- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I'm trying to do some optimization on a NUMA system at the moment and have run into trouble with regards to thread affinity.
The essence of the code I'm using can be seen below:
success = SETENVQQ("OMP_PLACES={0,1,2,3,4,5,6,7},{8,9,10,11,12,13,14,15},{16,17,18,19,20,21,22,23},{24,25,26,27,28,29,30,31},{32,33,34,35,36,37,38,39},{40,41,42,43,44,45,46,47},{48,49,50,51,52,53,54,55},{56,57,58,59,60,61,62,63}")
NUMA=4
ThreadsPrNuma=2
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
call omp_set_num_threads(NUMA)
call mkl_set_num_threads(NUMA)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(k) proc_bind(spread)
!$OMP DO SCHEDULE(STATIC)
do k=1,NUMA
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(i) proc_bind(master)
!$OMP END PARALLEL
call omp_set_num_threads(ThreadsPrNuma)
call mkl_set_num_threads(ThreadsPrNuma)
call MKL_routine_to_run_parallel_on_each_NUMA_node()
end do
!$OMP END DO
!$OMP END PARALLEL
So the idea is that I have I want to do an outer paralization over each NUMA node - proc_bind(spread).
And then I want each of these threads to have an inner paralization over the number of processors in that NUMA node, the problem is that the MKL routine doesn't seem to be respecting the proc_bind(master) I set.
Anyone got any idea how to do such a thing?
Cheers
Tue
Link Copied
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I don't have answers to all parts of the question nor do I understand entirely your intent.
The set_num_threads calls in the inner loop could take effect only when a new parallel region is set up. perhaps you mean something like parallel num_threads.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What you are is having MKL spawn a different thread team for each of your parallel threads. MKL is not set up to handle this.
You may be better off structuring your OpenMP code to be NUMA aware (known subsets of threads run on each node), then have each thread call the single threaded MKL.
The alternate way to handle this is to make a hybrid program out of MPI and OpenMP (or just MPI). And partition your MPI ranks by NUMA node, each rank process to run the MKL parallel library.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi - Tues supervisor joining the discussion here ...
What Tue wants to obtain is NUMA aware parallel matrix multiplication of two very large matrices using all processors of a single 4 socket shared memory system. His code is parallelized using OpenMP only and using MPI is not an option. We have been unable to find code that will do this for us, so we want to make our own implementation using MKL routines for the core of the computations.
We have initialized the matrices using the first touch principle up front, so they are partitioned in blocks that are distributed across the available NUMA nodes. The idea is then to perform the actual matrix multiplication of the blocks belonging to each NUMA node using the parallel MKL routines with all available threads on that NUMA node. Using sequential MKL would not be efficient for what we are trying to accomplish, since a sum reduction over the results of the blocks is required in the end. This means that the blocks to be multiplied have to be as large as possible in order to ammortize the sum reductions, ie. multiplication scales as N^3 whereas summation as N^2.
We have another use case where we want to accomplish the exact same thing. This part of the code solves large sparse linear systems for a range of differences frequencies, with the linear systems being of a size so big that we can not solve a system per. processor but rather a system per. NUMA node. So in the case of a 4 NUMA node system we want to solve 4 linear systems at a time using nested parallelization, where the outer parallel region distributes the workload over NUMA nodes and parallel pardiso does the inner work using all available threads of each NUMA node. The problem, in its essence, is that we cannot figure out how to control the thread affinity of parallel MKL when the call is made inside a parallel region ...
Hope this clarifies what we are trying to accomplish ...?
Best regards,
C
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I understand what you want to do. The problem you are facing is undefined behavior for undefined setup. You may be able to get what you want by running a few test scenarios. While these might be able to work with your current versions, this my change with future versions.
============ Scenario 1================
Under the assumption (requirement) that the multi-threaded MKL instantiates its own thread pool within the context of the calling thread:
OMP_NESTED=false
MKL_DYNAMIC=false
set number of threads for the first parallel region to number of NUMA nodes
issue a static parallel for loop for number of NUMA nodes number of iterations (or use parallel sections or task)
Now set the affinity of the thread to the node of interest (all the logical processors of that node).
Use mkl_set_num_threads_local(yourChoiceForNode)
Make a innocuous MKL call that you are certain it will use all the threads you specified.
exit the parallel region.
Note, each of these initial outer most level threads, and only these threads, run in subsequent parallel regions to call MKL
======= Scenario 2 =============================
Under the assumption (requirement) that the multi-threaded MKL extends the OpenMP threaded thread pool within the context of the calling thread:
OMP_NESTED=true
MKL_DYNAMIC=false
set number of threads for the first parallel region to number of NUMA nodes
issue a static parallel for loop for number of NUMA nodes number of iterations (or use parallel sections or task)
Now set the affinity of the thread to the node of interest (all the logical processors of that node).
Use mkl_set_num_threads_local(yourChoiceForNode)
Make a innocuous MKL call that you are certain it will use all the threads you specified.
exit the parallel region.
Note, each of these initial outer most level threads, and only these threads, run in subsequent parallel regions to call MKL
=====================
You may need to experiment with MKL_DYNAMIC. Different sections of the users guide seem to contradict each other.
