- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I am doing a distributed Cholesky. You can find the code I am using (almost the same) here. I am gathering the submatrices (after every node has executed Cholesky) into the master node exactly as shown in this example. I am wondering if I can do better, by passing better parameters, especially for the block size, which may result in faster execution. I would like to know how I should think when it comes to the block size, so that I can tackle other matrices in the future.
Here is my current experiments, performed in only one machine (I will use more machines in the future):
Machine has 4 cores.
Matrix 755x755:
- 0.0085218 seconds (one process, no distribution). // 0.00859599 sec is the time of the actual linear version dpotrf()
- 0.0046682 seconds (block size = 30, 4 processes). Gather submatrices: 0.00306 seconds. Total time: 0.00793 seconds.
- 0.0047445 seconds (block size = 40, 4 processes). Gather submatrices: 0.00295 seconds. Total time: 0.00775 seconds.
- 0.0048543 seconds (block size = 50, 4 processes). Gather submatrices: 0.00275 seconds. Total time: 0.00757 seconds.
Matrix 1978x1978:
- 0.12831 seconds (one process, no distribution). // 0.128122 sec is the time of the actual linear version dpotrf()
- 0.05661 seconds (block size = 100, 4 processes). Gather submatrices: 0.01431 seconds. Total time: 0.07092 seconds.
- 0.05566 seconds (block size = 50, 4 processes). Gather submatrices: 0.01797 seconds. Total time: 0.07363 seconds.
- 0.05637 seconds (block size = 60, 4 processes). Gather submatrices: 0.01786 seconds. Total time: 0.07423 seconds.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georgios,
It is a good open question!
Block size do really impact the performance, from all kind of aspects: Hardware, memory size, cache size, problem size, rank size, algorithm itself etc.
For example, the below image i attached is how scalapack distributed data based on Block size to process node. the data exchange are time-consuming. So we perfer big block size, thus less data exchange, on the other hand, if too bigger block size, the task in each rank will have imblanance workload.
So for special problem, you may do experiment based on your hardware as you found.
Best Regards,
Ying
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georgios,
It is a good open question!
Block size do really impact the performance, from all kind of aspects: Hardware, memory size, cache size, problem size, rank size, algorithm itself etc.
For example, the below image i attached is how scalapack distributed data based on Block size to process node. the data exchange are time-consuming. So we perfer big block size, thus less data exchange, on the other hand, if too bigger block size, the task in each rank will have imblanance workload.
So for special problem, you may do experiment based on your hardware as you found.
Best Regards,
Ying
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ying,
thanks again for a good answer in this forum. Just for clarification to the future user, I would like to state, that in the picture of Ying, the block size is 1x1. The left is the original matrix, which shows which block goes to a process (colours specify the processes). The right subfigure, is the process grid (2x3) that gets formed, which shows how blocks and processes are partitioned. This is the result of the distribution. I mean that the left subfigure can be treated as the initial state, then distribution is happening (i.e. blocks are broadcast to processes) and the right subfigure is where the data are eventually sent.
Kind regards,
George
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi George,
It is great complements. Right, it is what i mean, how scapack function distribute matrix to 2x3 process grid. The figure is 2d block cyclic distribution model. You can take the block as 1x1 or bigger.
Regarding the block size, I heard from Aleksandr (our scalapack expert). He also did experiment and recommend to try multiply of 4 of 8. And observation that usually optimal block size is provided by local maximum of performance.
