- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi All,
I'm currently evaluating MKL11 to decide, if it should replace the older MKL6, that is used till now. I wrote a little console application to compare the FFT performance (for the moment just the computation time, not the numerical exactness), but the results rather suprised me, the MKL11 seems to be slower than MKL6.
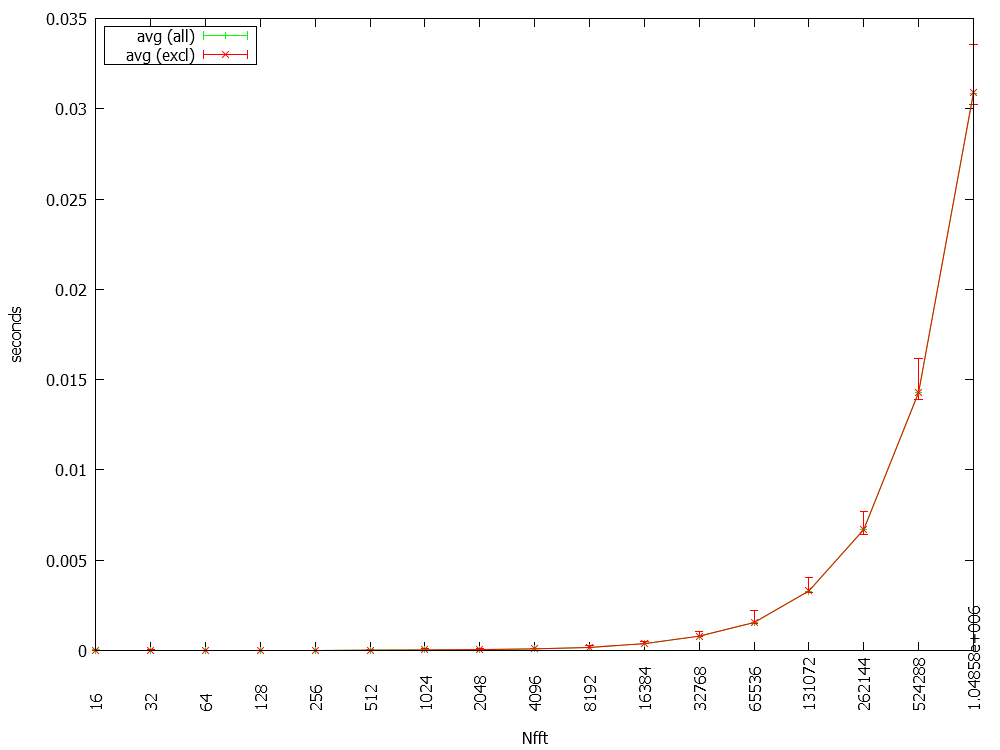
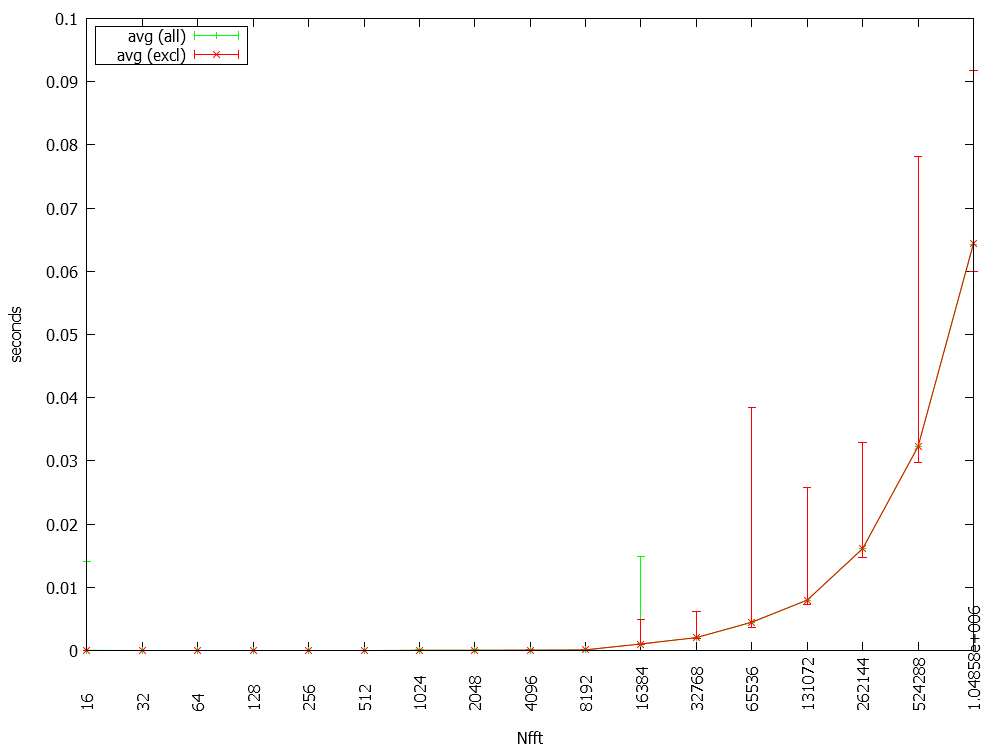
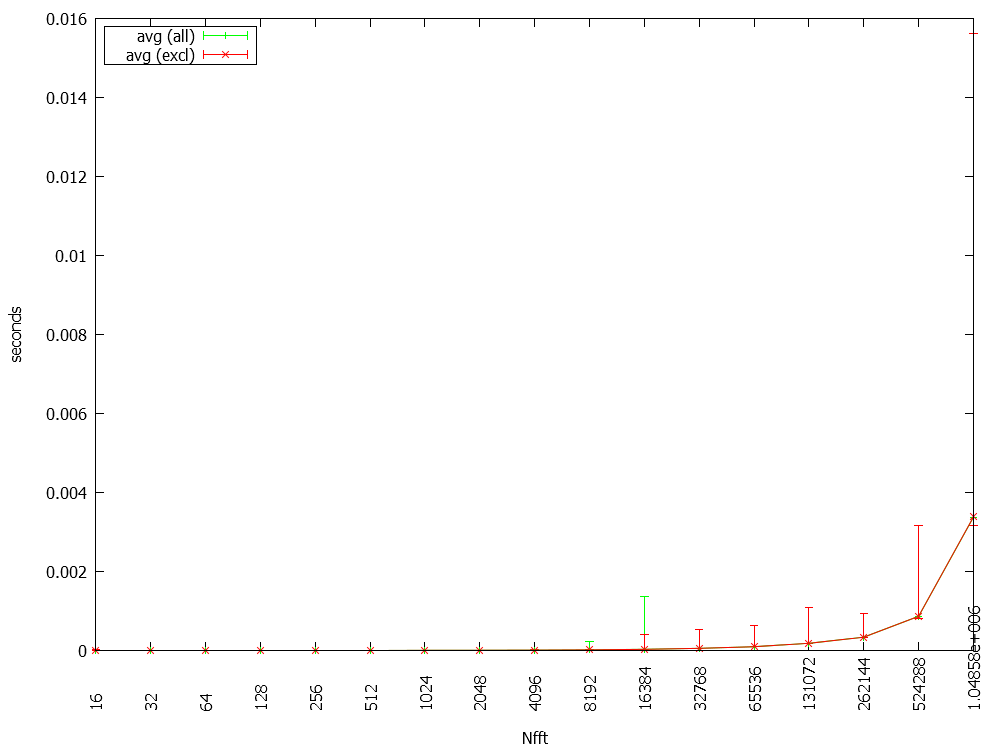
The program runs 1100 FFTs with different lengths and measures the time. The attached plots show avg/min/max plots of 1100 loops (green). The red curves excluded the first 100 loops from the logging - no big difference there. The time is for each FFT calculation.
Plotting both average curves shows, that the MKL6 needs approximately half the time.
I was a bit surprised by these results - does anyone have experience on the FFT performance? Another thing that keeps me wondering are the outliners in the MKL11, that don't occur that much with MKL6.