Tim may have had some experience with this.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the answer Jim.
There is one thing you said which baffles me, namely the following:
Now set the affinity of the thread to the node of interest (all the logical processors of that node).
I didn't think it was possible to set/change the affinity after it has first been defined? So how would you go about setting it in the middle of a parallel loop?
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
You can call the pthread functions (or Windows API functions) to set thread affinity. You would do this for an OpenMP program configured to run without affinity pinning.
However, OpenMP 4 has features that aid in doing this without relying on affinity pinning by hand.
The fundamental issue to work around is MKL (can) instantiate a thread pool of its own constricted to the logical processors permitted by the calling thread. If you structure your OpenMP thread affinities to groups for NUMA nodes (or sockets), then you would also want to structure your OpenMP code such that only one thread, and the same thread each time, makes the MKL call while the other threads of the sub-team of the NUMA node are suspended. This may require manipulating OMP_BLOCKTIME or inserting a rather odd looking parallel region.
DO i = 1, nNodes NodeDone(i) = .false. END DO !$OMP PARALLEL ... iThread = omp_get_thread_num() iNode = YourRoutineToGetNUMAnode(iThread) iThreadInNode = YourRoutineToGetTeamMemberNumberInNUMANode(iThread) if(iThreadInNode == 0) then call MKL_routine(...) NodeDone(iNode+1) = .true. else DO WHILE(.NOT.NodeDone(iNode+1)) CALL SLEEPQQ(0) ! release time slice END DO endif !$OMP END PARALLEL
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi again
We have tried implementing a mock up of the code suggestion you mentioned in the previous post, but it does not seem to work. In the code below we try to perform a parallel DGEMM MKL operation pr. socket and we write out the thread pinning to screen using the verbose option in KMP_AFFINITY.
As you can see from running the program and the log below (from testmode=2) we have threads spanning multiple sockets, where we would like them to stay on the same socket. We have introduced modes that can be toggled by setting Runmode in the start of the program. Neither of the approaches works :-(
Any further help in getting this resolved will be greatly appreciated ...
GetLogicalProcessorInformation results:
Number of NUMA nodes: 2
Number of physical processor packages: 2
Number of processor cores: 8
Number of logical processors: 16
Number of processor L1/L2/L3 caches: 16 8 2
OMP: Info #204: KMP_AFFINITY: decoding x2APIC ids.
OMP: Info #202: KMP_AFFINITY: Affinity capable, using global cpuid leaf 11 info
OMP: Info #154: KMP_AFFINITY: Initial OS proc set respected: {0,1,2,3,4,5,6,7,8,
9,10,11,12,13,14,15}
OMP: Info #156: KMP_AFFINITY: 16 available OS procs
OMP: Info #157: KMP_AFFINITY: Uniform topology
OMP: Info #179: KMP_AFFINITY: 2 packages x 4 cores/pkg x 2 threads/core (8 total
cores)
OMP: Info #206: KMP_AFFINITY: OS proc to physical thread map:
OMP: Info #171: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 1 maps to package 0 core 0 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 2 maps to package 0 core 1 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 3 maps to package 0 core 1 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 4 maps to package 0 core 2 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 5 maps to package 0 core 2 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 6 maps to package 0 core 3 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 7 maps to package 0 core 3 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 8 maps to package 1 core 0 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 9 maps to package 1 core 0 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 10 maps to package 1 core 1 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 11 maps to package 1 core 1 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 12 maps to package 1 core 2 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 13 maps to package 1 core 2 thread 1
OMP: Info #171: KMP_AFFINITY: OS proc 14 maps to package 1 core 3 thread 0
OMP: Info #171: KMP_AFFINITY: OS proc 15 maps to package 1 core 3 thread 1
OMP: Info #242: KMP_AFFINITY: pid 12500 thread 0 bound to OS proc set {0,1,2,3,4
,5,6,7}
OMP: Info #242: KMP_AFFINITY: pid 12500 thread 1 bound to OS proc set {8,9,10,11
,12,13,14,15}
Thread binding for socket = 0
OMP: Info #242: KMP_AFFINITY: pid 12500 thread 2 bound to OS proc set {0,1,2,3,4
,5,6,7}
OMP: Info #242: KMP_AFFINITY: pid 12500 thread 3 bound to OS proc set {8,9,10,11
,12,13,14,15}
OMP: Info #242: KMP_AFFINITY: pid 12500 thread 4 bound to OS proc set {0,1,2,3,4
,5,6,7}
Thread binding for socket= 1
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
Runmode=2
if (RunMode==1) then
success = SETENVQQ("KMP_AFFINITY=verbose,compact")
else if (RunMode==2) then
success=SETENVQQ("KMP_AFFINITY=verbose,granularity=fine,proclist=[{0,1,2,3,4,5,6,7},{8,9,10,11,12,13,14,15}],explicit")
end if
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
if (Runmode==1) then
!Test case 1 - we use all available threads on each package and call the MKL only using the very first thread on each package.