Example:

{kind=link}
{kind=link}
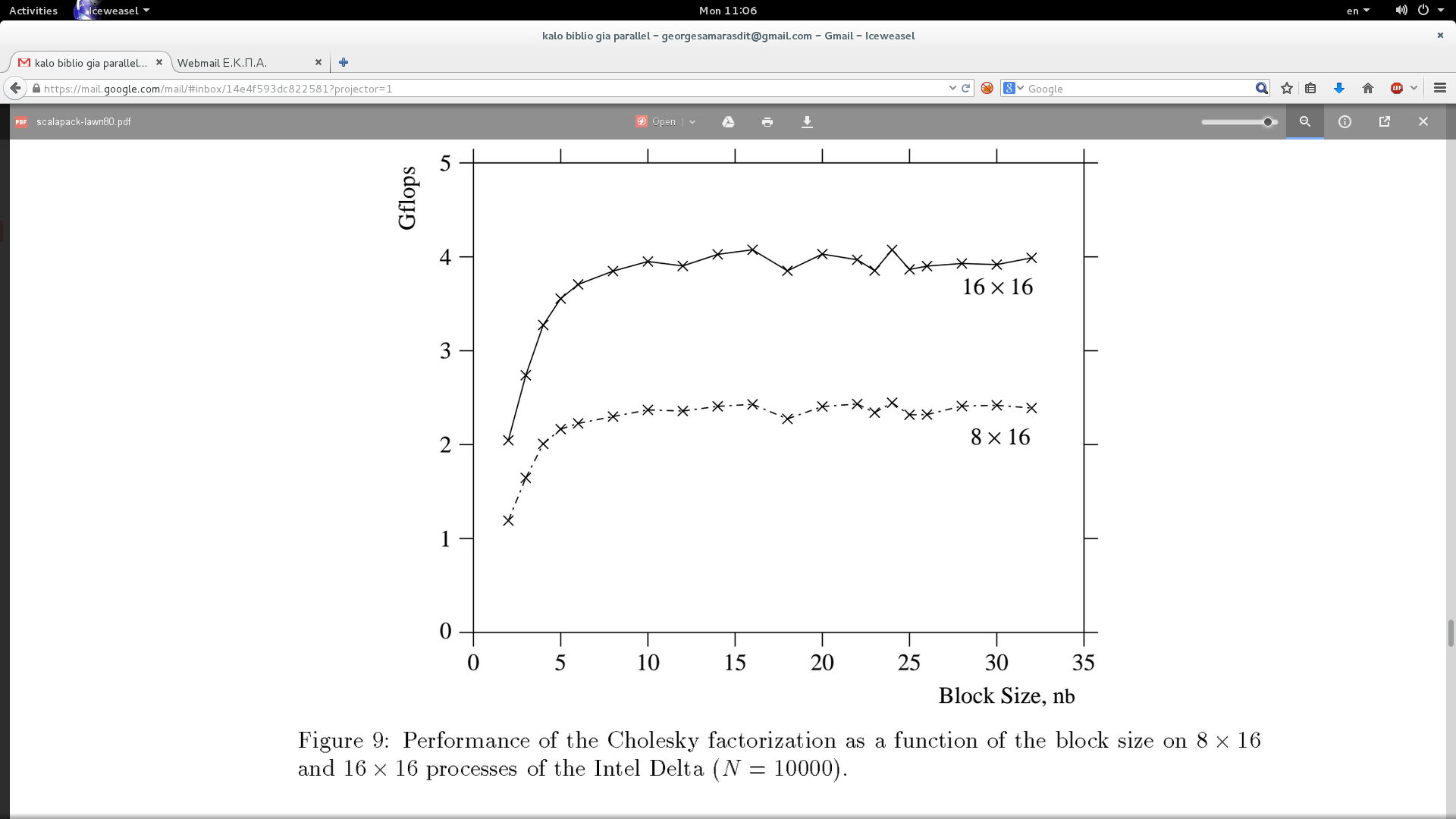{kind=link}
(the higher the better)
In overwhelming majority of cases you can stop with NB=16 and do not have to try greater NB
thanks
Ying
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Ying,
Aleksandr is right. My experiments confirm that multiplies of 4 of 8 are working good. Your figure states that Nb = 16 is the optimal. That may be the case in general cases. However, in my specific problem, the optimal Nb seems to be close to 100. However, sizes near to what you suggested seem to work good too. So, further experimenting than Nb = 16 might be a good thing. I mean, just put a loop in a script and execute your program many times, then just pick the best.
Thanks for the info Ying and Aleksandr,
George
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page