My testing code:
int FFT_Kernel_float(unsigned int Nfft, void* pIn, void* pOut)
{
int status;
DFTI_DESCRIPTOR_HANDLE hand = 0;
status = DftiCreateDescriptor(&hand, DFTI_SINGLE, DFTI_REAL, 1, Nfft);
status = DftiSetValue(hand, DFTI_PLACEMENT, DFTI_NOT_INPLACE);
status = DftiCommitDescriptor(hand);
status = DftiComputeForward(hand, pIn, pOut);
DftiFreeDescriptor(&hand);
return status;
}
for (exp=exponent_start;exp<=exponent_stop;exp++) //2^4 to 2^20
{
Nfft = (unsigned int) pow(2.0,exp);
cxfTimesig.alloc(Nfft);
cxfTimeaxis.alloc(Nfft);
cxfFreqsig.alloc(Nfft);
for (i=0;i<Nfft;i++)
{
cxfTimeaxis = ((float) i + 1.0) / fs;
cxfTimesig = ((float)rnd.Get()/UINT_MAX)*2-1; //random signal
}
Time_all_min = 1e6;
Time_all_max = 0;
Time_firstexcl_min = 1e6;
Time_firstexcl_max = 0;
hpfcAllLoops.Start(); //start time for all loops
for (i=0;i<loops;i++) //loops = 1100
{
if (i==exclude_first_from_avg-1)
hpfcFirstExcluded.Start(); //start timer for loops after first excluded loops
hpfcIndividual.Start(); //start timer for single execution
status = FFT_Kernel_float(Nfft,cxfTimesig.ptr(), cxfFreqsig.ptr());
Time_individual = hpfcIndividual.Time();
if (i>=exclude_first_from_avg-1) //exclude_first_from_avg = 100
{
Time_firstexcl_max = max(Time_firstexcl_max,Time_individual);
Time_firstexcl_min = min(Time_firstexcl_min,Time_individual);
}
Time_all_max = max(Time_all_max,Time_individual);
Time_all_min = min(Time_all_min,Time_individual);
}
Time_all_tot = hpfcAllLoops.Time();
Time_firstexcl_tot = hpfcFirstExcluded.Time();
Time_firstexcl_avg = Time_firstexcl_tot / (double) (loops - exclude_first_from_avg);
Time_all_avg = Time_all_tot / (double) loops;
//log data here
}
Any opinions or experiences on this issue?Am I comparing apples and oranges?
Marian
(Win7, Intel i5-2500, C++, Visual Studio 2008)
{kind=link}
{kind=link}
{kind=link}
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Marian,
this is the expected results because of you measure the time of the whole routine which includes creation, initialization of descriptor and etc....whithin these parts of FFT calculations we allocate memory for internal data and initialializing this data and etc... these procedures are not highly optimized. But usually this part of FFT is done one time only.
Please check the computation phase of FFT (in this case -- DftiComputeForward)
hpfcIndividual.Start(); //start timer for single execution
status = DftiComputeForward(hand, pIn, pOut);
Time_individual = hpfcIndividual.Time();
and let us know the results you will see.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Gennady,
thanks for your response. Indeed, the test you proposed yields a faster computation time of the MKL11.
Why is the allocation time slower now? I'm currently using a wrapper function (like in the code) for the FFT, do you recommend keeping the handle?
Do you have an explanation for the higher number of outliners in MKL11's results? The ratio seems relatively constant (compared to the outliners in MKL6's results).
Thanks!
{kind=link}
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Marian
Can you post the MKL FFT results for 4096 point FFT?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
thanks for the comments.
@iliyapolak: for Nfft=4096, the results for the second test (random signal with only DftiComputeForward)
(MKL11) avg:5.756583E-006 min:5.286975E-006 max:1.586093E-005 (seconds)
@Sergey Kostrov: Thank you very much for that input, I'll consider it next time
- Yes, you're right, that would improve determinism. Although, the number of loops proves the general trend. If I find the time, I'll do the test with a non-random signal.
- Correct, but the overhead is in both tests (version 6 and 11).
- The general trend is clear to me now. If it is not too much work I'd appreciate the example, though.
What I don't know is, why the complete wrapper function (including the allocations) is slower in the new version. Currently the whole software project uses such a wrapper function.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
@iliyapolak: for Nfft=4096, the results for the second test (random signal with only DftiComputeForward)
(MKL11) avg:5.756583E-006 min:5.286975E-006 max:1.586093E-005 (seconds)
Thanks for posting.