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
allocate(NumaNodeDone(processorPackageCount))
NumaNodeDone(:)=.False.
!Outer parallel region. This region only does work for the first thread on a processor package.
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID)
threadID=omp_get_thread_num()
NumaID=floor(1d0*threadID/(logicalProcessorCount/processorPackageCount))+1
!Figure out whether we are the first thread on a processor package - only the first thread should call the mkl
if ((mod(threadID,logicalProcessorCount/processorPackageCount).eq.0).and.(1d0*threadID/(logicalProcessorCount/processorPackageCount).lt.NoNUMANodes)) then
!Print out verbose thread binding information inside a critical section, we can see what the MKL is actually binding to ...
!$OMP CRITICAL
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
NumaNodeDone(NumaID)=.true.
!$OMP END CRITICAL
end if
!$OMP END PARALLEL
else if (RunMode==2) then
!Test case 2 - we spawn only one thread per package using the spread processor binding and call the mkl for each of these threads.
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!Outer parallel region. This region only does work for the first thread on a processor package.
call omp_set_num_threads(NoNumaNodes)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) PROC_BIND(SPREAD)
!$OMP CRITICAL
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
!$OMP END CRITICAL
!$OMP END PARALLEL
end if
end program NumaAwareDGEMM
subroutine GetMachineArch(numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount,processorCacheCount )
use, intrinsic :: ISO_C_BINDING
use kernel32
implicit none
integer,intent(out) :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3),intent(out) :: processorCacheCount
! Variables
procedure(GetLogicalProcessorInformation), pointer :: glpi
type(T_SYSTEM_LOGICAL_PROCESSOR_INFORMATION), allocatable, dimension(:) :: buffer
integer(DWORD) :: returnLength = 0
integer(DWORD) :: ret
integer :: nlpi, lpi_element_length, i
processorCacheCount=0
numaNodeCount = 0
processorCoreCount = 0
logicalProcessorCount = 0
processorPackageCount = 0
call c_f_procpointer( &
transfer( &
GetProcAddress( &
GetModuleHandle("kernel32"//C_NULL_CHAR), &
"GetLogicalProcessorInformation"//C_NULL_CHAR &
), &
C_NULL_FUNPTR &
), &
glpi)
if (.not. associated(glpi)) then
print *,"GetLogicalProcessorInformation not supported"
error stop
end if
! We don't know in advance the size of the buffer we need. We'll pick a number, allocate it,
! and see if that's sufficient. If not, we'll use the returned size information and reallocate
! the buffer to the required size.
allocate (buffer(20))
lpi_element_length = C_SIZEOF(buffer(1))
returnLength = C_SIZEOF(buffer)
ret = glpi(buffer, returnLength)
if (ret == FALSE) then ! Failed
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) then
deallocate (buffer)
allocate (buffer(returnLength/lpi_element_length))
ret = glpi(buffer, returnLength)
if (ret == FALSE) then
print *,"GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
else
print *, "GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
end if
! Now we can iterate through the elements of buffer and see what we can see
do i=1, returnLength / lpi_element_length ! Number of elements in buffer
select case (buffer(i)%Relationship)
case(RelationNumaNode)
! NUMA nodes return one record of this type
numaNodeCount = numaNodeCount + 1
case(RelationProcessorCore)
processorCoreCount = processorCoreCount + 1
! A Hyperthreaded core supplies more than one logical processor
logicalProcessorCount = logicalProcessorCount + popcnt(buffer(i)%processorMask)
case(RelationCache)
! One cache descriptor for each cache
if (buffer(i)%Cache%Level > 0 .and. buffer(i)%Cache%Level <= 3) then
processorCacheCount(buffer(i)%Cache%Level) = processorCacheCount(buffer(i)%Cache%Level) + 1
else
print *,"Invalid processor cache level ", buffer(i)%Cache%Level
end if
case(RelationProcessorPackage)
!Logical processors share a physical package (socket)
processorPackageCount = processorPackageCount + 1
case default
print *, "Unrecognized relationship code ", buffer(i)%Relationship
end select
end do
if(allocated(buffer)) deallocate(buffer)
print*,"GetLogicalProcessorInformation results:"
print*, " Number of NUMA nodes: ", numaNodeCount
print*, " Number of physical processor packages: ", processorPackageCount
print*, " Number of processor cores: ", processorCoreCount
print*, " Number of logical processors: ", logicalProcessorCount
print*, " Number of processor L1/L2/L3 caches: ",processorCacheCount
end subroutine GetMachineArch
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
In case this is part of the issue, mkl by default will spread out at 1 thread per core, since 2 threads per core will degrade performance, even under hyperthreading. Mkl can run a single 16 thread instance quite efficiently across 2 8 core cpus (or 8 threads on 2 4 core cpus) so you may have much work to accomplish to break even with your numa scheme.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Tue B.,
Try this:
else if (RunMode==2) then
! once only code performed to initialize MKL thread pools
!Test case 2 - we spawn only one thread per package using the spread processor binding and call the mkl for each of these threads.
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
! *** Set OMP_PLACES to that desired for the application OpenMP threads
! *** Application OpenMP (outer most level) threads 0, 1, 2, ... sequence on nodes 0, 1, 2, ... wrap, o, 1, 2, ...
