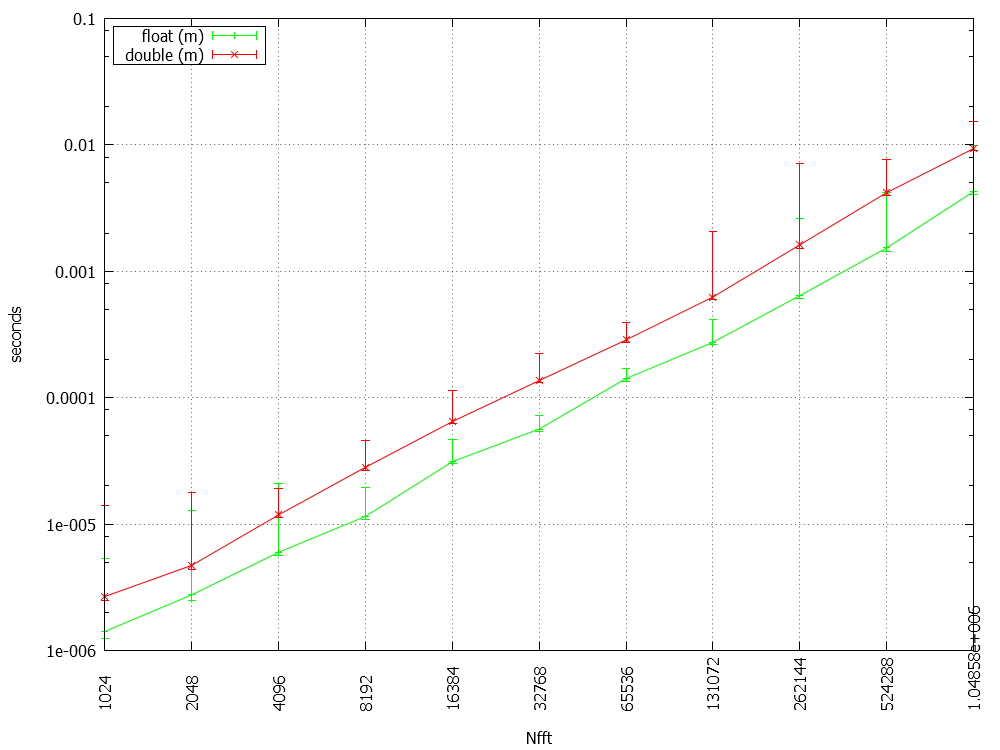
dTimeAvg is plottet versus Nfft for float and double. I'm attaching the individual plots with min/max for visualizing the outliners.
Thanks, Marian
{kind=link}
{kind=link}
{kind=link}
Link Copied
- « Previous
-
- 1
- 2
- Next »
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Marian,
The best time observed by the benchmark scales (decreases with the number of threads), but the average time is dominated by instability of measurement.
Here are some tips to stabilize measurements.
- Pin threads to CPU cores using the KMP_AFFINITY environment varibale or the Windows API for thread affinity
- Ensure the benchmark is single-threaded; if your use-case is multi-threaded, you may want to look through http://software.intel.com/en-us/articles/different-parallelization-techniques-and-intel-mkl-fft
- Prevent the cache warm-up time from dominating your performance measurement -- either increase the value of the loops variable in your code, or exclude from measurement the first call to DftiComputeForward for each Nfft.
Please let us know if the above tips help.
Thanks,
Evgueni.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you all for the comments. I will try to do it before the evaluation period runs out.
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page
- « Previous
-
- 1
- 2
- Next »