My results for 4096 FFT of sine function were approximately ~212145 nanoseconds.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I tend to raise the executing thread priority inside main() , where the tested function is called.Here is example of FFT on 4096 points data set
// FFT test-case Intel Compiler.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <math.h>
#include <Windows.h>
#include <tchar.h>
#define MAXITER10K 10000UL
#define DATA_SET_64 64
#define DATA_SET_128 128
#define DATA_SET_256 256
#define DATA_SET_512 512
#define DATA_SET_1024 1024
#define DATA_SET_2048 2048
#define DATA_SET_4096 4096
#define DATA_SET_8192 8192
#define DATA_SET_16384 16384
#define DATA_SET_32768 32768
#define SWAP(a,b) temp=(a);(a)=(b);(b)=temp
void fourier1(double data[],unsigned long nn, int isign);
int _tmain(int argc, _TCHAR* argv[])
{
DWORD error,thPriority;
BOOL bOK,bOK2;
double a = 0;
int i,q;
LONGLONG start,end;
const unsigned long MaxIter = 1e+6;
double test[DATA_SET_4096];
thPriority = GetThreadPriority(GetCurrentThread());
printf("current thread priority is 0x%x\n",thPriority);
bOK = SetThreadPriority(GetCurrentThread(),THREAD_PRIORITY_TIME_CRITICAL);
if(!bOK)
printf("failed to boost current thread priority (%d) \n",GetLastError());
else
printf("current thread priority after boost is 0x%x \n",GetThreadPriority(GetCurrentThread()));
srand((unsigned)time(NULL));
for( i = 0;i < DATA_SET_4096;i++){
a = (double)RAND_MAX/DATA_SET_4096;
test = (double)rand() /a;
}
//start = GetTickCount64();
//for(q = 0;q < MAXITER10K ;q++){
fourier1(test,DATA_SET_2048,1);
bOK2 = SetThreadPriority(GetCurrentThread(),THREAD_PRIORITY_NORMAL);
if(!bOK2)
printf("failed to lower priority to normal (%d) \n",GetLastError());
else
printf("thread priority returned to normal 0x%x \n",GetThreadPriority(GetCurrentThread()));
//}
//end = GetTickCount64();
/*printf("Intel compiler testcase start value is %ld msec\n",start);
printf("Intel compiler testcase end value is %ld msec\n",end);
printf("Intel compiler resulting overhead is %ld msec\n",(end-start));*/
for( i = 0;i < DATA_SET_4096;i++)printf("FFT test-case 1, fourier transform of _j0() = %.17f\n",test);
return 0;
}
void fourier1(double data[],unsigned long nn,int isign){
unsigned int start_lo,start_hi,time_lo,time_hi;
unsigned long n,mmax,m,j,istep,i;
double wtemp,wr,wpr,wpi,wi,theta,temp,tempi;
n = nn<<1;
j = 1;
_asm{
xor eax,eax
xor edx,edx
cpuid
rdtsc
mov start_lo,eax
mov start_hi,edx
}
for( i = 1;i < n;i += 2){
if(j < i){
SWAP(data
SWAP(data[j+1],data[i+1]);
}
m = n >> 1;
while(m >= 2 && j > m){
j -= m;
m >>= 1;
}
j+=m;
}
mmax = 2;
while(n > mmax){
istep=mmax << 1;
theta = isign*(6.28318530717959/mmax);
wtemp = sin(0.5*theta);
wpr = -2.0*wtemp*wtemp;
wpi = sin(theta);
wr = 1.0;
wi = 0.0;
for(m = 1;m < mmax;m+=2){
for(i = m;i<=n;i+=istep){
j = i+mmax;
temp = wr*data
tempi = wr*data[j+1]+wi*data
data
data[j+1] = data[i+1] - tempi;
data += temp;
data[i+1] += tempi;
}
wr = (wtemp=wr)*wpr-wi*wpi+wr;
wi = wi*wpr+wtemp*wpi+wi;
}
mmax = istep;
}
_asm{
xor eax,eax
xor edx,edx
cpuid
rdtsc
sub eax,start_lo
sub edx,start_hi
mov time_lo,eax
mov time_hi,edx
}
printf("%15s \n","[running time of fourier() function start_lo value ]:");
printf("%10d \n",start_lo);
printf("%15s \n","[running time of fourier() function start_hi value ]:");
printf("10d \n",start_hi);
printf("%15s \n","[ running time of fourier function end_lo value ]:");
printf("[ LoDelta ] = %10d \n",time_lo);
printf("%15s \n","[running time of fourier() function end_hi value ]:");
printf("[HiDelta ] = %10d \n",time_hi);
}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Sergey!
Do you think that raising thread's priority in main function just before the call to tested function has any significiance? Do I need to raise the thread's priority inside the tested function?
Thanks in advance,
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>>My statement is based on results of real tests completed on a computer system with Windows 2000 Professional OS ( 32-bit ) that simulates embedded system with just 128MB of memory.>>>
I did not perform any of my tests related to thread's priority on the system with only 128MB of RAM.Put it simply my arguments are based on "Windows Internals" book.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
>>>That depends on what you're trying to do, Iliya. Personally, I try to do it when all initializations are completed and main processing is ready to be started. I'll try to provide test results of some processing with 'Normal' and 'Real-Time' priorities>>>
Thanks for the answer.Later I will test my FFT function when the calls to thread priority API are made right after initialization and before main calculation loop.I will post the results.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page