! *** Do this prior to first parallel region (of user application) ***
! *** and before first MKL call ***
! the following is "hard wired" you will want to build the string after your survey
success = SETENVQQ("OMP_PLACES={0:8},{9:8},{0:8},{9:8},{0:8},{9:8},{0:8},{9:8},{0:8},{9:8},{0:8},{9:8},{0:8},{9:8},{0:8},{9:8}"
! Instantiate the application first level OpenMP thread pool
call omp_set_num_threads(logicalProcessorCount)
!$OMP PARALLEL
if(omp_get_thread_num() .lt. 0) stop ! innocuous statument with test that won't fail
!$OMP END PARALLEL
! At this point the application first level thread pool is established
! Now initialize the MKL OpenMP thread pools (MKL will do this on first call)
! This too is performed once onl
!Requires that outer most level OpenMP thread numbers 0:NiNumaNodes-1 reside on different nodes
call omp_set_num_threads(NoNumaNodes)
! note, outer level application thread pool is already established
! no requirement for PROC_BIND(SPREAD) on following statement
! Once only parallel region to establish MKL thread pools
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID)
!$OMP CRITICAL
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
if(threadID == 0) success = SETENVQQ("OMP_PLACES=0:8")
if(threadID == 1) success = SETENVQQ("OMP_PLACES=9:8")
if(threadID > 1) stop "fix code)
! Make an MKL call that you know will use ThreadsPrNuma number of threads
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
!$OMP END CRITICAL
!$OMP END PARALLEL
! At this point, the MKL thread pools are established...
! *** for the first application OpenMP thread on the NUMA node
! *** These threads, and only these threads shall be the only application threads permitted to call MKL
end if ! end of once-only setup
...
! application use
! this is running in the application serial section
!
!Outer parallel region. This region only does work for the first thread on a processor package.
!Requires that outer most level OpenMP thread numbers 0:NiNumaNodes-1 reside on different nodes
call omp_set_num_threads(NoNumaNodes)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(T0,threadID,NumaID,ii)
T0 = omp_get_wtime()
threadID=omp_get_thread_num()
! obtain Node's blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize
! The following should not be necessary, uncomment if oversubscription occurs
! ii=mkl_set_num_threads_local(ThreadsPrNuma)
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
T0 = omp_get_wtime()
!$OMP CRITICAL
PRINT *,'runtime Node ',threadID, ' ', T0
!$OMP END CRITICAL
!$OMP END PARALLEL
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thank you so much Jim!
The key point that we were missing was the fact that you can set OMP_places dynamically and not just in the beginning of a program like you have to do with MKL_affinity. With your suggestion I was able to make a numa-aware MKL program.
For anyone else that may be interested, this is the program that ended up working for me:
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode,t0
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
success=SETENVQQ("OMP_PLACES={0:8},{8:8}")
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!Outer parallel region. This region only does work for the first thread on a processor package.
call omp_set_num_threads(NoNumaNodes)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) PROC_BIND(SPREAD)
!!$OMP CRITICAL
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
if(threadID == 0) then
success = SETENVQQ("OMP_PLACES=0:8")
else if(threadID == 1) then
success = SETENVQQ("OMP_PLACES=8:8")
else
stop
end if
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
!!$OMP END CRITICAL
!$OMP END PARALLEL
end program NumaAwareDGEMM
subroutine GetMachineArch(numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount,processorCacheCount )
use, intrinsic :: ISO_C_BINDING
use kernel32
implicit none
integer,intent(out) :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3),intent(out) :: processorCacheCount
! Variables
procedure(GetLogicalProcessorInformation), pointer :: glpi
type(T_SYSTEM_LOGICAL_PROCESSOR_INFORMATION), allocatable, dimension(:) :: buffer
integer(DWORD) :: returnLength = 0
integer(DWORD) :: ret
integer :: nlpi, lpi_element_length, i
processorCacheCount=0
numaNodeCount = 0
processorCoreCount = 0
logicalProcessorCount = 0
processorPackageCount = 0
call c_f_procpointer( &
transfer( &
GetProcAddress( &
GetModuleHandle("kernel32"//C_NULL_CHAR), &
"GetLogicalProcessorInformation"//C_NULL_CHAR &
), &
C_NULL_FUNPTR &
), &
glpi)
if (.not. associated(glpi)) then
print *,"GetLogicalProcessorInformation not supported"
error stop
end if
! We don't know in advance the size of the buffer we need. We'll pick a number, allocate it,
! and see if that's sufficient. If not, we'll use the returned size information and reallocate
! the buffer to the required size.
allocate (buffer(20))
lpi_element_length = C_SIZEOF(buffer(1))
returnLength = C_SIZEOF(buffer)
ret = glpi(buffer, returnLength)
if (ret == FALSE) then ! Failed
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) then
deallocate (buffer)
allocate (buffer(returnLength/lpi_element_length))
ret = glpi(buffer, returnLength)
if (ret == FALSE) then
print *,"GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
else
print *, "GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
end if
! Now we can iterate through the elements of buffer and see what we can see
do i=1, returnLength / lpi_element_length ! Number of elements in buffer
select case (buffer(i)%Relationship)
case(RelationNumaNode)
! NUMA nodes return one record of this type
numaNodeCount = numaNodeCount + 1
case(RelationProcessorCore)
processorCoreCount = processorCoreCount + 1
! A Hyperthreaded core supplies more than one logical processor
logicalProcessorCount = logicalProcessorCount + popcnt(buffer(i)%processorMask)
case(RelationCache)
! One cache descriptor for each cache
if (buffer(i)%Cache%Level > 0 .and. buffer(i)%Cache%Level <= 3) then
processorCacheCount(buffer(i)%Cache%Level) = processorCacheCount(buffer(i)%Cache%Level) + 1
else
print *,"Invalid processor cache level ", buffer(i)%Cache%Level
end if
case(RelationProcessorPackage)
!Logical processors share a physical package (socket)
processorPackageCount = processorPackageCount + 1
case default
print *, "Unrecognized relationship code ", buffer(i)%Relationship
end select
end do
if(allocated(buffer)) deallocate(buffer)
print*,"GetLogicalProcessorInformation results:"
print*, " Number of NUMA nodes: ", numaNodeCount
print*, " Number of physical processor packages: ", processorPackageCount
print*, " Number of processor cores: ", processorCoreCount
print*, " Number of logical processors: ", logicalProcessorCount
print*, " Number of processor L1/L2/L3 caches: ",processorCacheCount
end subroutine GetMachineArch
Cheers guys!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
YEA!!!
I knew with a little bit of finagling we could do it. I retired my NUMA machine about 10 years ago, so I couldn't actually test my suggestions. Thanks for hanging in there, and for posting the cleaned up solution.
The next thing you should consider doing is to modifying your initialization routine to use the results of your GetMachineArch to produce the text strings for the SETENVQQ. Then you will be ready for your next system.
Setting the initialization technique aside....
Do you have some results data from your application runs using NUMA node distributed MKL thread pools?
It would be comforting to know the effort was worthwhile.
One other issue you will have to address in your application which is addressed in my #7 post above. This is the "spin wait" time of the application threads that are not the "NUMA node master" thread. While you could set OMP_BLOCKTIME to 0, it may be more beneficial to keep a reasonable number and use the odd looking parallel region with SLEEPQQ for the non node master threads. Experimentation will guide you as to the result to take.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I will certainly post some performance results once I have them. For now I'm running into another problem namely that the affinity seems to fail the second time the paralization is called - if for instance I throw a do loop around the outer parallel region the affinity is fine in the first iteration, but the second one strange things happen, anyway I will investigate further this week.
I'll return once I either have a solution or a concrete question.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
It might help to display the thread ID prior to each MKL call. This is not the omp_get_thread_num.
Your DO loops (that call MKL) will need to be outer most nest level and use static scheduling such that the same thread ID'd thread gets the same slice of the work.
Jim
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I thought omp_get_thread_num would get the thread ID?, what command should I then use instead?
In any case I have isolated something which I can only interpret as a bug in the compiler. In the following I have the working numa-aware code which works. But as soon as you turn on the outer do loop I have currently commented out, the whole affinity setup stops working even on the first iteration which should clearly be identical.
Can anyone at Intel tell me what is happening here?
Cheers
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode,t0
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
success=SETENVQQ("OMP_PLACES={0:8},{8:8}")
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!Outer parallel region. This region only does work for the first thread on a processor package.
call omp_set_num_threads(NoNumaNodes)
! do i=1,3 !When activating this do loop the affinity of the program get's completely destroyed, even on the first iteration, which for all purposes should be identical to commenting it out
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) PROC_BIND(SPREAD)
!!$OMP CRITICAL
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
if(threadID == 0) then
success = SETENVQQ("OMP_PLACES=0:8")
else if(threadID == 1) then
success = SETENVQQ("OMP_PLACES=8:8")
else
stop
end if
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
!!$OMP END CRITICAL
!$OMP END PARALLEL
! end do
end program NumaAwareDGEMM
subroutine GetMachineArch(numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount,processorCacheCount )
use, intrinsic :: ISO_C_BINDING
use kernel32
implicit none
integer,intent(out) :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3),intent(out) :: processorCacheCount
! Variables
procedure(GetLogicalProcessorInformation), pointer :: glpi
type(T_SYSTEM_LOGICAL_PROCESSOR_INFORMATION), allocatable, dimension(:) :: buffer
integer(DWORD) :: returnLength = 0
integer(DWORD) :: ret
integer :: nlpi, lpi_element_length, i
processorCacheCount=0
numaNodeCount = 0
processorCoreCount = 0
logicalProcessorCount = 0
processorPackageCount = 0
call c_f_procpointer( &
transfer( &
GetProcAddress( &
GetModuleHandle("kernel32"//C_NULL_CHAR), &
"GetLogicalProcessorInformation"//C_NULL_CHAR &
), &
C_NULL_FUNPTR &
), &
glpi)
if (.not. associated(glpi)) then
print *,"GetLogicalProcessorInformation not supported"
error stop
end if
! We don't know in advance the size of the buffer we need. We'll pick a number, allocate it,
! and see if that's sufficient. If not, we'll use the returned size information and reallocate
! the buffer to the required size.
allocate (buffer(20))
lpi_element_length = C_SIZEOF(buffer(1))
returnLength = C_SIZEOF(buffer)
ret = glpi(buffer, returnLength)
if (ret == FALSE) then ! Failed
if (GetLastError() == ERROR_INSUFFICIENT_BUFFER) then
deallocate (buffer)
allocate (buffer(returnLength/lpi_element_length))
ret = glpi(buffer, returnLength)
if (ret == FALSE) then
print *,"GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
else
print *, "GetLogicalProcessorInformation call failed with error code ", GetLastError()
error stop
end if
end if
! Now we can iterate through the elements of buffer and see what we can see
do i=1, returnLength / lpi_element_length ! Number of elements in buffer
select case (buffer(i)%Relationship)
case(RelationNumaNode)
! NUMA nodes return one record of this type
numaNodeCount = numaNodeCount + 1
case(RelationProcessorCore)
processorCoreCount = processorCoreCount + 1
! A Hyperthreaded core supplies more than one logical processor
logicalProcessorCount = logicalProcessorCount + popcnt(buffer(i)%processorMask)
case(RelationCache)
! One cache descriptor for each cache
if (buffer(i)%Cache%Level > 0 .and. buffer(i)%Cache%Level <= 3) then
processorCacheCount(buffer(i)%Cache%Level) = processorCacheCount(buffer(i)%Cache%Level) + 1
else
print *,"Invalid processor cache level ", buffer(i)%Cache%Level
end if
case(RelationProcessorPackage)
!Logical processors share a physical package (socket)
processorPackageCount = processorPackageCount + 1
case default
print *, "Unrecognized relationship code ", buffer(i)%Relationship
end select
end do
if(allocated(buffer)) deallocate(buffer)
print*,"GetLogicalProcessorInformation results:"
print*, " Number of NUMA nodes: ", numaNodeCount
print*, " Number of physical processor packages: ", processorPackageCount
print*, " Number of processor cores: ", processorCoreCount
print*, " Number of logical processors: ", logicalProcessorCount
print*, " Number of processor L1/L2/L3 caches: ",processorCacheCount
end subroutine GetMachineArch
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
omp_get_thread_num() returns the team member number for the current parallel region. This is a zero-based number. Each nest level (when using nested parallel regions) constructs 0-based team member numbers. E.g.if thread team member number 3 of outer most parallel regions enters a (nested) parallel region, its team member number for that region becomes 0 and its other team member numbers are numbered 1, 2, 3,... additionally these team member threads are a thread pool bound to the outer level thread 3 team member and are not to be confused with same numbered team member numbers of different thread teams.
From the serial portion of the program "vanilla" flavored parallel regions will generate a team who's team member numbers consistently map to the same software thread (depending on affinity settings this thread may or may not move about). When you use other "flavors" of parallel regions (proc_bind(), or other team selecting clauses) then the thread team member numbers might not align with the thread ID's of prior calls.
A portable method for you to consider is to declare a thread local variable, call it iThread or whatever. Have the global initialization to -1 (such that you can tell if it has not been initialized), then at the program start, create a parallel region using all threads, and have each thread insert the omp_get_thread_num() value into iThread. Then later, on subsequent usage iThread will either hold the initial thread number (shouldn't change, but if it does, you can figure out why), or -1 in the event that you inadvertently call from a nested region. In addition to iThread thread local variable, you might consider adding isMKLcallingThread, initialized to .false. and overwritten to .true. for those threads assuming the master roll for each NUMA node. And optionally NUMAnode.
What this does is avoid issues of NUMAnode(omp_get_thread_num()) where you may have nested or multiple thread teams, each with thread team member numbers 0, 1, ...
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Try this:
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode,t0
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
success=SETENVQQ("OMP_PLACES={0:8},{8:8}")
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!Outer parallel region. This region only does work for the first thread on a processor package.
call omp_set_num_threads(NoNumaNodes)
! **** remove PROC_BIND(SPREAD)
! **** remove your test DO loop, the following is initialization of MKL thread teams
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID)
!!$OMP CRITICAL
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',threadID
ii=mkl_set_num_threads_local(ThreadsPrNuma)
if(threadID == 0) then
success = SETENVQQ("OMP_PLACES=0:8")
else if(threadID == 1) then
success = SETENVQQ("OMP_PLACES=8:8")
else
stop
end if
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
!!$OMP END CRITICAL
!$OMP END PARALLEL
! *** end once only initialization
!============= initialization complete ===================
! ... code in your application
do i=1,3
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) ! all threads scheduled
threadID=omp_get_thread_num()
if(threadID == 0) then
! calculate tile for thread 0
! blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
else if(threadID == 1) then
! calculate tile for thread 1
! blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
else
SleepQQ(0) ! release timeslice for MKL pool
end if
! using above calculated tile
!$OMP END PARALLEL
! end do
end program NumaAwareDGEMM
Notes:
Only initialize the MKL thread pools once. Your DO loop was configured to initialize multiple times (may have been the mkl_set_num_threads_local that reinitialized the MKL tread pool).
In the above DO loop, all threads are scheduled such that you can perform a SleepQQ(0) to release (potentially) Spin-Waiting threads. Depending on the time of the MKL call, one SleepQQ might not be sufficient. Consider adding MKLbusy flags:
do i=1,3
MKLbusy = .true. !
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) ! all threads scheduled
threadID=omp_get_thread_num()
if(threadID == 0) then
! calculate tile for thread 0
! blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
MKLbusy (threadID+1) = .false.
else if(threadID == 1) then
! calculate tile for thread 1
! blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
MKLbusy (threadID+1) = .false.
else
DO while(any(MKLbusy(1:NoNUMANodes))
SleepQQ(0) ! release timeslice for MKL pool
END DO
end if
! using above calculated tile
!$OMP END PARALLEL
! end do
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Jim I have tried the cases you posted, with no luck unfortunately, the affinity is still messed up in anything but the first region.
I incorporated a globalthreadID based on your suggestion, as you can see in the following example. But I still haven't gotten any nearer to cracking this problem.
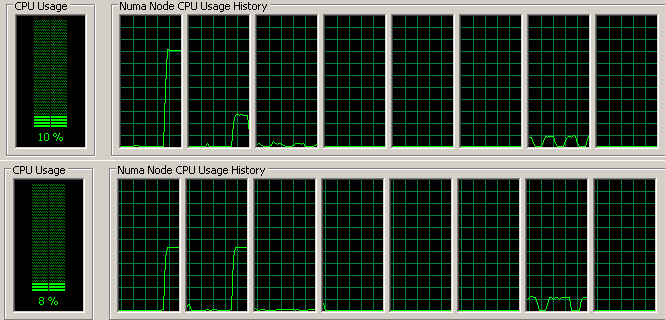
I always get the right affinity in the first parallel region in my program, but in all subsequent regions the affinity is completely different. In the example this is clearly illustrated by the initial parallel region, which does nothing except setting a GlobalThreadID in order to keep track of my threads, whenever I comment this region out, the next region runs with the correct affinity but with it in the affinity gets all messed up. I have added a picture of my CPU use during this run, both with the region commented out and active.
A few things to notice:
The threadID does match the globalthreadID I set in the initial region, so that can't be the problem.
Since I never even call the mkl_set_num_threads_local() in this initialization region I guess the problem can't be me overwriting the mklthreadpool either?
I'm starting to run out of ideas about what to do here, you got any more ideas Jim?
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode,t0
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
integer, allocatable,dimension(:) :: GlobalThreadID
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone,MKlbusy
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
success=SETENVQQ("OMP_PLACES={0:8},{8:8}")
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
allocate(GlobalThreadID(NoNumanodes*ThreadsPrNuma))
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!With this region active the affinity in the second parallel region is destroyed
!This region spawns the threadpool with all the threads we want to use in this run.
call omp_set_num_threads(NoNumaNodes*ThreadsPrNuma)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(i)
!$OMP DO SCHEDULE(STATIC)
do i = 1,NoNumanodes*ThreadsPrNuma
GlobalThreadID(i)=omp_get_thread_num()
end do
!$OMP END DO
!$OMP END PARALLEL
!If the above region is commented out this region has the right affinity (any region following this one will have the wrong affinity though)
call omp_set_num_threads(NoNumaNodes)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID)
!$OMP DO SCHEDULE(STATIC)
do i = 1,NoNumanodes
ThreadID=omp_get_thread_num()
print *,'Thread binding for socket=',ThreadID,GlobalThreadID(i)
if(ThreadID == 0) then
success = SETENVQQ("OMP_PLACES=0:8")
else if(ThreadID == 1) then
success = SETENVQQ("OMP_PLACES=8:8")
else
stop
end if
ii=mkl_set_num_threads_local(ThreadsPrNuma)
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
end do
!$OMP END DO
!$OMP END PARALLEL
end program NumaAwareDGEMM
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Go back to my #17 post. Lines 40:54 are used (once) to initialize the MKL thread pools. The initialization includes mkl_set_num_threads_local. The initialization also includes (requires) an innocuous call to MKL that is assured to use all threads (thread count) specified prior to the call. You throw away any results data (or if you want you can keep it).
Subsequent to the above initialization, you make your MKL calls as illustrated by lines 58 to 74 (remove ! on 74) of the first listing, or better yet by lines 1 to 22 (remove ! on 22) of the second listing. These are performed without mkl_set_num_threads or any other control that alters the established thread pool for MKL.
Not mentioned in my 17 post, after establishing (entering) the first parallel region, but prior to initializing the MKL thread pools, experiment with setting KMP_BLOCKTIME=0. Leave outer environment block time alone (typically 200ms). For MKL calls that do not internally use barriers, this setup will return from the MKL call with its threads (other than calling thread) suspended (out of the way of your application threads).
It may have an adverse effect on MKL calls that require barriers and/or multiple parallel regions. Experimentation will inform you as to the best strategy. The KMP_BLOCKTIME setting is used only at initialization of the respective thread pools.
Jim Dempsey
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Okay I think I have done exactly what you suggest now - see my code below. It still doesn't work, but I was able to learn a few new things. First up I learned that threadID=1 works as it is supposed to even after the initial parallel region, the problem is solely in threadID=0 which for some reason spreads out its mkl_thread pool after the initialization where it keeps them all together. Can you think of any reason why thread 0 should be special? (The way I tested it was merely just commenting out the dgemm subroutine in the second parallel region for 1 thread at a time and see how the workload spread across the system).
I also played around with KMP_SET_BLOCKTIME and SleepQQ like you suggested, but to no apparent success.
program NumaAwareDGEMM
use IFPORT
use omp_lib
use mkl_service
implicit none
logical(4) :: Success
integer :: numaNodeCount,processorPackageCount,processorCoreCount,logicalProcessorCount
integer,dimension(3) :: processorCacheCount
integer :: NoNUMANodes, blocksize,nrepeats,Runmode,t0
integer :: N,I,J,NIte, First,Last,k,colidx,error,numofblocks,iii,ii,dim,d,threadID,NumaID
integer :: Iter,Solver,NUMASize,m,ThreadsPrNuma
integer, allocatable,dimension(:) :: GlobalThreadID
real*8,allocatable,dimension(:,:) :: A, B,C,rA,rB,rC,cA,cB,cC,bA,bB,bbc
real*8,allocatable,target :: bC(:,:)
logical, allocatable, dimension(:) :: NumaNodeDone,MKlbusy
!Set the mode to test
call GetMachineArch(numaNodeCount,processorPackageCount,d,logicalProcessorCount,processorCacheCount )
success=SETENVQQ("OMP_PLACES={0:8},{8:8}")
!Create dummy matrices - we just matmul them uninitialized
blocksize=6000
NoNUMANodes=2 !How many NUMA nodes to distribute calculations over
ThreadsPrNuma=4 !How many threads to use pr. numa node
dim=blocksize*NoNUMANodes
allocate(bA(dim,dim))
allocate(bB(dim,dim))
allocate(bC(dim,dim))
allocate(bbc(blocksize,blocksize))
allocate(GlobalThreadID(NoNumanodes*ThreadsPrNuma))
allocate(Mklbusy(NoNumanodes))
call KMP_SET_STACKSIZE_S(990000000)
call omp_set_dynamic(0)
call mkl_set_dynamic(0)
call omp_set_nested(1)
!intialization region
call omp_set_num_threads(NoNumaNodes)
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID)
!$OMP DO SCHEDULE(STATIC)
do i = 1,NoNumanodes
GlobalThreadID(i)=omp_get_thread_num()
print *,'Thread binding for socket=',GlobalThreadID(i)
if(GlobalThreadID(i) == 0) then
success = SETENVQQ("OMP_PLACES=0:8")
else if(GlobalThreadID(i) == 1) then
success = SETENVQQ("OMP_PLACES=8:8")
else
stop
end if
call KMP_SET_BLOCKTIME(0)
ii=mkl_set_num_threads_local(ThreadsPrNuma)
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
end do
!$OMP END DO
!$OMP END PARALLEL
MKLbusy = .true. !
!$OMP PARALLEL DEFAULT(SHARED) PRIVATE(ii,threadID,NumaID) ! all threads scheduled
!$OMP DO SCHEDULE(STATIC)
do i = 1,NoNumanodes
threadID=omp_get_thread_num()
print *,'Thread binding for socket=',GlobalThreadID(i),threadID
if(threadID == 0) then
! calculate tile for thread 0
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
MKLbusy (threadID+1) = .false.
else if(threadID == 1) then
! calculate tile for thread 1
call dgemm('N','N',blocksize,blocksize,blocksize,1.d0,bA,dim,bB,dim,0.d0,bbc,blocksize)
MKLbusy (threadID+1) = .false.
else
DO while(any(MKLbusy(1:NoNUMANodes)))
call SleepQQ(0) ! release timeslice for MKL pool
END DO
end if
end do
!$OMP END DO
!$OMP END PARALLEL
end program NumaAwareDGEMM
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Good detective work.
RE: Peculiarity with outer region thread 0
Not sure, (not privy to internals of OpenMP thread scheduling). This said, your discovery of non-0 (main) thread being sticky, I then suggest you change the means of determining which threads become the "master" thread for the MKL calls from each node.
In your init function, schedule the first parallel region to use +1 thread over NoNumaNodes. This places
Team member 0 on Node 0 (not used as MKL node master)
Team member 1 on Node 1 (used as MKL node master)
Team member 2 on Node 0 (used as MKL node master, assuming your OMP_PLACES or KMP_AFFINITY was initialized properly to wrap)
The MKL node master threads do not include outer team member 0 (app master thread). Now your node partitioning has a unique set of thread (team member numbers from outer region) that does not include the master thread.
Jim Dempsey
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Printer Friendly Page